Linux平台Swift语言开发学习环境搭建
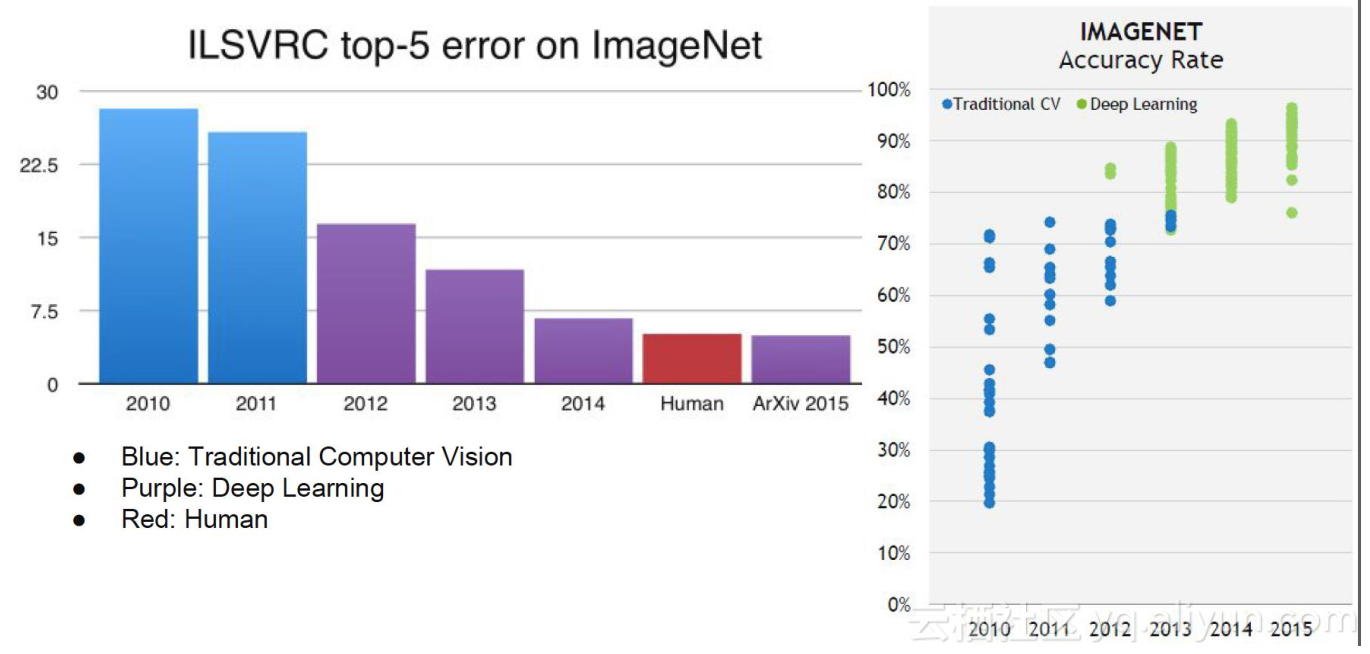
1.序言 这两天一直忙,没来得及记录东西,周三12月4日凌晨1点多看到苹果正式开源了Swift,国外各大媒体资讯动作超级快。我也兴奋的起来看了一遍关于Swift开源的最新消息。众所周知,苹果平台的Swift语言已经出来了一年半了,一直在成长,经历了好几个版本。许多人盼望的swift开源是希望可以在除了苹果平台之外的平台可以运用这个新语言。比如有人希望将来可以用swift也可以撸一撸后台开发之类,理论上是没问题的,但是同样也有人会喷这么一个愿景,但是开源一出后,多多少少社区人员会去往这个方面去努力的。苹果官方为swift新搞了个网站swift.org,也放出来了Ubuntu Linux平台的预编译好的swift工具链的打包文件以及Linux下的编译指南。我今天写这么一博客的目的就是为了介绍和推广Swift语言在初学者或者低年级大学生群体中的运用。 2.Swift+Ubuntu环境配置 首先假定我们已经安装好Ubuntu Linux操作系统了,这个系统安装很简单,网上很多的步骤教程,虚拟机的话推荐用VirtualBox。Swift支持Ubuntu 14.04和15.10两个发型版,我这选择15.10版本的包。 第一步:下载 Swift 2.2 工具链压缩包,打开终端,输入命令新建目录并下载 diveinedu@diveinedu-VirtualBox:~$ mkdir swift && cd swift; diveinedu@diveinedu-VirtualBox:~/swift$ wget https://swift.org/builds/ubuntu1510/swift-2.2-SNAPSHOT-2015-12-01-b/swift-2.2-SNAPSHOT-2015-12-01-b-ubuntu15.10.tar.gz 第二步:用tar命令解压 Swift 2.2 工具链压缩包到当前目录,并配置环境变量 先解压,再进入目录,目录下会有usr/bin和usr/lib等等子目录: diveinedu@diveinedu-VirtualBox:~/swift$ tar xvf swift-2.2-SNAPSHOT-2015-12-01-b-ubuntu15.10.tar.gz diveinedu@diveinedu-VirtualBox:~/swift$ cd swift-2.2-SNAPSHOT-2015-12-01-b-ubuntu15.10/ 然后配置用户级别的环境变量,编辑$HOME/.bashrc配置文件 diveinedu@diveinedu-VirtualBox:~/swift/swift-2.2-SNAPSHOT-2015-12-01-b-ubuntu15.10$ gedit $HOME/.bashrc 上面命令会调出图形界面文本编辑器GEdit来编辑这个配置文件,在文件的最后输入如下配置行并保存退出编辑器 export SWIFT_HOME=$HOME/swift/swift-2.2-SNAPSHOT-2015-12-01-b-ubuntu15.10 export PATH=$SWIFT_HOME/usr/bin:$PATH export LD_LIBRARY_PATH=$SWIFT_HOME/usr/lib:$LD_LIBRARY_PATH export LIBRARY_PATH=$SWIFT_HOME/usr/lib:$LIBRARY_PATH 这样环境变量就配置OK啦。这个时候我们只需要关闭我们的Shell终端重新打开终端就生效了。 3.Swift+Ubuntu初次体验 搞过iOS开发的都知道,2014年6月Swift刚出世时就随Xcode带了Playground功能,可以边写边看运行结果,辣么在Ubuntu Linux下有没有类似的呢,也有,只是没那么强大的IDE支持,我们一样可以运行类似Pyhton脚本解析器一样的Swift解析器,同步输入Swift代码来“解析”运行。这个命令就是swift,在上面的环境变量设置完后重开终端就可以直接使用了,如下所示。 diveinedu@diveinedu-VirtualBox:~$ swift Welcome to Swift version 2.2-dev (LLVM 46be9ff861, Clang 4deb154edc, Swift 778f82939c). Type :help for assistance. 1> let hello = "hello"; hello: String = "hello" 2> let world = "diveinedu" world: String = "diveinedu" 3> let space = " " space: String = " " 4> print(hello+space+world); hello diveinedu 5>hello. Available completions: append(c: Character) -> Void append(x: UnicodeScalar) -> Void appendContentsOf(newElements: S) -> Void appendContentsOf(other: String) -> Void characters: String.CharacterView debugDescription: String endIndex: Index hashValue: Int insert(newElement: Character, atIndex: Index) -> Void insertContentsOf(newElements: S, at: Index) -> Void isEmpty: Bool lowercaseString: String nulTerminatedUTF8: ContiguousArray<CodeUnit> removeAll() -> Void removeAll(keepCapacity: Bool) -> Void removeAtIndex(i: Index) -> Character removeRange(subRange: Range<Index>) -> Void replaceRange(subRange: Range<Index>, with: C) -> Void replaceRange(subRange: Range<Index>, with: String) -> Void reserveCapacity(n: Int) -> Void startIndex: Index unicodeScalars: String.UnicodeScalarView uppercaseString: String utf16: String.UTF16View utf8: String.UTF8View withCString(f: UnsafePointer<Int8> throws -> ResultUnsafePointer<Int8> throws -> Result) -> Result withMutableCharacters(body: (inout String.CharacterView) -> R(inout String.CharacterView) -> R) -> R write(other: String) -> Void writeTo(&target: Target) -> Void 6> hello.isEmpty $R0: Bool = false 在这个解析执行界面还有自动提示补全功能!简直四国矣.上面第五行是输入hello后再输入一点.然后按tab键,一下就出来这么多关于字符串的方法,妈妈再也不担心我在终端模式下不记得方法名了。 上面这特简单的几行代码还没包含类和对象,下面看看在swift解析器中直接输入类的定义和对象创建和简单使用。 diveinedu@diveinedu-VirtualBox:~$ swift Welcome to Swift version 2.2-dev (LLVM 46be9ff861, Clang 4deb154edc, Swift 778f82939c). Type :help for assistance. 1> struct Resolution { 2. var width = 0 3. var height = 0 4. } 5. class VideoMode { 6. var resolution = Resolution() 7. var interlaced = false 8. var frameRate = 0.0 9. var name: String? 10. func description() 11. { 12. print("name:\(name) frameRate:\(frameRate)") 13. } 14. } 15> let mode = VideoMode() mode: VideoMode = { resolution = { width = 0 height = 0 } interlaced = false frameRate = 0 name = nil } 16> mode.name = "1080p HD" 17> mode.frameRate = 30.0 18> mode.description() name:Optional("1080p HD") frameRate:30.0 19> 这些都只是在swift解析器中临时性的运行一些代码,如果我们需要新建.swift格式文件然后编译成可执行二进制文件形式又要怎样做呢,同样很简单,我们可以用swiftc这个命令来编译。 我们可以新建一个目录来存放swift代码文件,然后编辑一个test.swift: diveinedu@diveinedu-VirtualBox:~$ mkdir -p $HOME/swift/swiftcode diveinedu@diveinedu-VirtualBox:~$ cd $HOME/swift/swiftcode diveinedu@diveinedu-VirtualBox:~/swift/swiftcode$ gedit test.swift 当打开gedit文本编辑器后,输入上面的类和对象创建以及方法调用的代码,列出在下面 struct Resolution { var width = 0 var height = 0 } class VideoMode { var resolution = Resolution() var interlaced = false var frameRate = 0.0 var name: String? func description() { print("name:\(name) frameRate:\(frameRate)") } } let mode = VideoMode() mode.name = "1080p HD" mode.frameRate = 30.0 mode.description() 保存后关闭编辑器,然后执行swiftc test.swift来编译源文件,会出现如下链接错误: diveinedu@diveinedu-VirtualBox:~/swift/swiftcode$ swiftc test.swift <unknown>:0: error: link command failed with exit code 127 (use -v to see invocation) diveinedu@diveinedu-VirtualBox:~/swift/swiftcode$ 解决办法是安装编译依赖clang libicu-dev,输入下面命令回车(会询问当前用户密码) diveinedu@diveinedu-VirtualBox:~/swift/swiftcode$ sudo apt-get install clang libicu-dev 安装完成后再次执行编译命令swiftc test.swift就顺利编译成功,再当前目录下输出test可执行文件。 diveinedu@diveinedu-VirtualBox:~/swift/swiftcode$ swiftc test.swift diveinedu@diveinedu-VirtualBox:~/swift/swiftcode$ ./test name:Optional("1080p HD") frameRate:30.0 而且执行ldd ./test查看此二进制文件依赖的动态库可知,它链接了libswiftCore,这是所有swift程序都会需要的。 diveinedu@diveinedu-VirtualBox:~/swift/swiftcode$ ldd ./test linux-vdso.so.1 => (0x00007ffcef3f5000) libswiftCore.so => /home/diveinedu/swift/swift-2.2-SNAPSHOT-2015-12-01-b-ubuntu15.10/usr/lib/swift/linux/libswiftCore.so (0x00007f1cd2f75000) libstdc++.so.6 => /usr/lib/x86_64-linux-gnu/libstdc++.so.6 (0x00007f1cd2bdd000) libm.so.6 => /lib/x86_64-linux-gnu/libm.so.6 (0x00007f1cd28d5000) libgcc_s.so.1 => /lib/x86_64-linux-gnu/libgcc_s.so.1 (0x00007f1cd26be000) libc.so.6 => /lib/x86_64-linux-gnu/libc.so.6 (0x00007f1cd22f3000) libpthread.so.0 => /lib/x86_64-linux-gnu/libpthread.so.0 (0x00007f1cd20d5000) libdl.so.2 => /lib/x86_64-linux-gnu/libdl.so.2 (0x00007f1cd1ed1000) libicuuc.so.55 => /usr/lib/x86_64-linux-gnu/libicuuc.so.55 (0x00007f1cd1b3c000) libicui18n.so.55 => /usr/lib/x86_64-linux-gnu/libicui18n.so.55 (0x00007f1cd16d9000) libbsd.so.0 => /lib/x86_64-linux-gnu/libbsd.so.0 (0x00007f1cd14c9000) /lib64/ld-linux-x86-64.so.2 (0x0000556e488b7000) libicudata.so.55 => /usr/lib/x86_64-linux-gnu/libicudata.so.55 (0x00007f1ccfa11000) 细心的读者会发现好像不见main函数或者main相关的函数,程序照样可以运行,不管是脚本还是编译成二进制可执行文件,这个我以后再细说了。 文章转载自 开源中国社区[https://www.oschina.net]