使用 Node.js 搭建一个 API 网关
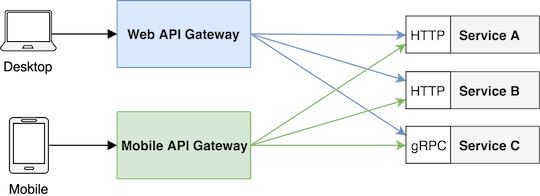
原文地址:Building an API Gateway using Node.js 外部客户端访问微服务架构中的服务时,服务端会对认证和传输有一些常见的要求。API 网关提供共享层来处理服务协议之间的差异,并满足特定客户端(如桌面浏览器、移动设备和老系统)的要求。 微服务和消费者 微服务是面向服务的架构,团队可以独立设计、开发和发布应用程序。它允许在系统各个层面上的技术多样性,团队可以在给定的技术难题中使用最佳语言、数据库、协议和传输层,从而受益。例如,一个团队可以使用 HTTP REST 上的 JSON,而另一个团队可以使用 HTTP/2 上的 gRPC 或 RabbitMQ 等消息代理。 在某些情况下使用不同的数据序列化和协议可能是强大的,但要使用我们的产品的客户可能有不同的需求。该问题也可能发生在具有同质技术栈的系统中,因为客户可以从桌面浏览器通过移动设备和游戏机到遗留系统。一个客户可能期望 XML 格式,而另一个客户可能希望 JSON 。在许多情况下,您需要同时支持它们。 当客户想要使用您的微服务时,您可以面对的另一个挑战来自于通用的共享逻辑(如身份验证),因为您不想在所有服务中重新实现相同的事情。 总结:我们不想在我们的微服务架构中实现我们的内部服务,以支持多个客户端并可以重复使用相同的逻辑。这就是 API 网关出现的原因,其作为共享层来处理服务协议之间的差异并满足特定客户端的要求。 什么是 API 网关? API 网关是微服务架构中的一种服务,它为客户端提供共享层和 API,以便与内部服务进行通信。API 网关可以进行路由请求、转换协议、聚合数据以及实现共享逻辑,如认证和速率限制器。 您可以将 API 网关视为我们的微服务世界的入口点。 我们的系统可以有一个或多个 API 网关,具体取决于客户的需求。例如,我们可以为桌面浏览器、移动应用程序和公共 API 提供单独的网关。 API 网关作为微服务的切入点 Node.js 用于前端团队的 API 网关 由于 API 网关为客户端应用程序(如浏览器)提供了功能,它可以由负责开发前端应用程序的团队实施和管理。 这也意味着用哪种语言实现 API Gateway 应由负责特定客户的团队选择。由于 JavaScript 是开发浏览器应用程序的主要语言,即使您的微服务架构以不同的语言开发,Node.js 也可以成为实现 API 网关的绝佳选择。 Netflix 成功地使用 Node.js API 网关及其 Java 后端来支持广泛的客户端 - 了解更多关于它们的方法阅读 The "Paved Road" PaaS for Microservices at Netflix 这篇文章 Netflix 处理不同客户端的方法, 资源 API 网关功能 我们之前讨论过,可以将通用共享逻辑放入您的 API 网关,本节将介绍最常见的网关职责。 路由和版本控制 我们将 API 网关定义为您的微服务的入口点。在您的网关服务中,您可以指定从客户端路由到特定服务的路由请求。您甚至可以通过路由处理版本或更改后端接口,而公开的接口可以保持不变。您还可以在您的 API 网关中定义与多个服务配合的新端点。 API 网关作为微服务入口点 网关设计的升级 API 网关方法也可以帮助您分解您的整体应用程序。在大多数情况下,在微服务端重构一个系统不是一个好主意也是不可能的,因为我们需要在重构期间为业务发送新的以及原有的功能。 在这种情况下,我们可以将代理或 API 网关置于我们的整体应用程序之前,将新功能作为微服务实现,并将新端点路由到新服务,同时通过原有的路由服务旧端点。这样以后,我们也可以通过将原有功能转变为新服务来分解整体。 随着网关设计的升级,我们可以实现整体架构到微型服务的平滑过渡 API 网关设计的升级 认证 大多数微服务基础设施需要进行身份验证。将共享逻辑(如身份验证)添加到 API 网关可以帮助您保持您的服务的体积变小以及可以集中管理域。 在微服务架构中,您可以通过网络配置将您的服务保护在 DMZ (保护区)中,并通过 API 网关向客户公开。该网关还可以处理多个身份验证方法。例如,您可以同时支持基于 cookie 和 token 的身份验证。 具有认证功能的 API 网关 数据汇总 在微服务架构中,可能客户端所需要的数据的聚合级别不同,比如对在各种微服务中产生的非规范化数据实体。在这种情况下,我们可以使用我们的 API 网关来解决这些依赖关系并从多个服务收集数据。 在下图中,您可以看到 API 网关如何将用户和信用信息作为一个数据返回给客户端。请注意,这些数据由不同的微服务所拥有和管理。 序列化格式转换 我们需要支持客户端不同的数据序列化格式这样子的需求可能会发生。 想象一下我们的微服务使用 JSON 的情况,但我们的客户只能使用 XML APIs。在这种情况下,我们可以在 API 网关中把 JSON 转换为 XML,而不是在所有的微服务器中分别进行实现。 协议转换 微服务架构允许多通道协议传输从而获取多种技术的优势。然而,大多数客户端只支持一个协议。在这种情况下,我们需要转换客户端的服务协议。 API 网关还可以处理客户端和微服务器之间的协议转换。 在下一张图片中,您可以看到客户端希望通过 HTTP REST 进行的所有通信,而内部的微服务使用 gRPC 和 GraphQL 。 速率限制和缓存 在前面的例子中,您可以看到我们可以把通用的共享逻辑(如身份验证)放在 API 网关中。除了身份验证之外,您还可以在 API 网关中实现速率限制,缓存以及各种可靠性功能。 超负荷的 API 网关 在实现您的 API 网关时,您应避免将非通用逻辑(如特定数据转换)放入您的网关。 服务应该始终拥有他们的数据域的全部所有权。构建一个超负荷的 API 网关,让微服务团队来控制,这违背了微服务的理念。 这就是为什么你应该关注你的 API 网关中的数据聚合 - 你应该避免它有大量逻辑甚至可以包含特定的数据转换或规则处理逻辑。 始终为您的 API 网关定义明确的责任,并且只包括其中的通用共享逻辑。 Node.js API 网关 当您希望在 API 网关中执行简单的操作,比如将请求路由到特定服务,您可以使用像 nginx 这样的反向代理。但在某些时候,您可能需要实现一般代理不支持的逻辑。在这种情况下,您可以在 Node.js 中实现自己的 API 网关。 在 Node.js 中,您可以使用 http-proxy 软件包简单地代理对特定服务的请求,也可以使用更多丰富功能的 express-gateway 来创建 API 网关。 在我们的第一个 API 网关示例中,我们在将代码委托给 user 服务之前验证请求。 const express = require('express') const httpProxy = require('express-http-proxy') const app = express() const userServiceProxy = httpProxy('https://user-service') // 身份认证 app.use((req, res, next) => { // TODO: 身份认证逻辑 next() }) // 代理请求 app.get('/users/:userId', (req, res, next) => { userServiceProxy(req, res, next) }) 另一种示例可能是在您的 API 网关中发出新的请求,并将响应返回给客户端: const express = require('express') const request = require('request-promise-native') const app = express() // 解决: GET /users/me app.get('/users/me', async (req, res) => { const userId = req.session.userId const uri = `https://user-service/users/${userId}` const user = await request(uri) res.json(user) }) Node.js API 网关总结 API 网关提供了一个共享层,以通过微服务架构来满足客户需求。它有助于保持您的服务小而专注。您可以将不同的通用逻辑放入您的 API 网关,但是您应该避免 API 网关的过度使用,因为很多逻辑可以从服务团队中获得控制。 作者:牧云云 出处:http://www.cnblogs.com/MuYunyun/" 本文版权归作者和博客园所有,欢迎转载,转载请标明出处。 如果您觉得本篇博文对您有所收获,请点击右下角的 [推荐],谢谢!