Python-OpenCV学习(十一)分水岭算法进行图像分割
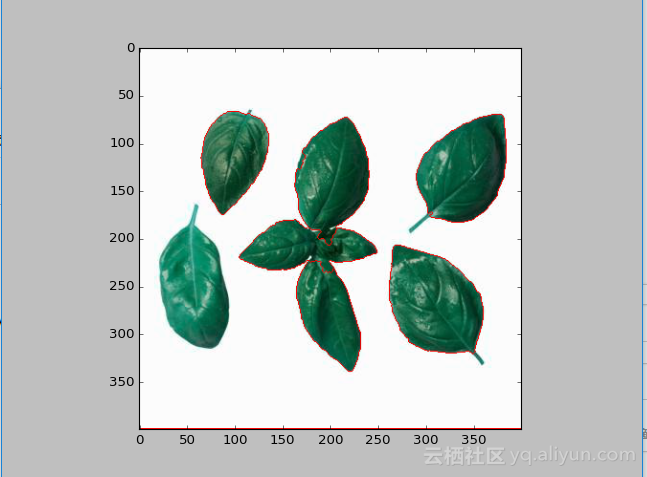
分水岭算法进行图像分割:分水岭分割方法,是一种基于拓扑理论的数学形态学的分割方法,其基本思想是把图像看作是测地学上的拓扑地貌,图像中每一点像素的灰度值表示该点的海拔高度,每一个局部极小值及其影响区域称为集水盆,而集水盆的边界则形成分水岭。分水岭的概念和形成可以通过模拟浸入过程来说明。在每一个局部极小值表面,刺穿一个小孔,然后把整个模型慢慢浸入水中,随着浸入的加深,每一个局部极小值的影响域慢慢向外扩展,在两个集水盆汇合处构筑大坝,即形成分水岭。例子: import numpy as np import cv2 from matplotlib import pyplot as plt img = cv2.imread('basil.jpg') gray = cv2.cvtColor(img,cv2.COLOR_BGR2GRAY) ret, thresh = cv2.threshold(gray,0,255,cv2.THRESH_BINARY_INV+cv2.THRESH_OTSU) # noise removal kernel = np.ones((3,3),np.uint8) opening = cv2.morphologyEx(thresh,cv2.MORPH_OPEN,kernel, iterations = 2) # sure background area sure_bg = cv2.dilate(opening,kernel,iterations=3) # Finding sure foreground area dist_transform = cv2.distanceTransform(opening,cv2.DIST_L2,5) ret, sure_fg = cv2.threshold(dist_transform,0.7*dist_transform.max(),255,0) # Finding unknown region sure_fg = np.uint8(sure_fg) unknown = cv2.subtract(sure_bg,sure_fg) # Marker labelling ret, markers = cv2.connectedComponents(sure_fg) # Add one to all labels so that sure background is not 0, but 1 markers = markers+1 # Now, mark the region of unknown with zero markers[unknown==255] = 0 markers = cv2.watershed(img,markers) img[markers == -1] = [255,0,0] plt.imshow(img) plt.show() 结果:先导入模块加载图像,图像转化为灰度图片: import numpy as np import cv2 from matplotlib import pyplot as plt img = cv2.imread('basil.jpg') gray = cv2.cvtColor(img,cv2.COLOR_BGR2GRAY) 设置一个阈值,将灰度图像分为两部分:黑色部分和白色部分: ret, thresh = cv2.threshold(gray,0,255,cv2.THRESH_BINARY_INV+cv2.THRESH_OTSU) 通过morphologyEx变化来去除噪声数据,是对图像进行膨胀之后再进行腐蚀操作提取图像特征: kernel = np.ones((3,3),np.uint8) opening = cv2.morphologyEx(thresh,cv2.MORPH_OPEN,kernel, iterations = 2) 得到大部分前景:通过distanceTeansform来获取最有可能的前景区域,越是远离背景区域的边界越可能是前景,得到结果后用一个阈值来确定前景: dist_transform = cv2.distanceTransform(opening,cv2.DIST_L2,5) ret, sure_fg = cv2.threshold(dist_transform,0.7*dist_transform.max(),255,0) 接下来确定前景和背景重叠部分: sure_fg = np.uint8(sure_fg) unknown = cv2.subtract(sure_bg,sure_fg) 设定“栅栏”来阻止谁汇聚,通过connected-Components函数完成: ret, markers = cv2.connectedComponents(sure_fg) 在背景区域上加一,将unknown区域设为0: markers = markers+1 markers[unknown==255] = 0 最后通过watershed函数: markers = cv2.watershed(img,markers) img[markers == -1] = [255,0,0]