利用Traefik+Docker构建可弹性扩展的微服务或服务集群
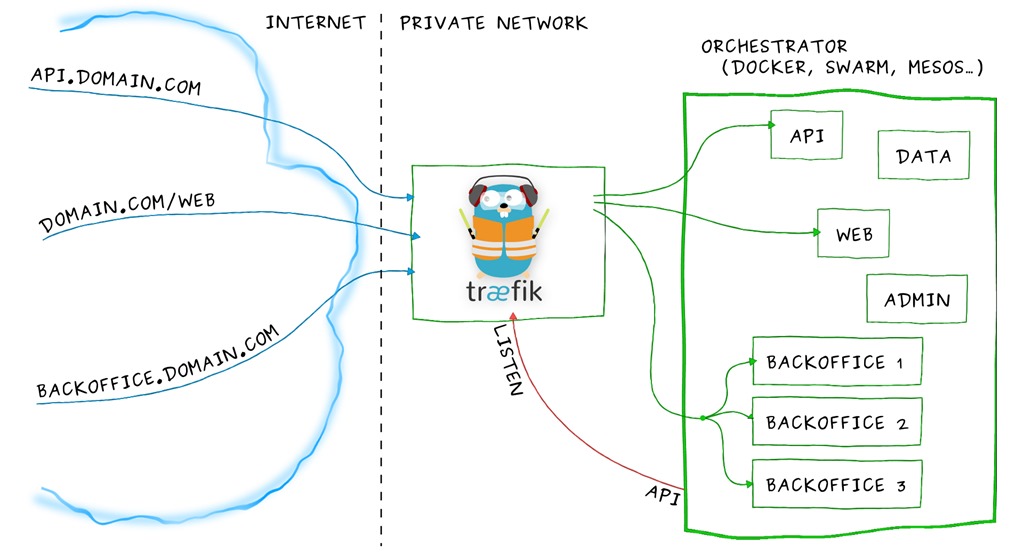
简介 Traefik是一个与Nginx、HAProxy有些相似的HTTP反向代理服务器,兼有负载均衡的功能。Nginx和HAProxy都有一个相同的问题就是,后端服务(通常称之为upstream或backend)变化(是否能正常工作、上线、下线、扩展)时,不容易动态更新Nginx和HAProxy的配置文件和重载服务,尽管有一些类似于Registrator,Consul和Consul-Template这样的工具可以来做这样的事。 图1:微服务常见的一种请求分发图。 与Nginx、HAProxy不同的是,Traefik更适合需要服务发现和服务注册的应用场景。例如,Traefik与Docker相结合非常容易,只需要指定label即可(虽然可以使用docker run指定label,但更推荐使用docker-compose.yml指定)。演示的例子直接可以参考官方网站,也可以参考下面的例子,非常简单并通俗易懂。需要指出的是Traefik并不是只能与Docker相结合,Docker,Swarm,Mesos/Marathon,Consul,Etcd,Zookeeper,BoltDB,Amazon ECS, Rest API, file...都可以。具体的可以参考官方网站和Google it。 图2:Traefik是如何管理请求的 一个简单的演示: 1.创建Traefik服务,可以使用Docker也可以使用命令行的方式。 注意:不熟悉docker-compose的可以先学习一下docker-compose的语法和应用,或者直接忽略它,再根据下文的相对目录结构、文件和命令创建。 docker-compose.yml 文件内容如下: 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 version: '2' services: traefik: image:traefik:latest restart:unless - stopped command: - - web - - docker - - docker.domain = docker.localhost - - logLevel = DEBUG networks: - webgateway ports: - "80:80" - "8080:8080" - "443:443" volumes: - / var / run / docker.sock: / var / run / docker.sock - / dev / null: / traefik.toml networks: webgateway: driver:bridge 2.使用whoami应用作为一个简易的HTTP Web服务: docker-compose.yml 文件内容如下: 1 2 3 4 5 6 7 8 9 10 11 12 13 version: '2' services: whoami: image:emilevauge / whoami networks: - web labels: - "traefik.backend=whoami" - "traefik.frontend.rule=Host:whoami.docker.localhost" networks: web: external: name:traefikself_webgateway 3.通过docker-compose logs traefik命令查看Traefik日志: 4.使用docker-compose scale whoami=3 命令扩展3个whoami应用,观察访问情况,通过CURL结果可以发现默认是轮询的wrr。 5.Traefik有一个Dashboard Web UI,可以通过网页了解当前Traefik中的运行情况和节点的健康状态。 更多参考: 官方网站(英文):https://docs.traefik.io/ 使用Docker和Traefik构建微服务(英文)http://blog.hypriot.com/post/microservices-bliss-with-docker-and-traefik/ tag:traefik,docker,微服务 --end-- 本文转自 urey_pp 51CTO博客,原文链接:http://blog.51cto.com/dgd2010/1896255,如需转载请自行联系原作者