ALiyun LOG Go Consumer Library 快速入门及原理剖析
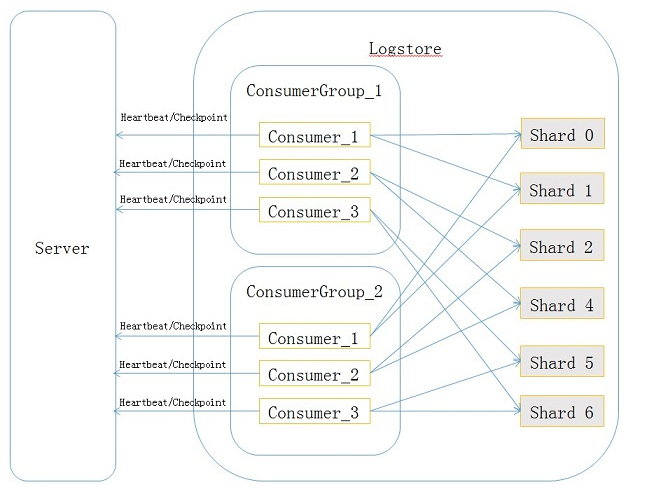
前言 Aliyun LOG Go Consumer Library是用go语言编写的协同消费库,主要处理多个消费者同时消费logstore时自动分配shard问题。 其中消费组会自动处理shard的负载均衡,消费者failover等逻辑,这部分说明会在本篇下面的篇幅中进行详细的介绍。用户只需专注在自己业务逻辑上,而无需关心shard分配、CheckPoint、Failover等事宜。 功能特点 Aliyun LOG Go Consumer Library是一个使用简单以及高度可配置的go类库,它有如下功能特点: 线程安全 - consumer 内所有的方法以及暴露的接口都是线程安全的。 异步拉取 - 调用consumer的拉取日志接口,会把当前拉取任务新开一个groutine中去执行,不会阻塞主groutine的执行。 自动重试 - 对程序运行当中出现的可重试的异常,consumer会自动重试,重试过程不会导致数据的重复消费。 优雅关闭 - 调用关闭程序接口,consumer会等待当前所有已开出的groutine任务结束后在结束主程序,保证下次开始不会重复消费数据。 本地调试 - 可通过配置支持将日志内容输出到本地或控制台,并支持轮转、日志数、轮转大小设置。 高性能 - 基于go语言的特性,go的goroutine在并发多任务处理能力上有着与生俱来的优势。所以consumer 对每一个获得的可消费分区都会开启一个单独的groutine去执行消费任务,相对比直接使用cpu线程处理,对系统性能消耗更小,效率更高。 使用简单 - 在整个使用过程中,不会产生数据丢失,以及重复,用户只需要配置简单配置文件,创建消费者实例,写处理日志的代码就可以,用户只需要把重心放到自己的消费逻辑上面即可,不需关心消费断点保存,以及错误重试等问题。 消费组原理剖析 为了带您更好的理解 go版本的consumer library,本篇讲介绍consumer library的实现原理,在了解原理之前,进行简单的术语简介。 在consumer library 中主要有4个概念,分别是consumer group,consumer,heartbeat和checkpoint,它们之间关系如下(图片出处:https://github.com/aliyun/loghub_consumer_library): consumer group: 是logstore的子资源,拥有相同consumer group 名字的消费者共同消费同一个logstore的所有数据,这些消费者之间不会重复消费数据,一个logstore下面可以最多创建5个consumer group,不可以重名,同一个logstore下面的consumer group之间消费数据不会互相影响。consumer group有两个很重要的属性: { "order":boolean, "timeout": integer } order属性:在单个shard中是否按顺序消费。true:表示在单个shard中按顺序消费。shard分裂后,先消费原shard数据,然后并列消费两个新shard的数据。false:表示不按顺序消费。 timeout属性:表示consumer group中消费者的超时时间,单位是秒,当一个消费者汇报心跳的时间间隔超过timeout,会被认为已经超时,服务端认为这个consumer此时已经下线了。 consumer: 消费者,每个consumer上会被分配若干个shard,consumer的职责就是要消费这些shard上的数据,同一个consumer group中的consumer必须不重名。 heartbeat: 消费者心跳,consumer需要定期向服务端汇报一个心跳包,用于表明自己还处于存活状态。 checkpoint: 消费者定期将分配给自己的shard消费到的位置保存到服务端,这样当这个shard被分配给其它消费者时,从服务端可以获取shard的消费断点,接着从断点继续消费数据。 自动负载均衡与自动处理消费者failover 如上图,当前有两个消费者A和B ,分别持有1,2,3,4个分区进行消费,消费者A被取消或者因为其他原因停止消费,服务端会自动将A消费者持有的1,2分区分配给B消费者进行消费。如下图 那么服务端是如何实现自动负载均衡的呢,还回到当消费者A,B共同持有4个分区的情况下,此时,如果新的消费者C注册加入到消费组当中来,服务端消费组会将logstore下所有的可消费分区对所有的消费者进行平均分配,如下图,从而在服务端自动的去实现负载均衡,用户即可不用关心消费者之间的负载均衡关系。 Consumer Lib实现原理 1.当调用一个消费者实例的run方法启动的时候,会开启一个心跳线程去给服务端发送当前心跳信息,同时主线程继续执行,检查是否获得可消费分区。 2.Heartbeat心跳线程会汇报当前消费者持有的消费分区到服务端,服务端会分配给消费者可消费的分区ID。 3.主线程会遍历从心跳线程获得的所有可消费分区,同时会将持有的消费分区汇报给心跳线程,每一个可消费分区都会调用consume方法。 4.每一个消费分区中的consume方法(如上图)只负责更新任务状态,调用会立刻返回,具体的消费任务会开启单独的groutine去执行,每个分区都会维护自己的一个任务状态机,不同分区间任务状态不会相互影响。 5.每次消费任务完成,会调用flushCheck方法,检查当前时间相对上次更新检查点时间是否超过60秒,超过就刷新当前检查点到服务端。如果执行退出程序函数,会立即将当前消费者的检查点保存到服务端。 6.如果执行任务中发生可重试异常,会在任务groutine中重试该任务,并且会在每一次遍历中跳过当前正在执行的任务groutine,不会造成任务的重复开启。 使用步骤 1.源码下载 请先克隆代码到自己的GOPATH路径下(源码地址:aliyun-go-consumer-library),项目使用了vendor工具管理第三方依赖包,所以克隆下来项目以后无需安装任何第三方工具包。 2.配置LogHubConfig LogHubConfig是提供给用户的配置类,用于配置消费策略,您可以根据不同的需求设定不同的值,各参数含义如文章尾部图示 LogHubConfig详细配置 3.覆写消费逻辑 func process(shardId int, logGroupList *sls.LogGroupList) string { for _, logGroup := range logGroupList.LogGroups { err := client.PutLogs(option.Project, "copy-logstore", logGroup) if err != nil { fmt.Println(err) } } fmt.Println("shardId %v processing works sucess", shardId) return "" // 不需要重置检查点情况下,请返回空字符串,如需要重置检查点,请返回需要重置的检查点游标。 } 在实际消费当中,您只需要根据自己的需要重新覆写消费函数process 即可,上图只是一个简单的demo,将consumer获取到的日志进行了打印处理,注意,该函数参数和返回值不可改变,否则会导致消费失败。 4.创建消费者并开始消费 // option是LogHubConfig的实例 consumerWorker := consumerLibrary.InitConsumerWorker(option, process) // 调用Start方法开始消费 consumerWorker.Start() 调用InitConsumerWorkwer方法,将配置实例对象和消费函数传递到参数中生成消费者实例对象,调用Start方法进行消费。 5.关闭消费者 ch:=make(chan os.Signal) //将os信号值作为信道 signal.Notify(ch) consumerWorker.Start() if _, ok := <-ch; ok { // 当获取到os停止信号以后,例如ctrl+c触发的os信号,会调用消费者退出方法进行退出。 consumerWorker.StopAndWait() } 上图中的例子通过go的信道做了os信号的监听,当监听到用户触发了os退出信号以后,调用StopAndWait()方法进行退出,用户可以根据自己的需要设计自己的退出逻辑,只需要调用StopAndWait()即可。 Cosumer Lib使用进阶 1.消费失败处理办法 当您拉取到日志对日志进行消费处理,处理失败的时候,可以在process方法里面重新执行您的消费逻辑,不跳出process方法,当process方法不结束的情况下会一直处理当前未消费成功的数据,从而避免重复消费,以下为简单的样例: func process(shardId int, logGroupList *sls.LogGroupList) string { for { err := func(shardId int, logGroupList *sls.LogGroupList) error { // 在这个函数当中去写具体的消费逻辑,如果消费失败,返回自定义的error return nil }(shardId,logGroupList) if err != nil{ // 当捕获到消费失败的error以后只要重复继续执行消费逻辑即可,不要跳出process方法。 continue }else{ // 消费成功的话,跳出循环,process方法执行完毕,会继续拉取数据进行下次消费。 break } } return "" // 不需要重置检查点情况下,请返回空字符串,如需要重置检查点,请返回需要重置的检查点游标。 } 2.重置Checkpoint 在补数据或重复计算等场景中,需要将某个ConsumerGroup点位设置为某一个时间点,使当前消费组能够从新位置开始消费。可通过以下三种方式完成。 (a.) 删除消费组。 停止消费程序,并在控制台删除消费组。 修改代码,使用指定时间点消费,重新启动程序。 (b.) 通过SDK将当前消费组重置到某一个时间点。 停止消费程序。 使用SDK修改位点,重新启动消费程序。具体示例如下图所示: func updateCheckPoint(){ err := client.UpdateCheckpoint(project,logstore,"ConsumerGroupName","consumerName",1,"youCheckPoint",true) if err != nil{ fmt.Println(err) } } (c.) 在process消费函数中返回需要重置的检查点。 为了满足在用户可以在不停止程序的情况下重置检查点的需求,提供了在process消费函数中充值检查点的方法,只要将重置的检查点作为返回值返回就可以,如果不需要只需要返回空字符串即可。 下图的所示例的代码设置了一个触发时间,当程序时间等于触发时间的时候,会重置检查点为开始的游标,进行分区的重新消费。 func process(shardId int,logGroupList *sls.LogGroupList) string { futureTime := 18888888 // 例如设置一个未来的Unix时间戳 if time.Now().Unix() == futureTime { // 当程序运行的当时时间等于设置的未来时间,返回需要重置的检查点 cursur, err := client.GetCursor(project,logstore,shardId,"begin") if err != nil { fmt.Println(err) } // 返回当前分区开始游标,就会重置消费位置为开始位置,进行当前分区的从新消费。 return cursor // 需要注意,如果每次消费完都返回指定游标的话,则每一次都会重置下次消费位置为返回的游标。 } return "" } 下图为LogHubConfig详细配置参数。 参数 类型 能否为空 描述 Endpoint String 否 服务入口,关于如何确定project对应的服务入口可参考文章服务入口。 AccessKeyID String 否 账户的AK id。 AccessKeySecret String 否 账户的AK 密钥。 Project String 否 将要消费的项目名称。 Logstore String 否 将要消费的项目下的日志库的名字。 ConsumerGroupName String 否 消费组的名称。 ConsumerName String 否 消费者的名称。注意:同一个消费组下面的消费者名称不能重复,不同消费组之间互不影响。 CursorPosition String 否 开始消费的时间点,该参数只在第一次创建消费组的时候使用,当再次启动消费组进行消费的时候会从上次消费到的断点进行继续消费,该参数可选的参数有3个: “BEGIN_CURSOR”,"END_CURSOR","SPECIAL_TIMER_CURSOR",分别为开始位置,结束位置,和自定义起始位置。 HeartbeatIntervalInSecond Int 是 向服务端发送的心跳间隔,默认值为20秒,如果超过设定值的3倍没有向服务端汇报心跳,服务端就任务该分区已经掉线会给该分区重新分配消费者。建议使用默认值。 DataFetchInterval Int64 是 从服务端拉取日志时间间隔,默认值是2秒,不能把这个值设置小于1s。 MaxFetchLogGroupCount Int 是 从服务端一次拉取日志组数量,日志组可参考内容日志组,默认值是1000,其取值范围是1-1000。 CursorStartTime Int64 否 自定义日志消费时间点,只有当CursorPosition设置为"SPECIAL_TIMER_CURSOR"时,该参数才能使用,参数为unix时间戳。时间单位为秒。 InOrder Bool 否 是否按序消费,默认为false。 AllowLogLevel String 否 设置日志输出级别,默认值是Info,consumer中一共有4种日志输出级别,分别为debug,info,warn和error。 LogFileName String 否 日志文件输出路径,不设置的话默认输出到stdout。 IsJsonType Bool 否 是否格式化文件输出格式,默认为false。 LogMaxSize Int 否 单个日志存储数量,默认为10M。 LogMaxBackups Int 否 日志轮转数量,默认为10。 LogCompass Bool 否 是否使用gzip 压缩日志,默认为false。 应用实例 为了进一步减少学习成本,我们为您准备了 Aliyun LOG Go Consumer Library 应用实例。示例中包含了consumer 从创建到关闭的全部流程。