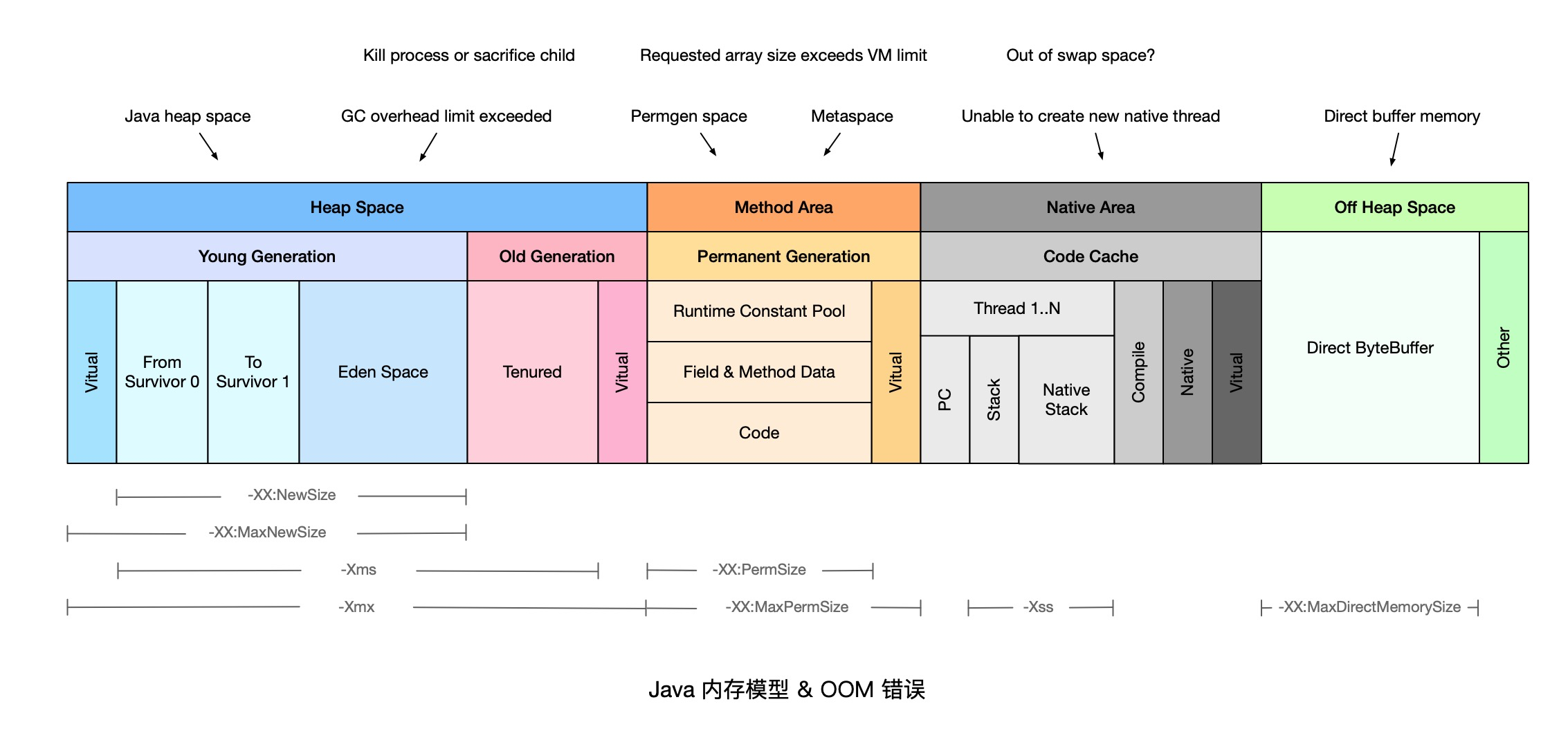
系统稳定性——OutOfMemoryError 常见原因及解决方法
作者:涯海 创作日期:2019-07-15 专栏地址:【稳定大于一切】 当 JVM 内存严重不足时,就会抛出 java.lang.OutOfMemoryError 错误。本文总结了常见的 OOM 原因及其解决方法,如下图所示。如有遗漏或错误,欢迎补充指正。 如果对 JVM 内存模型和垃圾回收机制不熟悉,推荐阅读 《咱们从头到尾说一次 Java 垃圾回收》。 目录 Java heap space GC overhead limit exceeded Permgen space Metaspace Unable to create new native thread Out of swap space? Kill process or sacrifice child Requested array size exceeds VM limit Direct