听说你Binder机制学的不错,来面试下这几个问题(一)
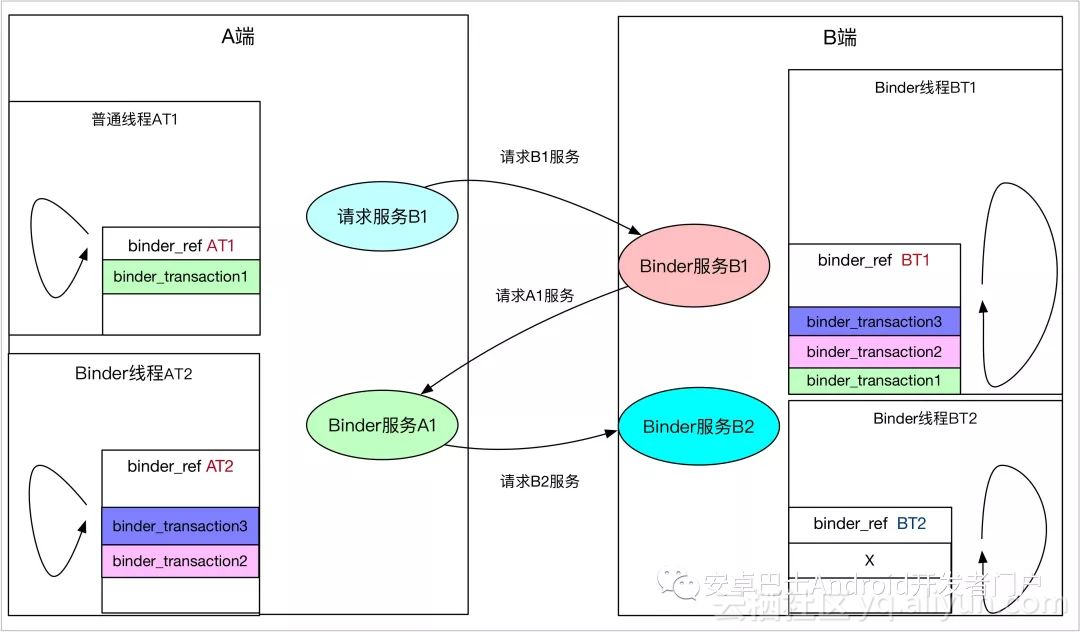
Binder承担了绝大部分Android进程通信的职责,可以看做是Android的血管系统,负责不同服务模块进程间的通信。在对Binder的理解上,可大可小,日常APP开发并不怎么涉及Binder通信知识,最多就是Service及AIDL的使用会涉及部分Binder知识。Binder往小了说可总结成一句话:一种IPC进程间通信方式,负责进程A的数据,发送到进程B。往大了说,其实涉及的知识还是很多的,如Android 对于原Binder驱动的扩展、Zygote进程孵化中对于Binder通信的支持、Java层Binder封装,Native层对于Binder通信的封装、Binder讣告机制等等。很多分析Binder框架的文都是从ServiceManager、Binder驱动、addService、getService来分析等来分析,其实这些主要是针对系统提供的服务,但是bindService启动的服务走的却还是有很大不同的。本篇文章主要简述一些Binder难以理解的点,但不会太细的跟踪分析,只抛砖,自己去发掘玉。 Binder的定向制导,如何找到目标Binder,唤起进程或者线程Binder中的红黑树,为什么会有两棵binder_ref红黑树Binder一次拷贝原理(直接拷贝到目标线程的内核空间,内核空间与用户空间对应)Binder传输数据的大小限制(内核4M 上层限制1m-8k),传输Bitmap过大,就会崩溃的原因,Activity之间传输BitMap系统服务与bindService等启动的服务的区别Binder线程、Binder主线程、Client请求线程的概念与区别Client是同步而Server是异步到底说的什么Android APP进程天生支持Binder通信的原理是什么Android APP有多少Binder线程,是固定的么Binder线程的睡眠与唤醒(请求线程睡在哪个等待队列上,唤醒目标端哪个队列上的线程)Binder协议中BC与BR的区别Binder在传输数据的时候是如何层层封装的--不同层次使用的数据结构(命令的封装)Binder驱动传递数据的释放(释放时机)一个简单的Binder通信C/S模型ServiceManager addService的限制(并非服务都能使用ServiceManager的addService)bindService启动Service与Binder服务实体的流程Java层Binder实体与与BinderProxy是如何实例化及使用的,与Native层的关系是怎样的Parcel readStrongBinder与writeStrongBinder的原理Binder如何精确制导,找到目标Binder实体,并唤醒进程或者线程 Binder实体服务其实有两种,一是通过addService注册到ServiceManager中的服务,比如ActivityManagerService、PackageManagerService、PowerManagerService等,一般都是系统服务;还有一种是通过bindService拉起的一些服务,一般是开发者自己实现的服务。这里先看通过addService添加的被ServiceManager所管理的服务。有很多分析ServiceManager的文章,本文不分析ServiceManager,只是简单提一下,ServiceManager是比较特殊的服务,所有应用都能直接使用,因为ServiceManager对于Client端来说Handle句柄是固定的,都是0,所以ServiceManager服务并不需要查询,可以直接使用。 理解Binder定向制导的关键是理解Binder的四棵红黑树,先看一下binder_proc结构体,在它内部有四棵红黑树,threads,nodes,refs_by_desc,refs_by_node,nodes就是Binder实体在内核中对应的数据结构,binder_node里记录进程相关的binder_proc,还有Binder实体自身的地址等信息,nodes红黑树位于binder_proc,可以知道Binder实体其实是进程内可见,而不是线程内。 struct binder_proc { struct hlist_node proc_node; struct rb_root threads; struct rb_root nodes; struct rb_root refs_by_desc; struct rb_root refs_by_node; 。。。 struct list_head todo; wait_queue_head_t wait; 。。。 }; 现在假设存在一堆Client与Service,Client如何才能访问Service呢?首先Service会通过addService将binder实体注册到ServiceManager中去,Client如果想要使用Servcie,就需要通过getService向ServiceManager请求该服务。在Service通过addService向ServiceManager注册的时候,ServiceManager会将服务相关的信息存储到自己进程的Service列表中去,同时在ServiceManager进程的binder_ref红黑树中为Service添加binder_ref节点,这样ServiceManager就能获取Service的Binder实体信息。而当Client通过getService向ServiceManager请求该Service服务的时候,ServiceManager会在注册的Service列表中查找该服务,如果找到就将该服务返回给Client,在这个过程中,ServiceManager会在Client进程的binder_ref红黑树中添加binder_ref节点,可见本进程中的binder_ref红黑树节点都不是本进程自己创建的,要么是Service进程将binder_ref插入到ServiceManager中去,要么是ServiceManager进程将binder_ref插入到Client中去。之后,Client就能通过Handle句柄获取binder_ref,进而访问Service服务。 getService之后,便可以获取binder_ref引用,进而获取到binder_proc与binder_node信息,之后Client便可有目的的将binder_transaction事务插入到binder_proc的待处理列表,并且,如果进程正在睡眠,就唤起进程,其实这里到底是唤起进程还是线程也有讲究,对于Client向Service发送请求的状况,一般都是唤醒binder_proc上睡眠的线程: struct binder_ref { int debug_id; struct rb_node rb_node_desc; struct rb_node rb_node_node; struct hlist_node node_entry; struct binder_proc *proc; struct binder_node *node; uint32_t desc; int strong; int weak; struct binder_ref_death *death; }; binder_proc为何会有两棵binder_ref红黑树 binder_proc中存在两棵binder_ref红黑树,其实两棵红黑树中的节点是复用的,只是查询方式不同,一个通过handle句柄,一个通过node节点查找。个人理解:refs_by_node红黑树主要是为了binder驱动往用户空间写数据所使用的,而refs_by_desc是用户空间向Binder驱动写数据使用的,只是方向问题。比如在服务addService的时候,binder驱动会在在ServiceManager进程的binder_proc中查找binder_ref结构体,如果没有就会新建binder_ref结构体,再比如在Client端getService的时候,binder驱动会在Client进程中通过 binder_get_ref_for_node为Client创建binder_ref结构体,并分配句柄,同时插入到refs_by_desc红黑树中,可见refs_by_node红黑树,主要是给binder驱动往用户空间写数据使用的。相对的refs_by_desc主要是为了用户空间往binder驱动写数据使用的,当用户空间已经获得Binder驱动为其创建的binder_ref引用句柄后,就可以通过binder_get_ref从refs_by_desc找到响应binder_ref,进而找到目标binder_node。可见有两棵红黑树主要是区分使用对象及数据流动方向,看下面的代码就能理解: // 根据32位的uint32_t desc来查找,可以看到,binder_get_ref不会新建binder_ref节点 static struct binder_ref *binder_get_ref(struct binder_proc *proc, uint32_t desc) { struct rb_node *n = proc->refs_by_desc.rb_node; struct binder_ref *ref; while (n) { ref = rb_entry(n, struct binder_ref, rb_node_desc); if (desc < ref->desc) n = n->rb_left; else if (desc > ref->desc) n = n->rb_right; else return ref; } return NULL; } 可以看到binder_get_ref并具备binder_ref的创建功能,相对应的看一下binder_get_ref_for_node,binder_get_ref_for_node红黑树主要通过binder_node进行查找,如果找不到,就新建binder_ref,同时插入到两棵红黑树中去 static struct binder_ref *binder_get_ref_for_node(struct binder_proc *proc, struct binder_node *node) { struct rb_node *n; struct rb_node **p = &proc->refs_by_node.rb_node; struct rb_node *parent = NULL; struct binder_ref *ref, *new_ref; while (*p) { parent = *p; ref = rb_entry(parent, struct binder_ref, rb_node_node); if (node < ref->node) p = &(*p)->rb_left; else if (node > ref->node) p = &(*p)->rb_right; else return ref; } // binder_ref 可以在两棵树里面,但是,两棵树的查询方式不同,并且通过desc查询,不具备新建功能 new_ref = kzalloc(sizeof(*ref), GFP_KERNEL); if (new_ref == NULL) return NULL; binder_stats_created(BINDER_STAT_REF); new_ref->debug_id = ++binder_last_id; new_ref->proc = proc; new_ref->node = node; rb_link_node(&new_ref->rb_node_node, parent, p); // 插入到proc->refs_by_node红黑树中去 rb_insert_color(&new_ref->rb_node_node, &proc->refs_by_node); // 是不是ServiceManager的 new_ref->desc = (node == binder_context_mgr_node) ? 0 : 1; // 分配Handle句柄,为了插入到refs_by_desc for (n = rb_first(&proc->refs_by_desc); n != NULL; n = rb_next(n)) { ref = rb_entry(n, struct binder_ref, rb_node_desc); if (ref->desc > new_ref->desc) break; new_ref->desc = ref->desc + 1; } // 找到目标位置 p = &proc->refs_by_desc.rb_node; while (*p) { parent = *p; ref = rb_entry(parent, struct binder_ref, rb_node_desc); if (new_ref->desc < ref->desc) p = &(*p)->rb_left; else if (new_ref->desc > ref->desc) p = &(*p)->rb_right; else BUG(); } rb_link_node(&new_ref->rb_node_desc, parent, p); // 插入到refs_by_desc红黑树中区 rb_insert_color(&new_ref->rb_node_desc, &proc->refs_by_desc); if (node) { hlist_add_head(&new_ref->node_entry, &node->refs); binder_debug(BINDER_DEBUG_INTERNAL_REFS, "binder: %d new ref %d desc %d for " "node %d\n", proc->pid, new_ref->debug_id, new_ref->desc, node->debug_id); } else { binder_debug(BINDER_DEBUG_INTERNAL_REFS, "binder: %d new ref %d desc %d for " "dead node\n", proc->pid, new_ref->debug_id, new_ref->desc); } return new_ref; } 该函数调用在binder_transaction函数中,其实就是在binder驱动访问target_proc的时候,这也也很容易理解,Handle句柄对于跨进程没有任何意义,进程A中的Handle,放到进程B中是无效的。 Binder一次拷贝原理 Android选择Binder作为主要进程通信的方式同其性能高也有关系,Binder只需要一次拷贝就能将A进程用户空间的数据为B进程所用。这里主要涉及两个点: Binder的map函数,会将内核空间直接与用户空间对应,用户空间可以直接访问内核空间的数据A进程的数据会被直接拷贝到B进程的内核空间(一次拷贝) #define BINDER_VM_SIZE ((1*1024*1024) - (4096 *2)) ProcessState::ProcessState() : mDriverFD(open_driver()) , mVMStart(MAP_FAILED) , mManagesContexts(false) , mBinderContextCheckFunc(NULL) , mBinderContextUserData(NULL) , mThreadPoolStarted(false) , mThreadPoolSeq(1){ if (mDriverFD >= 0) { .... // mmap the binder, providing a chunk of virtual address space to receive transactions. mVMStart = mmap(0, BINDER_VM_SIZE, PROT_READ, MAP_PRIVATE | MAP_NORESERVE, mDriverFD, 0); ... } } mmap函数属于系统调用,mmap会从当前进程中获取用户态可用的虚拟地址空间(vm_area_struct *vma),并在mmap_region中真正获取vma,然后调用file->f_op->mmap(file, vma),进入驱动处理,之后就会在内存中分配一块连续的虚拟地址空间,并预先分配好页表、已使用的与未使用的标识、初始地址、与用户空间的偏移等等,通过这一步之后,就能把Binder在内核空间的数据直接通过指针地址映射到用户空间,供进程在用户空间使用,这是一次拷贝的基础,一次拷贝在内核中的标识如下: struct binder_proc { struct hlist_node proc_node; // 四棵比较重要的树 struct rb_root threads; struct rb_root nodes; struct rb_root refs_by_desc; struct rb_root refs_by_node; int pid; struct vm_area_struct *vma; //虚拟地址空间,用户控件传过来 struct mm_struct *vma_vm_mm; struct task_struct *tsk; struct files_struct *files; struct hlist_node deferred_work_node; int deferred_work; void *buffer; //初始地址 ptrdiff_t user_buffer_offset; //这里是偏移 struct list_head buffers;//这个列表连接所有的内存块,以地址的大小为顺序,各内存块首尾相连 struct rb_root free_buffers;//连接所有的已建立映射的虚拟内存块,以内存的大小为index组织在以该节点为根的红黑树下 struct rb_root allocated_buffers;//连接所有已经分配的虚拟内存块,以内存块的开始地址为index组织在以该节点为根的红黑树下 } 上面只是在APP启动的时候开启的地址映射,但并未涉及到数据的拷贝,下面看数据的拷贝操作。当数据从用户空间拷贝到内核空间的时候,是直从当前进程的用户空间接拷贝到目标进程的内核空间,这个过程是在请求端线程中处理的,操作对象是目标进程的内核空间。看如下代码: static void binder_transaction(struct binder_proc *proc, struct binder_thread *thread, struct binder_transaction_data *tr, int reply){ ... 在通过进行binder事物的传递时,如果一个binder事物(用struct binder_transaction结构体表示)需要使用到内存, 就会调用binder_alloc_buf函数分配此次binder事物需要的内存空间。 需要注意的是:这里是从目标进程的binder内存空间分配所需的内存 //从target进程的binder内存空间分配所需的内存大小,这也是一次拷贝,完成通信的关键,直接拷贝到目标进程的内核空间 //由于用户空间跟内核空间仅仅存在一个偏移地址,所以也算拷贝到用户空间 t->buffer = binder_alloc_buf(target_proc, tr->data_size, tr->offsets_size, !reply && (t->flags & TF_ONE_WAY)); t->buffer->allow_user_free = 0; t->buffer->debug_id = t->debug_id; //该binder_buffer对应的事务 t->buffer->transaction = t; //该事物对应的目标binder实体 ,因为目标进程中可能不仅仅有一个Binder实体 t->buffer->target_node = target_node; trace_binder_transaction_alloc_buf(t->buffer); if (target_node) binder_inc_node(target_node, 1, 0, NULL); // 计算出存放flat_binder_object结构体偏移数组的起始地址,4字节对齐。 offp = (size_t *)(t->buffer->data + ALIGN(tr->data_size, sizeof(void *))); // struct flat_binder_object是binder在进程之间传输的表示方式 // // 这里就是完成binder通讯单边时候在用户进程同内核buffer之间的一次拷贝动作 // // 这里的数据拷贝,其实是拷贝到目标进程中去,因为t本身就是在目标进程的内核空间中分配的, if (copy_from_user(t->buffer->data, tr->data.ptr.buffer, tr->data_size)) { binder_user_error("binder: %d:%d got transaction with invalid " "data ptr\n", proc->pid, thread->pid); return_error = BR_FAILED_REPLY; goto err_copy_data_failed; } 可以看到binder_alloc_buf(target_proc, tr->data_size,tr->offsets_size, !reply && (t->flags & TF_ONE_WAY))函数在申请内存的时候,是从target_proc进程空间中去申请的,这样在做数据拷贝的时候copy_from_user(t->buffer->data, tr->data.ptr.buffer, tr->data_size)),就会直接拷贝target_proc的内核空间,而由于Binder内核空间的数据能直接映射到用户空间,这里就不在需要拷贝到用户空间。这就是一次拷贝的原理。内核空间的数据映射到用户空间其实就是添加一个偏移地址,并且将数据的首地址、数据的大小都复制到一个用户空间的Parcel结构体,具体可以参考Parcel.cpp的Parcel::ipcSetDataReference函数。 Binder传输数据的大小限制 虽然APP开发时候,Binder对程序员几乎不可见,但是作为Android的数据运输系统,Binder的影响是全面性的,所以有时候如果不了解Binder的一些限制,在出现问题的时候往往是没有任何头绪,比如在Activity之间传输BitMap的时候,如果Bitmap过大,就会引起问题,比如崩溃等,这其实就跟Binder传输数据大小的限制有关系,在上面的一次拷贝中分析过,mmap函数会为Binder数据传递映射一块连续的虚拟地址,这块虚拟内存空间其实是有大小限制的,不同的进程可能还不一样。 1024) - (4096 *2) :这个限制定义在ProcessState类中,如果传输说句超过这个大小,系统就会报错,因为Binder本身就是为了进程间频繁而灵活的通信所设计的,并不是为了拷贝大数据而使用的: define BINDER_VM_SIZE ((110241024) - (4096 *2)) 而在内核中,其实也有个限制,是4M,不过由于APP中已经限制了不到1M,这里的限制似乎也没多大用途: static int binder_mmap(struct file *filp, struct vm_area_struct *vma) { int ret; struct vm_struct *area; struct binder_proc *proc = filp->private_data; const char *failure_string; struct binder_buffer *buffer; //限制不能超过4M if ((vma->vm_end - vma->vm_start) > SZ_4M) vma->vm_end = vma->vm_start + SZ_4M; 。。。 } 有个特殊的进程ServiceManager进程,它为自己申请的Binder内核空间是128K,这个同ServiceManager的用途是分不开的,ServcieManager主要面向系统Service,只是简单的提供一些addServcie,getService的功能,不涉及多大的数据传输,因此不需要申请多大的内存: int main(int argc, char **argv) { struct binder_state *bs; void *svcmgr = BINDER_SERVICE_MANAGER; // 仅仅申请了128k bs = binder_open(128*1024); if (binder_become_context_manager(bs)) { ALOGE("cannot become context manager (%s)\n", strerror(errno)); return -1; } svcmgr_handle = svcmgr; binder_loop(bs, svcmgr_handler); return 0; } 系统服务与bindService等启动的服务的区别 服务可分为系统服务与普通服务,系统服务一般是在系统启动的时候,由SystemServer进程创建并注册到ServiceManager中的。而普通服务一般是通过ActivityManagerService启动的服务,或者说通过四大组件中的Service组件启动的服务。这两种服务在实现跟使用上是有不同的,主要从以下几个方面: 服务的启动方式服务的注册与管理服务的请求使用方式首先看一下服务的启动上,系统服务一般都是SystemServer进程负责启动,比如AMS,WMS,PKMS,电源管理等,这些服务本身其实实现了Binder接口,作为Binder实体注册到ServiceManager中,被ServiceManager管理,而SystemServer进程里面会启动一些Binder线程,主要用于监听Client的请求,并分发给响应的服务实体类,可以看出,这些系统服务是位于SystemServer进程中(有例外,比如Media服务)。在来看一下bindService类型的服务,这类服务一般是通过Activity的startService或者其他context的startService启动的,这里的Service组件只是个封装,主要的是里面Binder服务实体类,这个启动过程不是ServcieManager管理的,而是通过ActivityManagerService进行管理的,同Activity管理类似。 再来看一下服务的注册与管理:系统服务一般都是通过ServiceManager的addService进行注册的,这些服务一般都是需要拥有特定的权限才能注册到ServiceManager,而bindService启动的服务可以算是注册到ActivityManagerService,只不过ActivityManagerService管理服务的方式同ServiceManager不一样,而是采用了Activity的管理模型,详细的可以自行分析 最后看一下使用方式,使用系统服务一般都是通过ServiceManager的getService得到服务的句柄,这个过程其实就是去ServiceManager中查询注册系统服务。而bindService启动的服务,主要是去ActivityManagerService中去查找相应的Service组件,最终会将Service内部Binder的句柄传给Client。 Binder线程、Binder主线程、Client请求线程的概念与区别 Binder线程是执行Binder服务的载体,只对于服务端才有意义,对请求端来说,是不需要考虑Binder线程的,但Android系统的处理机制其实大部分是互为C/S的。比如APP与AMS进行交互的时候,都互为对方的C与S,这里先不讨论这个问题,先看Binder线程的概念。 Binder线程就是执行Binder实体业务的线程,一个普通线程如何才能成为Binder线程呢?很简单,只要开启一个监听Binder字符设备的Loop线程即可,在Android中有很多种方法,不过归根到底都是监听Binder,换成代码就是通过ioctl来进行监听。 拿ServerManager进程来说,其主线就是Binder线程,其做法是通过binder_loop实现不死线程: void binder_loop(struct binder_state *bs, binder_handler func) { ... for (;;) { <!--关键点1--> res = ioctl(bs->fd, BINDER_WRITE_READ, &bwr); <!--关键点2--> res = binder_parse(bs, 0, readbuf, bwr.read_consumed, func); 。。 } } 上面的关键代码1就是阻塞监听客户端请求,2 就是处理请求,并且这是一个死循环,不退出。再来看SystemServer进程中的线程,在Android4.3(6.0以后打代码就不一样了)中SystemSever主线程便是Binder线程,同时一个Binder主线程,Binder线程与Binder主线程的区别是:线程是否可以终止Loop,不过目前启动的Binder线程都是无法退出的,其实可以全部看做是Binder主线程,其实现原理是,在SystemServer主线程执行到最后的时候,Loop监听Binder设备,变身死循环线程,关键代码如下: extern "C" status_t system_init() { ... ALOGI("System server: entering thread pool.\n"); ProcessState::self()->startThreadPool(); IPCThreadState::self()->joinThreadPool(); ALOGI("System server: exiting thread pool.\n"); return NO_ERROR; } ProcessState::self()->startThreadPool()是新建一个Binder主线程,而PCThreadState::self()->joinThreadPool()是将当前线程变成Binder主线程。其实startThreadPool最终也会调用joinThreadPool,看下其关键函数: void IPCThreadState::joinThreadPool(bool isMain) { ... status_t result; do { int32_t cmd; ...关键点1 result = talkWithDriver(); if (result >= NO_ERROR) { ...关键点2 result = executeCommand(cmd); } // 非主线程的可以退出 if(result == TIMED_OUT && !isMain) { break; } // 死循环,不完结,调用了这个,就好比是开启了Binder监听循环, } while (result != -ECONNREFUSED && result != -EBADF); } status_t IPCThreadState::talkWithDriver(bool doReceive) { do { ...关键点3 if (ioctl(mProcess->mDriverFD, BINDER_WRITE_READ, &bwr) >= 0) } 先看关键点1 talkWithDriver,其实质还是去掉用ioctl(mProcess->mDriverFD, BINDER_WRITE_READ, &bwr) >= 0)去不断的监听Binder字符设备,获取到Client传输的数据后,再通过executeCommand去执行相应的请求,joinThreadPool是普通线程化身Binder线程最常见的方式。不信,就再看一个MediaService,看一下main_mediaserver的main函数: int main(int argc, char** argv) { 。。。 sp<ProcessState> proc(ProcessState::self()); sp<IServiceManager> sm = defaultServiceManager(); ALOGI("ServiceManager: %p", sm.get()); AudioFlinger::instantiate(); MediaPlayerService::instantiate(); CameraService::instantiate(); AudioPolicyService::instantiate(); registerExtensions(); ProcessState::self()->startThreadPool(); IPCThreadState::self()->joinThreadPool(); } 其实还是通过joinThreadPool变身Binder线程,至于是不是主线程,看一下下面的函数: void IPCThreadState::joinThreadPool(bool isMain) void ProcessState::spawnPooledThread(bool isMain) { if (mThreadPoolStarted) { String8 name = makeBinderThreadName(); ALOGV("Spawning new pooled thread, name=%s\n", name.string()); sp<Thread> t = new PoolThread(isMain); t->run(name.string()); } } 其实关键就是就是传递给joinThreadPool函数的isMain是否是true,不过是否是Binder主线程并没有什么用,因为源码中并没有为这两者的不同处理留入口,感兴趣可以去查看一下binder中的TIMED_OUT。 最后来看一下普通Client的binder请求线程,比如我们APP的主线程,在startActivity请求AMS的时候,APP的主线程成其实就是Binder请求线程,在进行Binder通信的过程中,Client的Binder请求线程会一直阻塞,知道Service处理完毕返回处理结果。 Binder请求的同步与异步 很多人都会说,Binder是对Client端同步,而对Service端异步,其实并不完全正确,在单次Binder数据传递的过程中,其实都是同步的。只不过,Client在请求Server端服务的过程中,是需要返回结果的,即使是你看不到返回数据,其实还是会有个成功与失败的处理结果返回给Client,这就是所说的Client端是同步的。至于说服务端是异步的,可以这么理解:在服务端在被唤醒后,就去处理请求,处理结束后,服务端就将结果返回给正在等待的Client线程,将结果写入到Client的内核空间后,服务端就会直接返回了,不会再等待Client端的确认,这就是所说的服务端是异步的,可以从源码来看一下: Client端同步阻塞请求 status_t IPCThreadState::transact(int32_t handle, uint32_t code, const Parcel& data, Parcel* reply, uint32_t flags) { if (reply) { err = waitForResponse(reply); } ... Client在请求服务的时候 Parcel* reply基本都是非空的(还没见过空用在什么位置),非空就会执行waitForResponse(reply),如果看过几篇Binder分析文章的人应该都会知道,在A端向B写完数据之后,A会返回给自己一个BR_TRANSACTION_COMPLETE命令,告知自己数据已经成功写入到B的Binder内核空间中去了,如果是需要回复,在处理完BR_TRANSACTION_COMPLETE命令后会继续阻塞等待结果的返回: status_t IPCThreadState::waitForResponse(Parcel *reply, status_t *acquireResult){ ... while (1) { if ((err=talkWithDriver()) < NO_ERROR) break; cmd = mIn.readInt32(); switch (cmd) { <!--关键点1 --> case BR_TRANSACTION_COMPLETE: if (!reply && !acquireResult) goto finish; break; <!--关键点2 --> case BR_REPLY: { binder_transaction_data tr; // free buffer,先设置数据,直接 if (reply) { if ((tr.flags & TF_STATUS_CODE) == 0) { // 牵扯到数据利用,与内存释放 reply->ipcSetDataReference(...) } goto finish; } finish: ... return err; } 关键点1就是处理BR_TRANSACTION_COMPLETE,如果需要等待reply,还要通过talkWithDriver等待结果返回,最后执行关键点2,处理返回数据。对于服务端来说,区别就在于关键点1 ,来看一下服务端Binder线程的代码,拿常用的joinThreadPool来看,在talkWithDriver后,会执行executeCommand函数, void IPCThreadState::joinThreadPool(bool isMain) { ... status_t result; do { int32_t cmd; ...关键点1 result = talkWithDriver(); if (result >= NO_ERROR) { ...关键点2 result = executeCommand(cmd); } // 非主线程的可以退出 if(result == TIMED_OUT && !isMain) { break; } // 死循环,不完结,调用了这个,就好比是开启了Binder监听循环, } while (result != -ECONNREFUSED && result != -EBADF); } executeCommand会进一步调用sendReply函数,看一下这里的特点waitForResponse(NULL, NULL),这里传递的都是null,在上面的关键点1的地方我们知道,这里不需要等待Client返回,因此会直接 goto finish,这就是所说的Client同步,而服务端异步的逻辑。 // BC_REPLY status_t IPCThreadState::sendReply(const Parcel& reply, uint32_t flags) { // flag 0 status_t err; status_t statusBuffer; err = writeTransactionData(BC_REPLY, flags, -1, 0, reply, &statusBuffer); if (err < NO_ERROR) return err; return waitForResponse(NULL, NULL); } case BR_TRANSACTION_COMPLETE: if (!reply && !acquireResult) goto finish; break; 请求同步最好的例子就是在Android6.0之前,国产ROM权限的申请都是同步的,在申请权限的时候,APP申请权限的线程会阻塞,就算是UI线程也会阻塞,ROM为了防止ANR,都会为权限申请设置一个倒计时,不操作,就给个默认操作,有兴趣可以自己分析。 Android APP进程天生支持Binder通信的原理是什么 Android APP进程都是由Zygote进程孵化出来的。常见场景:点击桌面icon启动APP,或者startActivity启动一个新进程里面的Activity,最终都会由AMS去调用Process.start()方法去向Zygote进程发送请求,让Zygote去fork一个新进程,Zygote收到请求后会调用Zygote.forkAndSpecialize()来fork出新进程,之后会通过RuntimeInit.nativeZygoteInit来初始化Andriod APP运行需要的一些环境,而binder线程就是在这个时候新建启动的,看下面的源码(Android 4.3): 这里不分析Zygote,只是给出其大概运行机制,Zygote在启动后,就会通过runSelectLoop不断的监听socket,等待请求来fork进程,如下: private static void runSelectLoop() throws MethodAndArgsCaller { ArrayList<FileDescriptor> fds = new ArrayList<FileDescriptor>(); ArrayList<ZygoteConnection> peers = new ArrayList<ZygoteConnection>(); FileDescriptor[] fdArray = new FileDescriptor[4]; ... int loopCount = GC_LOOP_COUNT; while (true) { int index; ... boolean done; done = peers.get(index).runOnce(); ... }}} 每次fork请求到来都会调用ZygoteConnection的runOnce()来处理请求, boolean runOnce() throws ZygoteInit.MethodAndArgsCaller { String args[]; Arguments parsedArgs = null; FileDescriptor[] descriptors; 。。。 try { ...关键点1 pid = Zygote.forkAndSpecialize(parsedArgs.uid, parsedArgs.gid, parsedArgs.gids, parsedArgs.debugFlags, rlimits, parsedArgs.mountExternal, parsedArgs.seInfo, parsedArgs.niceName); } try { if (pid == 0) { // in child ...关键点2 handleChildProc(parsedArgs, descriptors, childPipeFd, newStderr); 。。。 } runOnce()有两个关键点,关键点1 Zygote.forkAndSpecialize就是通过fork系统调用来新建进程,关键点2 handleChildProc就是对新建的APP进程进行一些初始化工作,为Android Java进程创建一些必须的场景。Zygote.forkAndSpecialize没什么可看的,就是Linux中的fork进程,这里主要看一下handleChildProc private void handleChildProc(Arguments parsedArgs, FileDescriptor[] descriptors, FileDescriptor pipeFd, PrintStream newStderr) throws ZygoteInit.MethodAndArgsCaller { //从Process.start启动的parsedArgs.runtimeInit一般都是true if (parsedArgs.runtimeInit) { if (parsedArgs.invokeWith != null) { WrapperInit.execApplication(parsedArgs.invokeWith, parsedArgs.niceName, parsedArgs.targetSdkVersion, pipeFd, parsedArgs.remainingArgs); } else { // Android应用启动都走该分支 RuntimeInit.zygoteInit(parsedArgs.targetSdkVersion, parsedArgs.remainingArgs); } } 接着看 RuntimeInit.zygoteInit函数 public static final void zygoteInit(int targetSdkVersion, String[] argv) throws ZygoteInit.MethodAndArgsCaller { redirectLogStreams(); commonInit(); <!--关键点1--> nativeZygoteInit(); <!--关键点2--> applicationInit(targetSdkVersion, argv); } 先看关键点1,nativeZygoteInit属于Native方法,该方法位于AndroidRuntime.cpp中,其实就是调用调用到app_main.cpp中的onZygoteInit static void com_android_internal_os_RuntimeInit_nativeZygoteInit(JNIEnv* env, jobject clazz) { gCurRuntime->onZygoteInit(); } 关键就是onZygoteInit virtual void onZygoteInit() { sp proc = ProcessState::self(); //启动新binder线程loop proc->startThreadPool(); } 首先,ProcessState::self()函数会调用open()打开/dev/binder设备,这个时候Client就能通过Binder进行远程通信;其次,proc->startThreadPool()负责新建一个binder线程,监听Binder设备,这样进程就具备了作为Binder服务端的资格。每个APP的进程都会通过onZygoteInit打开Binder,既能作为Client,也能作为Server,这就是Android进程天然支持Binder通信的原因。 Android APP有多少Binder线程,是固定的么? 通过上一个问题我们知道了Android APP线程为什么天然支持Binder通信,并且可以作为Binder的Service端,同时也对Binder线程有了一个了解,那么在一个Android APP的进程里面究竟有多少个Binder线程呢?是固定的吗。在分析上一个问题的时候,我们知道Android APP进程在Zygote fork之初就为它新建了一个Binder主线程,使得APP端也可以作为Binder的服务端,这个时候Binder线程的数量就只有一个,假设我们的APP自身实现了很多的Binder服务,一个线程够用的吗?这里不妨想想一下SystemServer进程,SystemServer拥有很多系统服务,一个线程应该是不够用的,如果看过SystemServer代码可能会发现,对于Android4.3的源码,其实一开始为该服务开启了两个Binder线程。还有个分析Binder常用的服务,media服务,也是在一开始的时候开启了两个线程。 先看下SystemServer的开始加载的线程:通过 ProcessState::self()->startThreadPool()新加了一个Binder线程,然后通过IPCThreadState::self()->joinThreadPool();将当前线程变成Binder线程,注意这里是针对Android4.3的源码,android6.0的这里略有不同。 extern "C" status_t system_init() { ... ALOGI("System server: entering thread pool.\n"); ProcessState::self()->startThreadPool(); IPCThreadState::self()->joinThreadPool(); ALOGI("System server: exiting thread pool.\n"); return NO_ERROR; } 再看下Media服务,同SystemServer类似,也是开启了两个Binder线程: int main(int argc, char** argv) { ... ProcessState::self()->startThreadPool(); IPCThreadState::self()->joinThreadPool(); } 可以看出Android APP上层应用的进程一般是开启一个Binder线程,而对于SystemServer或者media服务等使用频率高,服务复杂的进程,一般都是开启两个或者更多。来看第二个问题,Binder线程的数目是固定的吗?答案是否定的,驱动会根据目标进程中是否存在足够多的Binder线程来告诉进程是不是要新建Binder线程,详细逻辑,首先看一下新建Binder线程的入口: status_t IPCThreadState::executeCommand(int32_t cmd) { BBinder* obj; RefBase::weakref_type* refs; status_t result = NO_ERROR; switch (cmd) { ... // 可以根据内核返回数据创建新的binder线程 case BR_SPAWN_LOOPER: mProcess->spawnPooledThread(false); break; } executeCommand一定是从Bindr驱动返回的BR命令,这里是BR_SPAWN_LOOPER,什么时候,Binder驱动会向进程发送BR_SPAWN_LOOPER呢?全局搜索之后,发现只有一个地方binder_thread_read,如果直观的想一下,什么时候需要新建Binder线程呢?很简单,不够用的时候,注意上面使用的是spawnPooledThread(false),也就是说这里启动的都是普通Binder线程。为了了解启动时机,先看一些binder_proc内部判定参数的意义: struct binder_proc { ... int max_threads; // 进程所能启动的最大非主Binder线程数目 int requested_threads; // 请求启动的非主线程数 int requested_threads_started;//已经启动的非主线程数 int ready_threads; // 当前可用的Binder线程数 ... }; 再来看binder_thread_read函数中是么时候会去请求新建Binder线程,以Android APP进程为例子,通过前面的分析知道APP进程天然支持Binder通信,因为它有一个Binder主线程,启动之后就会阻塞等待Client请求,这里会更新proc->ready_threads,第一次阻塞等待的时候proc->ready_threads=1,之后睡眠。 binder_thread_read(){ ... retry: //当前线程todo队列为空且transaction栈为空,则代表该线程是空闲的 ,看看是不是自己被复用了 wait_for_proc_work = thread->transaction_stack == NULL && list_empty(&thread->todo); ...//可用线程个数+1 if (wait_for_proc_work) proc->ready_threads++; binder_unlock(__func__); if (wait_for_proc_work) { ... //当进程todo队列没有数据,则进入休眠等待状态 ret = wait_event_freezable_exclusive(proc->wait, binder_has_proc_work(proc, thread)); } else { if (non_block) { ... } else //当线程todo队列没有数据,则进入休眠等待状态 ret = wait_event_freezable(thread->wait, binder_has_thread_work(thread)); } binder_lock(__func__); //被唤醒可用线程个数-1 if (wait_for_proc_work) proc->ready_threads--; thread->looper &= ~BINDER_LOOPER_STATE_WAITING; ... while (1) { uint32_t cmd; struct binder_transaction_data tr; struct binder_work *w; struct binder_transaction *t = NULL; //先考虑从线程todo队列获取事务数据 if (!list_empty(&thread->todo)) { w = list_first_entry(&thread->todo, struct binder_work, entry); //线程todo队列没有数据, 则从进程todo对获取事务数据 } else if (!list_empty(&proc->todo) && wait_for_proc_work) { w = list_first_entry(&proc->todo, struct binder_work, entry); } else { } .. if (t->buffer->target_node) { cmd = BR_TRANSACTION; //设置命令为BR_TRANSACTION } else { cmd = BR_REPLY; //设置命令为BR_REPLY } .. done: *consumed = ptr - buffer; //创建线程的条件 if (proc->requested_threads + proc->ready_threads == 0 && proc->requested_threads_started < proc->max_threads && (thread->looper & (BINDER_LOOPER_STATE_REGISTERED | BINDER_LOOPER_STATE_ENTERED))) { //需要新建的数目线程数+1 proc->requested_threads++; // 生成BR_SPAWN_LOOPER命令,用于创建新的线程 put_user(BR_SPAWN_LOOPER, (uint32_t __user *)buffer); } return 0; } 被Client唤醒后proc->ready_threads会-1,之后变成0,这样在执行到done的时候,就会发现proc->requested_threads + proc->ready_threads == 0,这是新建Binder线程的一个必须条件,再看下其他几个条件 if (proc->requested_threads + proc->ready_threads == 0 && proc->requested_threads_started < proc->max_threads && (thread->looper & (BINDER_LOOPER_STATE_REGISTERED | BINDER_LOOPER_STATE_ENTERED))) proc->requested_threads + proc->ready_threads == 0 :如果目前还没申请新建Binder线程,并且proc->ready_threads空闲Binder线程也是0,就需要新建一个Binder线程,其实就是为了保证有至少有一个空闲的线程。 proc->requested_threads_started < proc->max_threads:目前启动的普通Binder线程数requested_threads_started还没达到上限(默认APP进程是15) thread->looper & (BINDER_LOOPER_STATE_REGISTERED | BINDER_LOOPER_STATE_ENTERED) 当先线程是Binder线程,这个是一定满足的,不知道为什么列出来 proc->max_threads是多少呢?不同的进程其实设置的是不一样的,看普通的APP进程,在ProcessState::self()新建ProcessState单利对象的时候会调用ioctl(fd, BINDER_SET_MAX_THREADS, &maxThreads);设置上限,可以看到默认设置的上限是15。 static int open_driver() { int fd = open("/dev/binder", O_RDWR); ... size_t maxThreads = 15; result = ioctl(fd, BINDER_SET_MAX_THREADS, &maxThreads); ... } 如果满足新建的条件,就会将proc->requested_threads加1,并在驱动执行完毕后,利用put_user(BR_SPAWN_LOOPER, (uint32_t __user *)buffer);通知服务端在用户空间发起新建Binder线程的操作,新建的是普通Binder线程,最终再进入binder_thread_write的BC_REGISTER_LOOPER: int binder_thread_write(struct binder_proc *proc, struct binder_thread *thread, void __user *buffer, int size, signed long *consumed) { ... case BC_REGISTER_LOOPER: ... // requested_threads -- proc->requested_threads--; proc->requested_threads_started++; } } 这里会将proc->requested_threads复原,其实就是-1,并且启动的Binder线程数+1。 个人理解,之所以采用动态新建Binder线程的意义有两点,第一:如果没有Client请求服务,就保持线程数不变,减少资源浪费,需要的时候再分配新线程。第二:有请求的情况下,保证至少有一个空闲线程是给Client端,以提高Server端响应速度。 不过这里有一点要注意,对于同一个线程的请求,如果是阻塞的,那么没什么问题,肯定是等待上一个请求结束才能处理下一个,但是对于oneway方式的binder请求呢,这里就会存在这么一个场景,对于oneway的请求,如果上一个还没处理完,同一个线程的新的oneway请求会被塞到同一个目标线程等待执行,而不会触发创建新的Binder线程,因为这并不会妨碍另一端的处理,因为它压根无需等待,但是这可能会造成服务端单个线程任务繁重,而其他线程保持空闲,不过在一定程度上实现了同一种任务的顺序执行,可能也有一定的好处吧。 原文发布时间为:2018-07-18本文作者:看书的小蜗牛本文来自云栖社区合作伙伴“安卓巴士Android开发者门户”,了解相关信息可以关注“安卓巴士Android开发者门户”。