在机器学习的特征处理环节,免不了需要用到类别型特征,这类特征进入模型的方式与一般数值型变量有所不同。
通常根据模型的需要,类别型特征需要进行哑变量处理,即按照特征类别进行编码,一般一个类别为k的特征需要编码为一组k-1【避免引起多重共线性】个衍生哑变量,这样就可以表示特征内部所有的类别(将其中基准比较类设为0,当k-1个哑变量都为0时,即为基准类)。
这种哑变量的编码过程在R和Python中的有成熟的方案,而无需我们手动进行编码,使用成熟的编码方案可以提升特征处理的过程。
R语言哑变量处理:
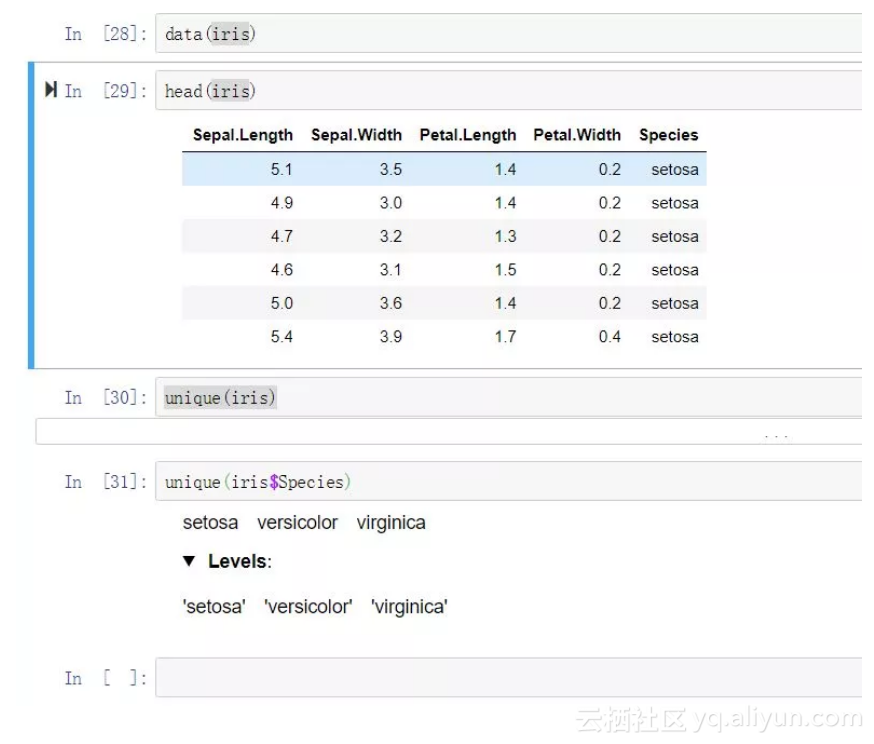
data(iris)
![d14fe6036cb46cea5905f4220cfcdec3a603e27e]()
这里仍以iris数据集为例,假设这里的Species变量是要进入模型的其中一个自变量,在建模前需要对齐进行哑变量处理。
方法一——dummy包:
library("dummy")
dumy <- dummy(x=iris)
dummy函数会自动检查你输入数据集对象中的字符型/因子型变量,并全量输出字符型/因子型变量的哑变量编码结果。注意这里编码结果是全量输出,即类别型特征的每一个类别都有一个编码后的特征。为了编码引起多重共线性,我们需要舍弃一个(代表比较基准类的特征),这里Species类别变量一共有三个类别:setosa、versicolor 、virginica,各自都有一个对应编码变量,当原始类别变量取对应类别时,则对应类别哑变量位置取值为1,否则为0.
假设这里我们想要对比的基准类是setosa,只需要保留versicolor、virginica对应的编码后变量。那么当versicolor、virginica都取值为0时,则代表取值为setosa。
最终我们要将保留的哑变量与原始数据集合并,以备之后其他特征处理环节需要。
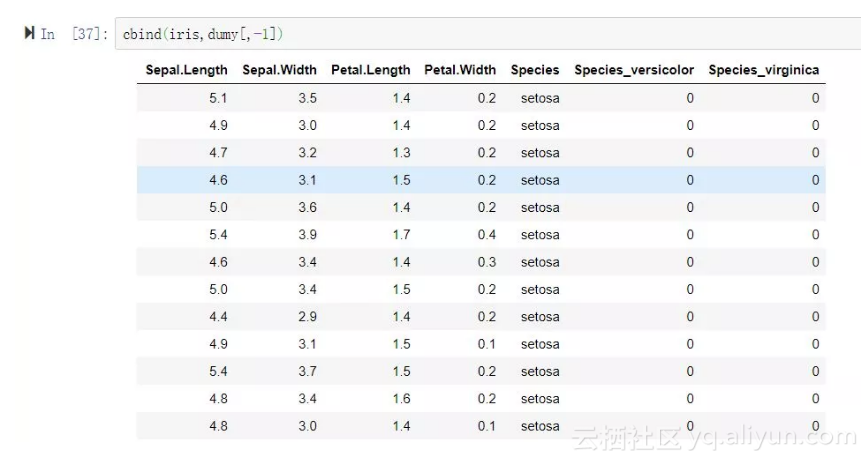
iris_data <- cbind(iris,dumy[,-1])
此时就可以完美的用Species_versicolor、Species_virginica这两个新生成的哑变量来代表原始分类变量Species了。
方法二——model.matrix函数:
R语言内置包stat中有一个model.matrix函数(无需单独加载既可用),它可以处理分类变量的哑变量处理过程,语法非常简单。
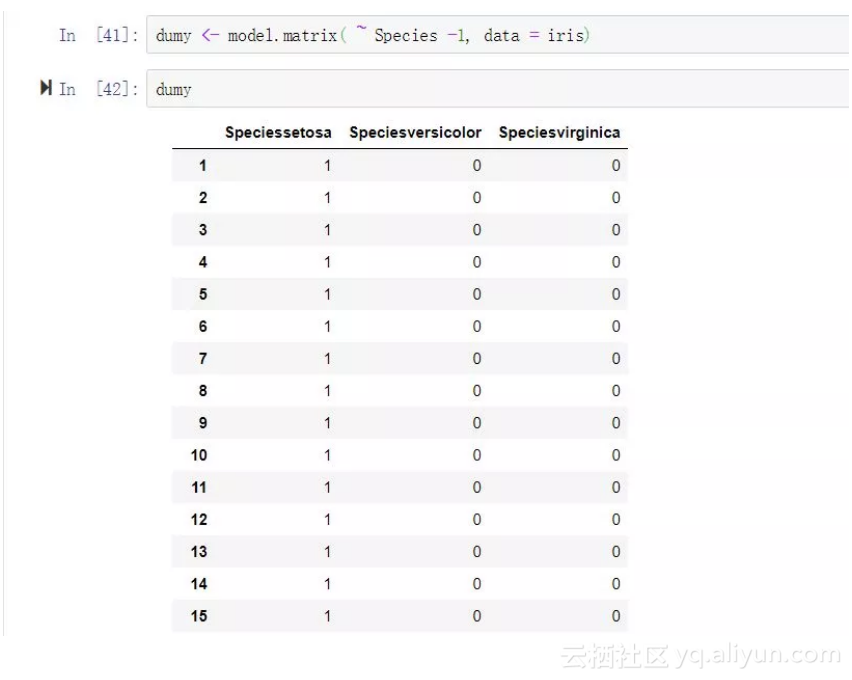
dumy <- model.matrix( ~ Species -1, data = iris)
iris_data <- cbind(iris,dumy[,-1])
这里需要在表达式中设定消除截距【公式中减一,否则输出的哑变量带有截距项】,选择的时候同上,只取比较基准类之外的所有哑变量。
方法三——caret包中的dummyVars函数:
library("caret")
dumy <- dummyVars(~gender,data=customers)
trfs <- predict(dumy,newdata=customers)
iris_data <- iris %>% dummyVars(~Species,.) %>% predict(iris) %>% .[,-1] %>% cbind(iris,.)
选择规则同上。
Python中的哑变量处理工具:
from sklearn.preprocessing import Imputer,LabelEncoder,OneHotEncoder
from sklearn import preprocessing
from sklearn.model_selection import train_test_split
from sklearn.datasets import load_iris
import pandas as pd
import numpy as np
方案一——:sk-learn中的OneHotEncoder方法:
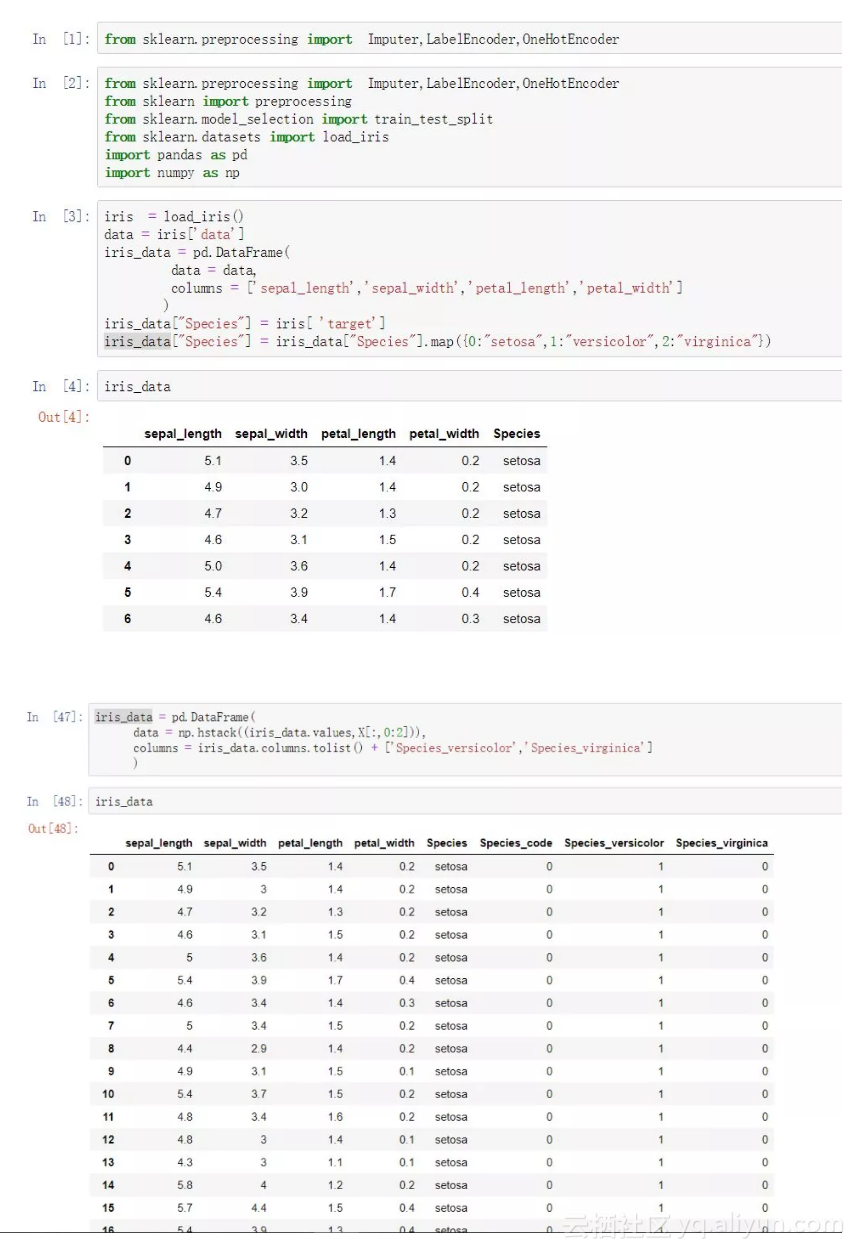
iris = load_iris()
data = iris['data']
iris_data = pd.DataFrame(
data = data,
columns = ['sepal_length','sepal_width','petal_length','petal_width']
)
iris_data["Species"] = iris[ 'target']
iris_data["Species"] = iris_data["Species"].map({0:"setosa",1:"versicolor",2:"virginica"})
labelencoder_X = LabelEncoder()
iris_data["Species_code"] = labelencoder_X.fit_transform(iris_data.iloc[:,4])
onehotencoder = OneHotEncoder(categorical_features = [0])
X = onehotencoder.fit_transform(iris_data[["Species_code"]]).toarray()
iris_data = pd.DataFrame(
data = np.hstack((iris_data.values,X[:,0:2])),
columns = iris_data.columns.tolist() + ['Species_versicolor','Species_virginica']
)
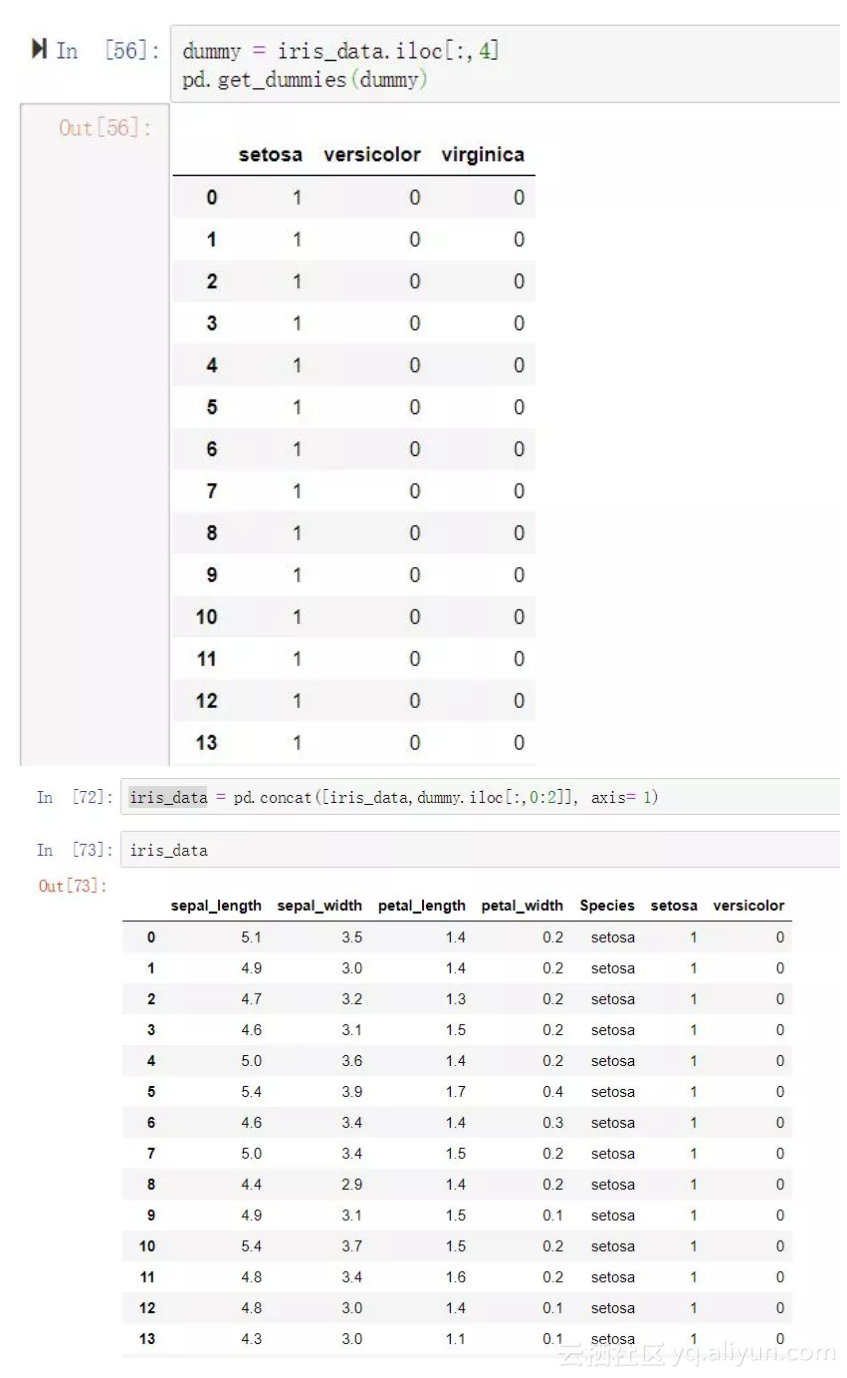
方案二——pandas中的get_dummies方法:
可以看到sk-learn中的OneHotEncoder方法必须保证处理的输入值是array,而且只能处理数值型(也就是数字编码之后的类别变量),无法直接处理仔字符型变量。
其实如果能够直接在数据框中处理完这一切就方便很多。
dummy = pd.get_dummies(iris_data.iloc[:,4],prefix = "Species")
iris_data = pd.concat([iris_data,dummy.iloc[:,0:2]], axis= 1)
pandas中的get_dummies方法提供了非常简单高效的哑变量处理方案,只有短短的一句代码即可。
回顾一下今天分享的哑变量处理知识点:
R语言:
● 方案一——:dummy包的dummy函数
● 方法二——:model.matrix函数
● 方法三——:caret包中的dummyVars函数
Python:
● 方法一——:caret包中的dummyVars函数
● 方案二——:pandas中的get_dummies方法
原文发布时间为:2018-10-1
本文作者:杜雨