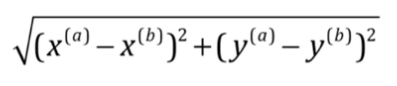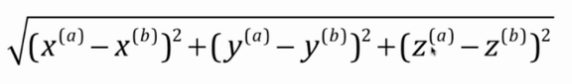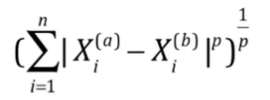这段时间用opencv中的机器学习算法做了一下目标检测,效果还是不错的。但都是按照命令和库进行调用,基本对我来说是个黑盒子。固然工程师要会用工具,但如果不深入理解内部实现,是很难进步的。所以我打算花上一些时间(可能两个月以上)来学习一下机器学习的基本概念,并且用python语言去实现一些经典的算法,希望自己能坚持下去吧~
1.简介
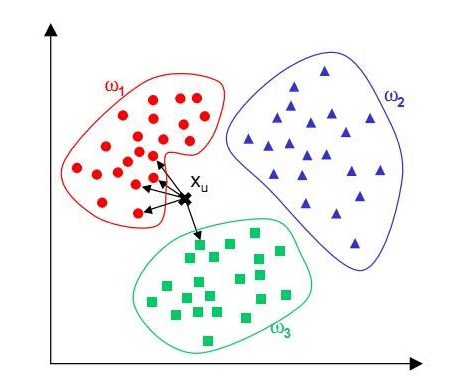
kNN算法可以说是机器学习中最简单的一种算法了。它思想极其简单,应用数学知识很少,并且效果相对于它的复杂程度来说极其地好,许多问题都可以用它来解决。它的思想用上面的一张图就可以解释清楚。它的本质是让输入与给定的数据集进行距离的计算。如果最近的点大部分为某一类(比如说是A),则判定为A类。kNN中的k,就是跟输入比较的点的数量。这个是作为算法的一个参数。当然距离的计算方法有很多种,比如说欧拉距离
多维的情况可以如下进行推导
也可以使用明科夫斯基距离,其中p成为了算法的一个参数
2.算法实现
算法大概可以用python进行封装成这个样子
"""
Created by 杨帮杰 on 9/25/18
Right to use this code in any way you want without warranty,
support or any guarantee of it working
E-mail: yangbangjie1998@qq.com
Assication: SCAU 华南农业大学
"""
import numpy as np
from math import sqrt
from collections import Counter
class KNNClassifier:
def __init__(self,k):
assert k>=1,"k must be valid"
self.k = k
self._X_train = None
self._y_train = None
def fit(self, X_train, y_train):
"""根据训练数据集X_train和y_train训练kNN分类器"""
assert X_train.shape[0] == y_train.shape[0], \
"the size of X_train must be equal to the size of y_train"
assert self.k <= X_train.shape[0], \
"the size of X_train must be at least k"
self._X_train = X_train
self._y_train = y_train
return self
def predict(self, X_predict):
"""给定待预测数据集X_predict, 返回表示X_predict的结果向量"""
assert self._X_train is not None and self._y_train is not None, \
"must fit before predict!"
assert X_predict.shape[1] == self._X_train.shape[1], \
"the feature number of X_predict must be equal to X_train"
y_predict = [self._predict(x) for x in X_predict]
return np.array(y_predict)
def _predict(self, x):
"""给定单个待预测数据x,返回x的预测结果值"""
assert x.shape[0] == self._X_train.shape[1], \
"the feature number of x must be equal to X_train"
distances = [sqrt(np.sum((x_train - x) ** 2))
for x_train in self._X_train]
nearest = np.argsort(distances)
topK_y = [self._y_train[i] for i in nearest[:self.k]]
votes = Counter(topK_y)
return votes.most_common(1)[0][0]
def __repr__(self):
return "KNN(k=%d)" % self.k
可以看到,类中的fit方法也就是算法的训练过程什么都没干,就是把成员赋值。所以说,kNN是一个不需要训练模型的算法,或者说训练集本身就是模型。
在python的机器学习库sciki-learn中,可以进行以下的方法进行调用
"""
Created by 杨帮杰 on 9/25/18
Right to use this code in any way you want without warranty,
support or any guarantee of it working
E-mail: yangbangjie1998@qq.com
Assication: SCAU 华南农业大学
"""
from sklearn import datasets
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.neighbors import KNeighborsClassifier
# 获得鸢尾花的数据集
iris = datasets.load_iris()
x = iris.data
y = iris.target
# 测试集与训练集分离,测试集为20%的总数据
X_train, X_test, y_train, y_test = \
train_test_split(iris.data, iris.target, test_size=0.2)
# 对数据进行归一化处理
standarScaler = StandardScaler()
standarScaler.fit(X_train)
X_train_std = standarScaler.transform(X_train)
X_test_std = standarScaler.transform(X_test)
# 模型训练和测试
knn_clf = KNeighborsClassifier(n_neighbors=4)
knn_clf.fit(X_train_std,y_train)
score = knn_clf.score(X_test_std, y_test)
print(score)
结果如下。可以看到对于简单的多分类问题kNN算法有着很好的效果。
3.需要注意的细节
为了验证模型训练的结果,往往需要将数据分为训练集和测试集。模型训练之后将模型运用到测试集中,如果效果不好则说明参数和算法本身需要调整。
机器学习中参数分为超参数和模型参数。超参数是算法在实际运用中的参数,模型参数是算法在训练模型时需要的参数。kNN没有模型参数,而k值是典型的超参数。
参数的度量单位不同,会对结果产生极大的影响。所以我们需要对数据映射到统一尺度,即归一化。其中归一化分为最值归一化和方差归一化。一般使用方差归一化
4.算法优缺点
优点:思想简单,实现起来比较容易,在多分类问题上效果很好
缺点:效率低下。如果有m个样本和n个特征,则算法复杂度为O(m*n)。当训练数据比较多的时候,可以想象速度有多感人。而且结果不具有可解释性。
References:
Python3 入门机器学习 经典算法与应用 —— liuyubobobo
机器学习实战 —— Peter Harrington