用Pomelo 搭建一个简易的推送平台
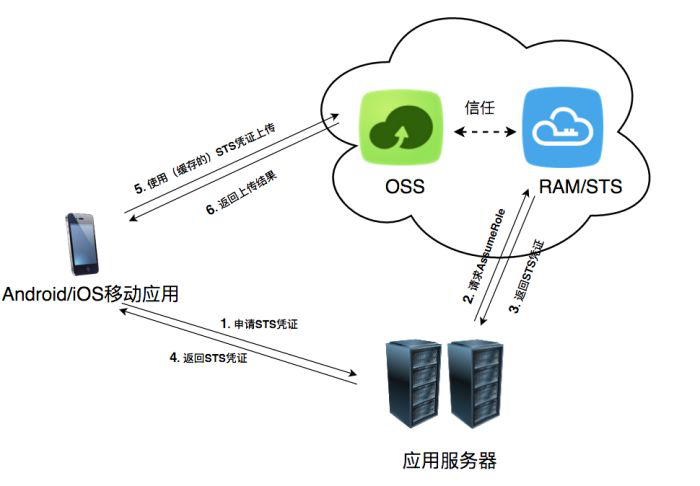
前言 实际上,个人感觉,pomelo 目前提供的两个默认sioconnector和hybridconnector使用的协议并不适合用于做手机推送平台,在pomelo的一份公开ppt里面,有提到过, 网易的消息推送平台是基于pomelo开发的 (一个frontend 支持30w 长连接,消耗了3g 内存,如果我没记错数据应该是这样),不过,这里用的前端(frontend)实现的是基于MQTT协议,我估计这个基于MQTT协议实现的frontend,基本不可能开源出来.这里只是说,默认提供的frontend不适合用于构建大型的推送平台(c10m规模的),一般而言(c10k级别的),个人感觉还是够用的. 为了展示,更多pomelo 的相关特性,可能这里的逻辑业务,与实际有所不同.敬请注意 推送平台的架构图 整个应用的架构图: 后端 pomelo@0.4.3 前端 android web browser 开发约定 客户端请求对象 1 2 3 4 5 { "role" : "client/server" , "apikey" : "String" , "clientId" : "String" } 服务端返回对象 发给web management 1 2 3 4 5 { "code" : "Int httpCode ex: 200" , "msg" : "String" , "users" : "Array 客户端的clientId 值 ex:[" android1 "] " } 发给android客户端 1 2 3 4 { "code" : "Int httpCode ex: 200" , "msg" : "String" } 客户端访问用的route android: connector route = sio-connector.entryHandler.enter, 用于把当前客户端加入到推送频道当中 WebManagement: connector route = hybrid-connector.entryHandler.enter,用于连接服务器. backend route = pushserver.pushHandler.pushAll, 把消息推送到所有已连接的客户端. 后台编码 Pomelo 有个特点,就是约定开发,很多地方是约定好的配置,优点是,架构清晰,可读性好,缺点是,需要大量的文档支持,目前而言,pomelo的官方文档做的不好的地方就是,虽然文档都有了,但是太零散了,分类不清楚,还有就是文档没跟上开发,有时候,你不阅读里面源码根本不知道这个api要传那些参数. sioconnector / hybridconnector 由于pomelo 0.3 以后新增了一个新的connector:hybridconnector,支持socket和websocket,使用二进制通讯协议,但是除了,网页js版本和c 客户端实现了这个connector,其他客户端均还没实现,所以,我们还需要一个兼容android 客户端的connector: siocnnector,关于两个connector 具体比较,以后有空重写这篇的时候,暂时,你只要知道,这个两个connector,一个基于socket.io,一个基于socket和websocket 即可. app.js由于我们用到了两个不同的connector,所以要在app.js写上: 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 // 支持 socket.io app.configure( 'production|development' , 'sio-connector' , function(){ app.set( 'connectorConfig' , { connector : pomelo.connectors.sioconnector }); }); //支持 websocket 和 socket app.configure( 'production|development' , 'hybrid-connector' , function(){ app.set( 'connectorConfig' , { connector : pomelo.connectors.hybridconnector, heartbeat : 300 , useDict: true , useProtobuf: true }); }); 经过这样的配置,我们就能够使用两个不同的connector了. 推送实现 用pomelo 进行消息的推送,非常便捷,由于,我们现在只关注推消息给全部客户端,那样就非常简单了. 推送流程: 根据uuid 把 android 客户端添加到各自的推送频道当中. web 端根据uuid 把消息推送的全部在线的客户端. 为了教学的方便,这里的uuid 硬编码为: xxx-xx--xx-xx 把客户端添加到相应的channel 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 //把客户端添加到推送列表中 PushRemote.prototype.add = function(uid, role, sid, channelName, cb){ var channel = this .channelService.getChannel(channelName, true ); if (role === 'server' ){ //web 服务端直接返回用户列表 cb( null , this .getUsers(channelName)); } else { if (!!channel){ channel.add(uid ,sid); } //uuid 告诉给服务端onAdd 事件 // [{uid: userId, sid: frontendServerId}] var server = [{uid: channelName, sid: sid}]; this .channelService.pushMessageByUids( 'onAdd' , {msg: "add ok" , users: this .getUsers(channelName)},server, function(err){ if (err){ console.log(err); return ; } }); } }; Frontend 利用rpc 调用pushserver 添加客户端到相应频道的方法. 1 2 3 4 5 6 7 8 9 10 11 12 //sid 统一为web managment 所在的 frontend server. this .app.rpc.pushserver.pushRemote.add(session, uid,role, 'connector-server-client' , uuid, function(err, users){ if (err){ console.log(err); return ; } if (users){ next( null , {code: 200 , msg: 'push server is ok.' , users: users}); } else { next( null ,{code: 200 , msg: "add ok" , users: users}); } }); web 管理端调用消息推送 1 2 3 4 5 6 7 8 9 10 11 Handler.prototype.pushAll = function(msg, session, next){ var pushMsg = this .channelService.getChannel(msg.apikey, false ); pushMsg.pushMessage( 'onMsg' ,{msg: msg.msg}, function(err){ if (err){ console.log(err); } else { console.log( 'push ok' ); next( null , {code: 200 , msg: 'push is ok.' }); } }); }; 以上就是主要客户端如何加入到推送队列的代码,以及web 管理端进行消息推送的主要代码,是不是很简单! 完整代码可以参阅我的githubhttps://github.com/youxiachai 有一点要注意的,如果pomelo 项目要部署到外网或者局域网,frontend 的host 要填写当前host 主机的ip 地址 例如: 1 2 3 "connector" : [ { "id" : "connector-server-1" , "host" : "127.0.0.1" , "port" : 3150 , "clientPort" : 3010 , "frontend" : true } ] 部署到某台服务器,需要修改 1 2 3 "connector" : [ { "id" : "connector-server-1" , "host" : "192.168.1.107" , "port" : 3150 , "clientPort" : 3010 , "frontend" : true } ] 客户端访问相应的host 的地址. 客户端和服务端的github 地址:https://github.com/youxiachai/pomelo-pushServer-Demo 附录 如果,你现在对pomelo感兴趣的话,你可以看下我写的pomelo 的系列教程(因为还没写好所以暂时只发布在我的博客)暂时一共四篇.基本涵盖了pomelo 大部分基本知识点. http://blog.gfdsa.net/tags/pomelo/ 广州有招nodejs 程序员(有两年android 开发经验..orz)的吗...能否给个面试机会,联系邮箱: youxiachai@gmail.com 参与的相关社区: github:https://github.com/youxiachai cnodejs(Top积分榜 14 ...):http://cnodejs.org/user/youxiachai 版权声明:原创作品,如需转载,请注明出处。否则将追究法律责任 本文转自youxiachai 博客,原文链接:http://blog.51cto.com/youxilua/1223909 如需转载请自行联系原作者