kettle学习笔记及最佳实践
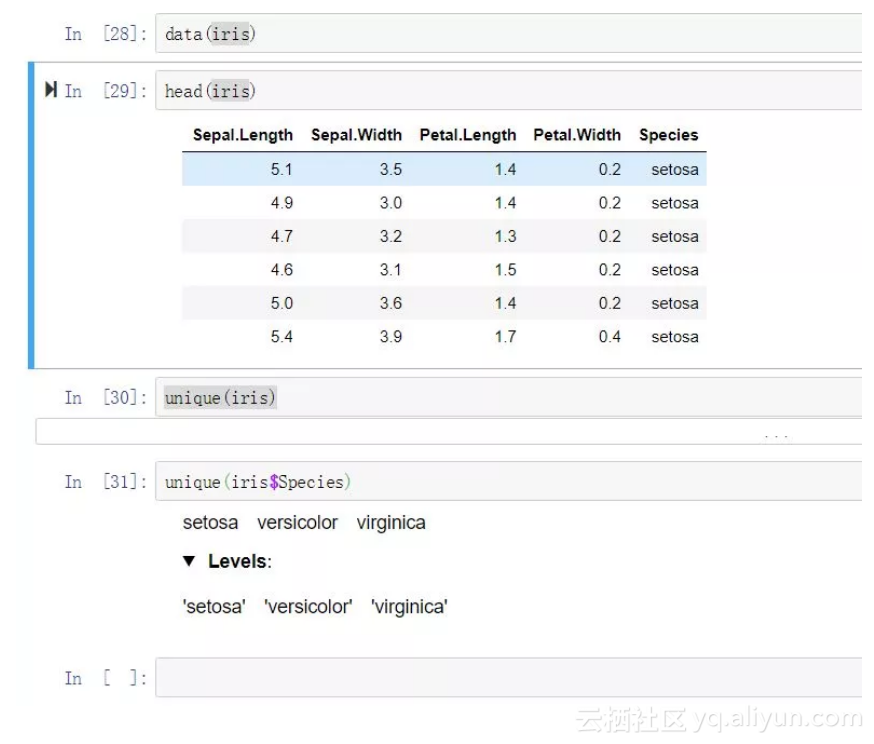
最近在用kettle迁移数据,从对kettle一点不会到比较熟悉,对于期间的一些问题和坑做了记录和总结,内容涵盖了使用的经验和技巧,踩到的坑、最佳实践和优化前后结果对比。 常用转换组件 计算形成新字段:只限算术运算,并且选择固定 过滤记录:元表某字段按照某个条件分流,满足条件的到一个表,不满足的到另一个表,这两个目标表都必须有。 Switch/Case:和过滤记录类似,可以多个条件判断,并且有默认转向条件,可以完美替换过滤记录组建 记录分组:group by 组建未能正常按照预期理解运行 设置为NULL:将某个特定值设置为NULL 行扁平化:行扁平化,使用与某条件下某名称对应的行数相同的情况 行列转换:行转成列,使用Row Normalizer组件,事先一定要是根据分组字段排好序,关键字段就是name列字段,分组字段就是按照什么分组,目标字段就是行转列之后形成的字段列表。 8.字段选择:选择需要的目的列到目标表,并且量表的对应字段不一样时可以用来做字段映射 排序:分组前先排序可以提高效率 条件分发:根据条件分发,相当与informatica的router组件 值映射:相当与oracle的decode函数,源和目标字段同名的话,只要写源字段就可以了 #常用输入组件 表输入:源表输入 文本文件输入:文本文件输入 xml文件输入:使用Get Data From XML组件,可以在其中使用xpath来选择数据 JsonInput:貌似在中文环境下组件面板里看不到,切换到英文模式就看到了 #常用输出组件 表输出:表输出 文本文件输出:文本文件输出 XML文件输出:输出的XML文件是按照记录行存储的,字段名为元素名 Excel文件输出:输出的excel文件是按照记录行存储的,字段名为元素名 删除:符合比较条件的记录将删除 更新:注意两个表都要有主键才可以 插入/更新:速度太慢,不建议使用 检查字段是否存在:若在则家一个标志位,值可以是Y/N 等值连接:有关联关系字段可以关联,其它的不关联。 笛卡尔连接:所有两边的记录交叉连接 write to log:把数据输出到控制台日志里,一般调试时很常用 空操作:很常用,比如过滤数据,未过滤走正常流程,滤除的数据就转向空操作。我喜欢在转换里用它做开始和结束之类需要分发或汇聚数据流的场景 #内置变量 Internal.Transformation.Name 当前转换的名字 Internal.Job.Name 当前job名字 Internal.Job.Filename.Name job的文件名 #需要修改的配置 在java8里-XX:MaxPermSize,-XX:PermSize已经去掉了,需要修改成-XX:MetaspaceSize 和 -XX:MaxMetaspaceSize 生产环境和开发环境使用不同的数据库连接 ~/.kettle/kettle.properties里设置key=value 在kettle.properties中添加变量,然后在类似数据库连接的地方可以用${key}来使用,这样可以实现开发环境和生产环境配置的差异,就算往资源库里提交也可以互不影响了 kettle分页问题 kettle循环分页 首先弄一个转换A,根据源表获取记录数,页数,每页记录数,然后写入系统变量,然后在job里调用转换A,再加一个转换B来迁移数据(其中查询sql要使用转换A生成的系统变量),最后在job里用一个javascript脚本来判断查询记录数是否是0,如果是0就走执行成功,否则就继续执行转换B。 最关键的是判断的js脚本,可以参考 var prevRow=previous_result.getRows();//获取上一个传递的结果,这种方案需要在转换B中将记录集复制为结果,如果记录集较多会造成内存溢出。就算在job里执行也是如此 完整代码: if (prevRow==null && prevRow.size()==0){ false; }else{ var startRow=parseInt(parent_job.getVariable("START_ROW", 0)); var pageSize=parseInt(parent_job.getVariable("PAGE_SIZE",1000)); startRow=startRow+pageSize; parent_job.setVariable("START_ROW", startRow); true; } kettle分页循环的更高效的改进方案 在转换里,每执行一次有个SUCC_COUNT环境变量就+1,在job中用js脚本判断成功数是否>=总记录数,是就终止循环,否就起始行+每页记录数,下面是代码 var startRow=parseInt(parent_job.getVariable("startrow")); var totalItemCount=parseInt(parent_job.getVariable("totalitemcount")); if (startRow >= totalItemCount){ false; }else{ true; } 对比前一种方案,改进方案一次迁移一万条数据没有压力,而且cpu稳定在20%以下。 参数和变量 全局变量参数 在kettle.properties中配置,通过获取环境变量组件来读取,一般用来做数据库连接配置等 位置参数(arguments参数) 最多支持10个,通过命令行参数的位置来区别,不是太好用 命名参数(named params) 通过 -param:name=value的方式设置参数,如果传多个参数需要 -param:name1:value1 -param:name2:value2 配置方法 在转换中双击空白处添加命名参数arg3,arg4,用的时候可以 ${arg3},${arg4}来使用,注意:如果不直接执行转换就不要配置转换命名参数(转换的命名参数和全局参数在调试时有时候会出现莫名其妙的冲突),建议使用全局参数来替代 在job中双击转换,切换到命名参数页,点击获取参数(arg3和arg4会出现到列表里)注意:在使用全局参数的时候这步可以省略 在job中双击空白处添加命名参数arg3,arg4,然后在调用kitchen.sh时通过 -param:arg3=abc -param:arg4=def来使用,注意:-param传递的命名参数一定要在job中事先定义才可以。 命名参数可以做变量使用,即${var}的方式来调用,如果是日期这样必须包含'的场景,可以用-param:date="2018-1-1 0:0:0"来表示,在sql里用'${var}'来表示 kitchen常用命令 命令行执行job(repository模式) ./kitchen.sh -listrep kitchen.sh -rep=<respository名字> -user=<respository登录用户名> -pass=<respository密码> -level=<日志级别> -job=<job名字> -logfile=<日志文件路径> kitchen.sh -rep=olpbdb01 -user=admin -pass=admin -level=Basic -dir=/demo1 -job=demo1 //会执行repository上 /demo1/demo1.kjb 命令行执行job(文件模式) kitchen.sh -file=/home/job/demo.kjb >> /home/job/log/demo.log 命令行执行转换(respository模式) pan.sh -rep=mysql -user=admin -pass=admin -dir=/fixbug -trans=f_loan_update -level=Basic -logfile=/data/kettle.log 命令行执行转换(文件模式) pan.sh -file /data/kettle/demo1/t_test_rep_mysql.ktr 三种增量同步的模式 时间戳增量同步:表中增加一个时间戳字段,每次更新值查询update_time>上次更新时间的记录。优点速度快,实现简单,缺点是对数据库有侵入性,对于业务系统也需要更新时间戳,增加了复杂性。 触发器增量同步:使用触发器来监控数据变化,对数据库有侵入性并且实现难度较大 全表增量同步:主要是用合并记录来比对,优点是数据库侵入较小,实现简单,缺点是性能较差。 个人观点是全表比对要好一点,如果按照分页的方式的化,二十几万条数据20分钟可以全同步完成。但全表增量同步只适合对实时性要求不高的场景。 几个常用组件的用途 1.字段选择:比如上一步骤有10个字段,下一步骤需要对其中某个字段做处理,就用字段选择来选择那个字段。还有,如果要合并记录,也会在数据流中使用字段选择选择一下字段。还有就是字段选择自带删除字段和修改字段类型和格式的功能 2.写日志:在处理数据时用写日志组建来记录logger是个不错的方法。 3.Switch/Case:和合并记录配合使用可以实现增量的数据插入/更新和删除。用过滤记录也可以实现同样功能 4.表输出:实际就是向表里insert数据,里面有个[返回自动产生的关键字]功能很好用,相当与insert后立刻查询的到刚刚自增的ID,省去了一部查询操作。 5.更新,删除:和名字一个意思 6.空操作:这个也很有用。 7.记录集连接:类似sql中的join操作,把两个数据流的字段(类型相同,列数相同,位置相同且已经排序过)拼合到一起。 8.分组:类似sql里的group by,构成分组的字段是分组条件(如果没有组可分但又要把每一行的数据都拼成一个串,可以不设置分组条件),聚合部分的字段是类似在select部分需要用聚合函数处理的字段。在拼合in 条件时很有用。 9.javascript脚本:这个不好用,能不用就不要用了。javascript组件支持将js变量转成输出字段。注意在转换里js脚本是每行执行一次。 10.获取变量:如果有外部传入的命名参数或者有环境变量,最好获取变量是做为流程的起点来使用。 11.设置变量:把某个字段转成变量时可以用。 12.表输入 12.1.一般提供一个复杂的sql查询,而且如果表输入需要参数,那么前一步骤一定是个获取变量。 12.2.如果需要实现动态sql(即拼一个sql存入变量A,然后在表输入里执行${A}),必须用两个转换实现。 12.3.如果需要实现每行查询一次(尽量避免这样做,太慢),可以在表输入中选中从步骤插入数据,并勾选执行每一行,在表输入的前一个步骤使用选择选择表输入的参数,在表输入中用占位符?来表示字段选择中选择的字段。 12.4.如果有可能,尽量一次性的用表输入完成所有的各类计算,转换,排序,而尽量避免使用kettle自带组件,因为这样速度快。 13.映射 13.1.可以在转换里调用另一个转换,转换中通过映射输入规范来接收入参数(实际就是个表记录集,在输入规范里定义的都是字段),用映射输出规范来定义输出数据集。这样整个映射就可以作为一个步骤整合到一个转换里(有输入和输出)。映射可以实现转换流程逻辑的复用。 13.2..关于在同一个转换的不同步骤中先修改变量然后再获取变量(取得的是转换刚开始执行时的值)不正确的问题,官方是这样解释的,在转换开始时会有一些变量初始化,初始化之后一些转换中的步骤并不是顺次执行的,所以无法做到同一个转换中在一个步骤。对于这种情况需要拆成两个抓换,先定义和初始化变量,然后再另一个转换中获取变量,需要注意的是,如果是转换中定义变量在子映射的获取的话也是不行的。 14.执行结果里面的Preview data非常好用,可以跑起来查看每个步骤的处理结果,如果发现一个步骤有数据,下一个步骤没数据了,那么可能是有问题了。 15.对于执行时有错误的情况,最好采用一张表来存储执行除错的数据,这对于无人职守迁移数据很重要。可以做成一个子转换来实现功能的复用。 16.对于javascript的调试,最好使用第三方的js开发工具来做,kettle自带的js编辑器太垃圾了。 17.合并记录时总是报NullPointerException,原因是合并记录的两个来源可能有不存在的情况,也可能是两个数据来源的排序不一致 18.转换的配置里的日志可以在线上部署的时候先禁用掉,有问题的时候可以再打开(通过点击连接线) kettle的最佳实践 启动时 kettle不能加入到PATH里去,加了执行 kitchen.sh -listrep找不到资源库 在~/.kettle里有重要的kettle.properties和repositories.xml文件,服务器部署的时候需要拷贝上去 spoon图形界面一般用来调试,跑多条数据会很慢 个人认为文件模式比repository模式好用点,repository模式总是莫名其妙的出问题,并且repository无法保留变更历史,但文件模式+git就可以做到 Unable to get module class path. (java.lang.RuntimeException: Unable to open JAR file, probably deleted: error in opening zip file) 需要删掉 <kettle_home>/system/karaf/caches/下的所有文件 启动时闪退时需要删掉~/.kettle/db.cache打头的文件就可以了。 防内存溢出和提高性能的处理办法 数据量较大时一定要使用分页机制,控制每个批次导入5000~10000 需要在分页循环中首先用一个独立的转换来计算出当前批次的用户ID数组,页码数量,总记录数以及维度表的数据,比如有日期维度表,那么就需要算出当前批次要处理的日期时间数组,最后把这些数据存入到全局变量里面去。这样在后续步骤就可以取出这些全局变量内容按照分页批次进行迁移了。 2.分页要通过一个表输入根据传入的每页记录数动态计算出总页数,并把总页数,总记录数存入全局变量,然后每处理一行计数器加1,截止条件就是总记录数<=处理过的记录数,从而实现的分页循环。 分页变量务必要通过命名参数-param来传递,这样在生产环境万一碰到了数据过大造成内存泄漏,可以通过参数快速调整 分页需要动态在模型中计算出页码数和总记录数,可以用个sql来搞定 select count(1) totalitemcount, round(CEIL(count(1)/${pagesize})) pagecount from table_name where create_time between unix_timestamp('${startdate}') and unix_timestamp('${enddate}') 之后的结果(totalitemcount,pagecount)用设置变量组件存入变量里就ok了 5. 注意数据量较大时不要使用记录复制到结果组件,不然一定会内存溢出 6. kettle的很多功能都有对应的纯sql实现方法,比如加字段,比如排序和空值的处理,纯sql的实现方式要比kettle的方式快很多,而且对内存的消耗也会小很多。 7. 可以设置几个变量来优化性能 KETTLE_MAX_LOG_SIZE_IN_LINES=5000 #内存里最多记录多少行日志 KETTLE_MAX_LOG_TIMEOUT_IN_MINUTES=1440 #kettle日志的保留时间,单位是分钟 KETTLE_MAX_JOB_ENTRIES_LOGGED=1000 #内存中保留多少实体返回结果日志 KETTLE_MAX_JOB_TRACKER_SIZE=1000 #内存里最多保留多少job跟踪记录 KETTLE_MAX_LOGGING_REGISTRY_SIZE=1000 #内存里记录多少实体 来优化内使用情况(在~/.kettle/kettle.properties里设置) 迁移模型的设计原则 整个模型必须是job+多个转换(除非是一次性工作可以没有job) job可以认为是表级处理(即一次处理多行,所有组件都是对于多行的处理组件),转换可以认为是行级处理(即一次处理一行,所有组件都是一次一行) 转换分两组,初始化变量用的转换(至少有一个,也可能有多个,主看是否有新变量,因为新变量无法在同一个转换里使用),和迁移数据用的转换(看情况,一般一个就够了) 命名参数的选择,即通过-param:varname=value的参数,一般需要有startdate,enddate,startrow,pagesize几个就够了 迁移的模式一般来说需要一个独立的转换根据日期区间计算出本次需要处理的业务ID数组(即先锁定该批次要处理交易),然后第二个转换根据事先锁定的交易ID数组提取出日期时间数组,用户ID数组,地区数组等。第三个转换再使用前面两步转换里提取的变量查询数据进行迁移 在迁移i数据时,数据流分成了新数据流(针对业务表)和旧数据流(针对事实/维度表),新数据流通过排序、分组、字段选择和连接数据集join起来,然后通过合并记录组件计算出每行记录的flagfield(new/changed/deleted/identical的评判结论),然后通过Switch/Case或过滤记录分别针对每种情况进行处理(调用表输出/更新/删除) 如果转换时涉及多个类别的数据要迁移到一张事实/维度表,不要拆成两组job,可以在一个job里依次调用一组转换,执行完一组再执行下一组,千万不要并行,因为设置的全局变量名字都一样,会出现冲突问题 变量的的使用 ${Internal.Entry.Current.Directory}/test.ktr可以表示当前目录下的test.ktr,同时适配repository模式和local文件模式 关于变量的使和编程语言中的变量不太一样,无法使用在同一个转换中定义和获取当前转换内修改过的变量,变通方法是拆成两个转换来使用,这问题卡了好几天才找到原因。 在job/转换通过-param:varname=value的方式传参时,如果发现变量无法解析,那么一定是job和转换的命名参数里没有配置(双击空白处,有个命名参数页签....) 在job/转换开始执行的时候通过日志输出一下用到的变量是个很好的习惯 作业和转换都要有命名参数startrow,pagesize,startdate,enddate几个,这样可以在调用的时候灵活控制分页以及起止时间,灵活实现全量和增量迁移 对变量冲突的问题要小心,特别是同一个job并行处理多个转换时更是如此,因此在job里并行执行转换时要格外小心。 写变量时有对变量作用域的设置,推荐设置成Valid in the root job,不推荐Valid in the Java Virtual Matchine。 表输入的处理 表输入有个功能,可以每行都执行一次查询,这个功能不要用,太慢对内存占用很高。 推荐使用记录集连接的方法,比如A,B,C三个表要通过外键拼接在一起插入到D表中,那么可以A,B,C三个表分别通过表输入查询出来,然后通过连接记录集拼接到一起做为新数据(排序、字段对齐、类型要一致),然后查询出D表做为老数据(排序、字段对齐、类型要一致),然后通过合并记录的方式对比新老数据,并根据flagfield的四个状态值(new/update/delete/identical)来通过Switch/Case组件分别处理插入/更新/删除和无变化四种情况。处理完成后,记得startrow要加一,这样做会显著提升迁移性能。 表输入最好选中忽略插入错误选项并且设置自动产生的关键字字段名称,并且在下一步骤用Switch/Case判断下这个自动产生的关键字字段的内容是否是null,不这样做,当插入出错时(不会在表输出步骤报错),错误会在表输出的下一步骤报错。 全量和增量迁移 全量迁移和增量迁移做到一起可以通过合并记录+Switch/Case来判断flagfied的值分别实现对应的插入/更新/删除/无变化四种类型的数据处理。千万不要将全量迁移和增量迁移分开,维护工作量太大了 映射功能 映射功能可以提升整个模型的复用度,映射中的输入就是外部查询的业务数据(不同的业务数据sql不同,但对于初始化的维度数据必须一致),这样可以实现业务转换和通用转换的分离,极大的降低整个模型的复杂度和维护难度。 每个维度表要使用一个独立的转换(内部实现新增/修改/删除等功能),在事实表中调用维度表转换(每个维度字段都要对应一个转换)在业务模型查询出本页里面需要处理的维度数据集,然后传入映射(子转换)并交由子转换(输入规范组件)做处理,每个子转换处理一个维度表,处理完的结果在子转换中通过映射输出规范组件输出到父模型里,然后父模型可以继续往下处理。 映射调试:首先输入数据用文本输出组件输出成A.txt,然后在映射中同时添加映射输入规范和文件输入(使用A.txt)通过点击连接禁用和启用输入规范和文件输入实现调试映射和在父转换中调试映射。 映射可以提升模型的复用度,比如类似日期处理,地区处理,用户处理这些一般都要抽取成可复用的模型,通过映射嵌入到别的模型里去,这样模型的层次比较清晰和简洁,而且不显得那么乱 映射时的变量我推荐勾选默认的“从父转换集成所有变量”,而不要每个转换里都定义,当子转换和父转换中的变量同名时很容易出现稀奇古怪的问题 映射偶尔会出现不返回数据的情况(重复执行可能又正常了,估计是kettle的bug),经过测试,在传参的上一步加一个文件输出会有改善(连接使用复制就可以) 模型调试 完整模型是由一个job,多个转换组成(转换也分成了业务转换和共用转换),执行迁移的时候通过job来执行(不要直接执行转换),从逻辑上只要关注全局变量的内容和转换的结果就可以了。这样对于调试来说效率较高。 整个完整的转换中,全局变量是统一的,主要包含startdate,enddate,pagesize,所有转换和job都使用这三个命名参数,在通过kitchen.sh执行时要通过-param传入这三个变量 某个共用转换需要另一个转换中的数据的时候,可以使用文件保存输出数据,然后在共用转换中用文件输入替代映射输入规范的输入参数 合并记录时的几个注意事项。 貌似kettle是用数据字段匹配的,关键字段必须可以唯一确定一条数据(类似联合唯一索引的作用,但不要选事实表主键),如果关键字段是空,那么合并的结果可能多条会合并成一条。数据字段是标识新旧数据需要比对哪些字段(也就是通过哪些字段来的到new/update/delete/identical的评判结论)。 合并记录时数据字段的多少并不影响合并后的结果。 合并记录最大的作用是对比两个数据流的数据变化,自动识别出需要插入/更新/删除和无变化的数据行,再配合Switch/Case组件分别实现insert、update和delete。 注意在合并记录中不能有更新时间,否则会出现很奇怪的结果 合并记录时需要注意一个是新旧数据源的排序必须相同,第二就是关键字和数据字段的选择,这两点做到了结果就是对的。 合并记录后某些记录的flagfield总是不正确(已经存在的数据flagfield是new,造成插入时唯一索引冲突),这说明前面步骤的排序方式不对 合并记录如果出现相同的两条数据flagfield一个是new另一个是deleted,那说明关键字定义的几个字段有差异 合并记录后处理更新和删除时条件部分选择合并记录的关键字保持一致 表输出的处理 表输出有个[返回一个自动产生的关键字]在insert后,可以将主键值自动获取到并填入到一个新字段,在后续的步骤可以通过给字段赋值来回写到主键字段,再通过字段选择移除这个临时生成的新字段,可以减少一次查询表的过程。 表输出时有个选项是忽略插入错误,这个一定要打开,但要有区分,一般唯一索引异常是要忽略掉的,但其余不能忽略,这个问题可以通过添加自定义错误来解决。 合并之前一定要用选择字段对新旧数据流里面的字段做一致化处理(元数据名字,类型,长度,精度,Binary to Normal)甚至字段的数量和顺序都要严格匹配 合并之前字段一定要排序,并且排序规则完全一致 合并记录后,flagfield=identical的记录主键会是0,这时候需要把老数据重新连接到合并之后的数据流就可以了(注意排序和字段名字) 异常处理 表输出异常,表输出是支持异常的,组件上右键菜单里选“定义错误处理”,可以设置错误列名,字段名,描述等信息,在后续步骤中可以使用过滤记录来做甄别,比如主键冲突错误要Contains Duplicate entry就忽略掉异常,其余的错误就停止,这样可以提高容错性。 排序 很多组件都要实现对数据排序,比如分组、合并记录、连接数据集等,如果不排序会出现一些稀奇古怪的问题 有条件一定用sql排序,只有中间步骤没法使用sql排序的情况下才使用kettle自带的排序。 异常和报错 you're mixing rows with different storage types. Field [VISIT_NO String(13)<binary-string>] does not have the same storage type as field [VISIT_NO String(13)] 有两种办法,一种是两处数据流在查询的时候,字段类型不一致,可以在sql里做下cast转换解决。 另外一种是通过字段选择,在元数据页添加一致的类型(长度,格式,最重要的是Binary to Normal改成true) java.lang.NullPointerException: 这种一般是有合并记录步骤,需要两个输入步骤,但其中有的输入步骤不存在,就会报这个错 字段选择提示字段不存在,但字段明明存在: 因为在选择和修改页把字段修改了名字,在元数据页填修改后的新名字就不报错了 优化前后效果对比 优化前 里面有大量的每行查询一次的功能,一次迁移最多2000条,多了就内存溢出 全量迁移一次要2天 全量和增量迁移是分开的,修改起来很罗嗦 没有使用变量,limit限制条件都是写死的,每次执行都要先调整模型的limit参数 没有使用子转换,模型间没有复用,模型都是复制来复制去,很容易出错 缺少异常处理 优化后 增加命名参数,迁移的时候非常灵活 改用分页机制,每页数据量可以通过参数传递 将全量模型和增量模型整合在一起,通过时间参数来控制 将用户,时间,地区等复用度高的模型写成了子转换,通过映射的方式提高模型复用度,极大的简化了模型。 有异常处理,同时对插入数据做了容错(索引冲突不报错,认为是成功) 增加了完善的数据调试机制 优化后每次迁移可以5000~10000条(通过参数设置,如果中间出错还可以从上次断开的地方继续迁移),自动全量迁移,相同的数据量迁移一次只要1小时就搞定。