Jenkins +Gradle实现Android自动化构建(学习笔记三十二)
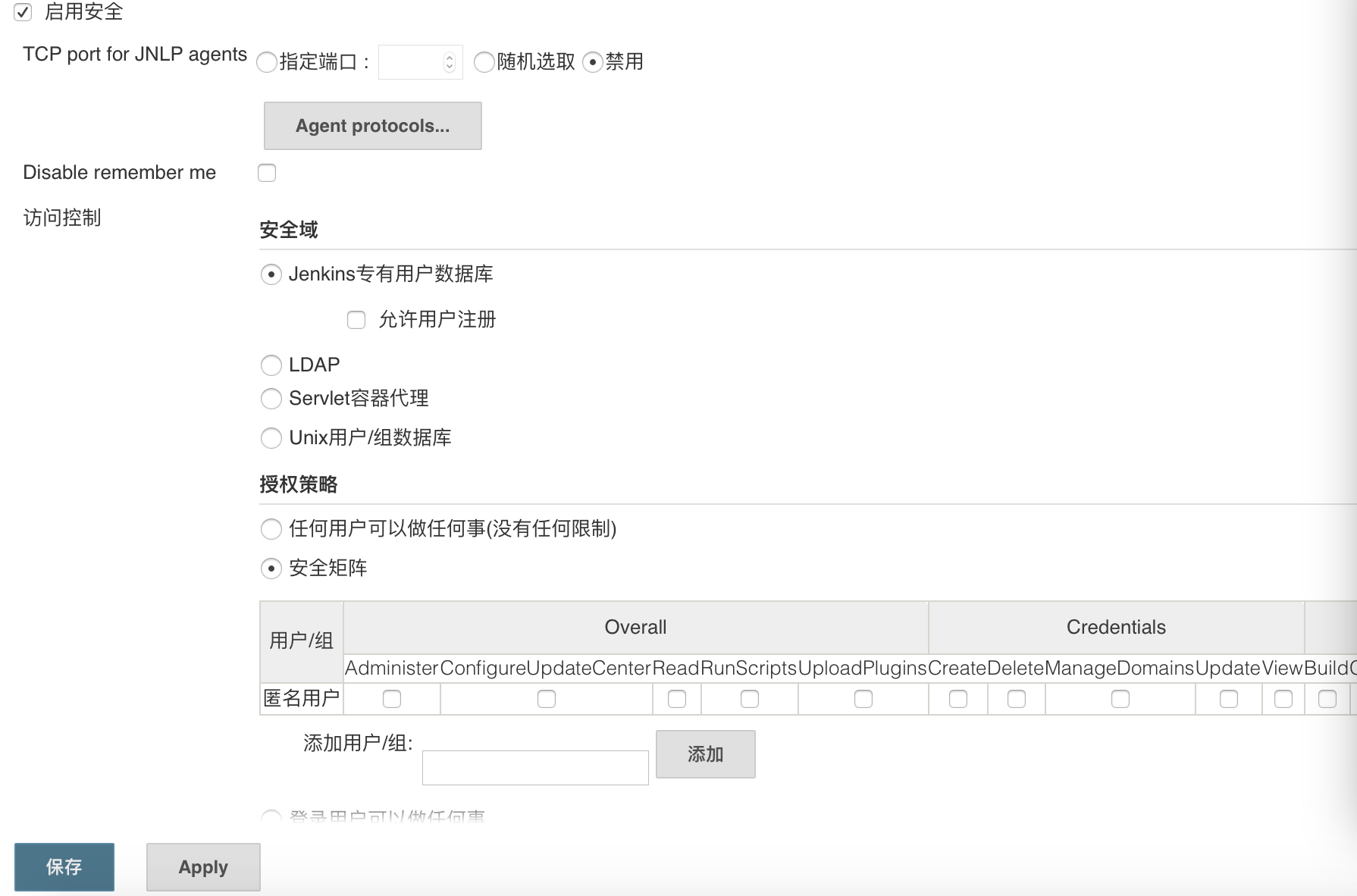
https://blog.csdn.net/mabeijianxi/article/details/52680283 http://www.liuling123.com/2016/10/jenkins-gradle-auto-build.html Jenkins简介 Jenkins是一个开源软件项目,旨在提供一个开放易用的软件平台,使软件的持续集成变成可能。目前大部分公司都在使用Jenkins来持续构建。 Jenkins下载与安装配置 Jenkins下载 安装Jenkins有两种方式: 第一种就是下载安装包直接安装,下载地址:http://mirrors.jenkins-ci.org 第二种就是下载war包,放到Tomcat中启动。war包下载地址:http://mirrors.jenkins-ci.org/war/, 或者http://updates.jenkins-ci.org/download/war/ 这里因为我电脑上面之前装了Tomcat,所以我使用直接下载war包的方式进行安装。 Jenkins安装 将下载的jenkins.war放到Tomcat下的webapps目录下,然后启动Tomcat。在浏览器中访问”Tomcat访问地址/jenkins”即可安装,因为我的Tomcat装在本机,并且端口为8080,所以访问http://localhost:8080/jenkins/即可进行安装。 Jenkins配置 Jenkins安装之后可以进行用户的权限设置、插件的安装等配置。 用户权限设置 系统管理–>Configure Global Security 如下图所示,在此处可以添加、删除用户以及配置用户权限。 插件安装 搭建Android自动化打包环境需要安装Gradle插件,如果使用Git还需要Git的插件,安装Jenkins时默认已经安装了这两个插件。如果没有安装可以进入“系统管理>管理插件”进行插件的安装。 创建Jenkins任务 要想Jenkins能够帮我们自动构建项目,我们需要创建一个任务,并且配置这个任务要它帮我们执行什么操作,以及什么时候执行等。 如上图所示,点击“新建”按钮并且选择“构建一个自由风格的软件项目”,完了之后会进入到任务的配置界面,配置好之后任务会出现在如上图右边的任务列表中。 任务配置 创建一个任务之后,会自动跳转到任务的配置界面对该任务进行配置,大概包括如下配置: 源码管理 构建项目,当然得有代码了。Jenkins支持使用版本控制工具来进行源码管理,比如Git或者SVN。这里我使用的是Git,项目使用的是我的github上面的一个多渠道打包的demo。在Repository URL中输入项目地址,点击Add按钮添加认证信息,然后选择构建的分支,我这里使用的是master分支。 构建触发器 Jenkins支持上图所示的触发时机配置,如果都不选,则为手动构建,需要点击“立即构建”按钮才构建。 Build periodically:周期进行项目构建(它不关心源码是否发生变化); Build when a change is pushed to GItHub:表示只要GitHub上面源码一更新即进行构件; Poll SCM:定时检查源码变更(根据SCM软件的版本号),如果有更新就checkout最新code下来,然后执行构建动作。 Build periodically和Poll SCM都支持日程表的设置,这个与Spring框架中定时器的日程表配置类似,有5个参数: 第一个参数代表的是分钟 minute,取值 0~59; 第二个参数代表的是小时 hour,取值 0~23; 第三个参数代表的是天 day,取值 1~31; 第四个参数代表的是月 month,取值 1~12; 最后一个参数代表的是星期 week,取值 0~7,0 和 7 都是表示星期天。 如: 选择Build periodically并设置日程表为“0 4”,则表示每天凌晨4点构建一次源码。 选择Poll SCM并设置日程表为“ /10”,则表示每10分钟检查一次源码变化,如果有更新才进行构建。 构建工具 因为现在Android项目默认都是使用Gradle来进行构建的,所以在构建中我选择的是Invoke Gradle script。当然你也可以选择其它的构建工具,比如Ant。 选择Invoke Gradle script之后可以选Invoke Gradle和Use Gradle Wrapper,选择Invoke Gradle就是调用本地安装配置好的Gradle,此时需要指定Gradle路径。为了方便所有开发者同意Gradle版本,一般都使用Gradle Wrapper。关于Gradle和Gradlew的区别可以看这篇文章https://www.zybuluo.com/xtccc/note/275168。 Tasks中填上需要执行的gradle的task。上面我填的clean assembleRelease,即执行gradlew clean assembleRelease。 构建后的操作 配置构建后的操作可以让Jenkins在构建完之后执行什么操作,比如邮件通知、构建其它项目等。 这里我配置了Archive the artifacts,在“用于存档的文件”中填写需要存档的文件名,可以使用通配符。比如上面我配置了app/build/outputs/apk/v*.apk,表示疑v开头的apk文件都存档。构建完之后在任务首页可以下载存档的文件。 任务配置完成之后,点击任务首页的“立即构建”按钮,即可开始构建,构建过程首先会将源码下载下来,位于jenkins目录下的workspace中。然后执行配置好的gradle命令,如果使用gradlew,第一次应该会下载gradlew设置的版本的gradle,最后执行构建任务。构建完之后,如下图,可以看到存档的文件,点击即可下载。 附:Android工程build.gradle文件 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 apply plugin:'com.android.application' android { compileSdkVersion23 buildToolsVersion"23.0.2" defaultConfig { applicationId"com.lauren.multichanneldemo" minSdkVersion17 targetSdkVersion23 versionCode1 versionName"1.0" } signingConfigs { release { defliulingStoreFile = System.getenv("LIULING_STORE_FILE") defliulingKeyAlias = System.getenv("LIULING_KEY_ALIAS") defliulingKeyPassword = System.getenv("LIULING_KEY_PASSWORD") defliulingStorePassword = System.getenv("LIULING_STORE_PASSWORD") defisSigning = (liulingStoreFile !=null) && (liulingKeyAlias !=null) && (liulingKeyPassword !=null) && (liulingStorePassword !=null) if(isSigning){ storeFilefile(liulingStoreFile) keyAlias liulingKeyAlias keyPassword liulingKeyPassword storePassword liulingStorePassword }else{ storeFilefile("debug.keystore") keyAlias"AndroidDebugKey" keyPassword"android" storePassword"android" } } debug { storeFilefile("debug.keystore") keyAlias"AndroidDebugKey" keyPassword"android" storePassword"android" } } buildTypes { release { // 不显示Log buildConfigField"boolean","LOG_DEBUG","false" //启用混淆代码的功能 minifyEnabledtrue //压缩对齐生成的apk包 zipAlignEnabledtrue //指定混淆规则,需要压缩优化的混淆要把proguard-android.txt换成proguard-android.txt proguardFiles getDefaultProguardFile('proguard-android.txt'),'proguard-rules.pro' shrinkResourcestrue signingConfig signingConfigs.release//打包命令行:gradlew assembleRelease } debug { signingConfig signingConfigs.debug } } lintOptions { abortOnErrorfalse } // productFlavors { // _91 { // manifestPlaceholders = [MTA_CHANNEL_VALUE: "91"] // } // wandoujia { // manifestPlaceholders = [MTA_CHANNEL_VALUE: "wandoujia"] // } // xiaomi { // manifestPlaceholders = [MTA_CHANNEL_VALUE: "xiaomi"] // } // // _360shoufa{ // manifestPlaceholders = [MTA_CHANNEL_VALUE: "360shoufa"] // } // anzhi{ // manifestPlaceholders = [MTA_CHANNEL_VALUE: "anzhi"] // } // baidushoufa{ // manifestPlaceholders = [MTA_CHANNEL_VALUE: "baidushoufa"] // } // huaweishoufa{ // manifestPlaceholders = [MTA_CHANNEL_VALUE: "huaweishoufa"] // } // } // 如果嫌上面写法麻烦,也可以这样简写,加上一个批量处理即可. productFlavors { _91 {} wandoujia {} xiaomi {} _360shoufa{} anzhi{} baidushoufa{} huaweishoufa{} } //批量处理 productFlavors.all { flavor -> defchannel = name.startsWith("_") ? name.substring(1) : name flavor.manifestPlaceholders = [MTA_CHANNEL_VALUE: channel] } applicationVariants.all { variant -> variant.outputs.each{ output -> defoutputFile = output.outputFile if(variant.buildType.name.equals('release')) { //可自定义自己想要生成的格式 defchannel = variant.productFlavors[0].name.startsWith("_") ? variant.productFlavors[0].name.substring(1) : variant.productFlavors[0].name deffileName ="v${defaultConfig.versionName}_${releaseTime()}_${channel}.apk" output.outputFile =newFile(outputFile.parent, fileName) } } } applyfrom:'productFlavors.gradle' } defreleaseTime() { returnnewDate().format("yyyyMMdd", TimeZone.getTimeZone("UTC")) } dependencies{ compilefileTree(dir:'libs',include: ['*.jar']) testCompile'junit:junit:4.12' compile'com.android.support:appcompat-v7:23.1.1' compile'com.android.support:design:23.1.1' }