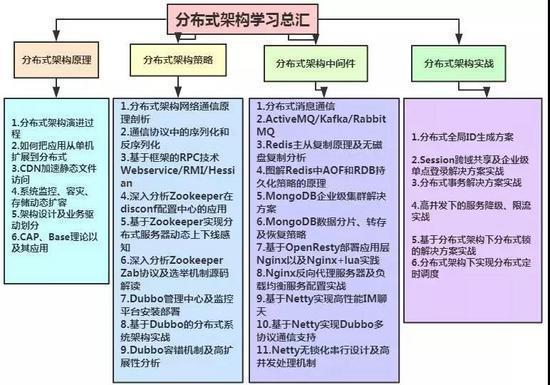
Python | Python学习之深浅拷贝
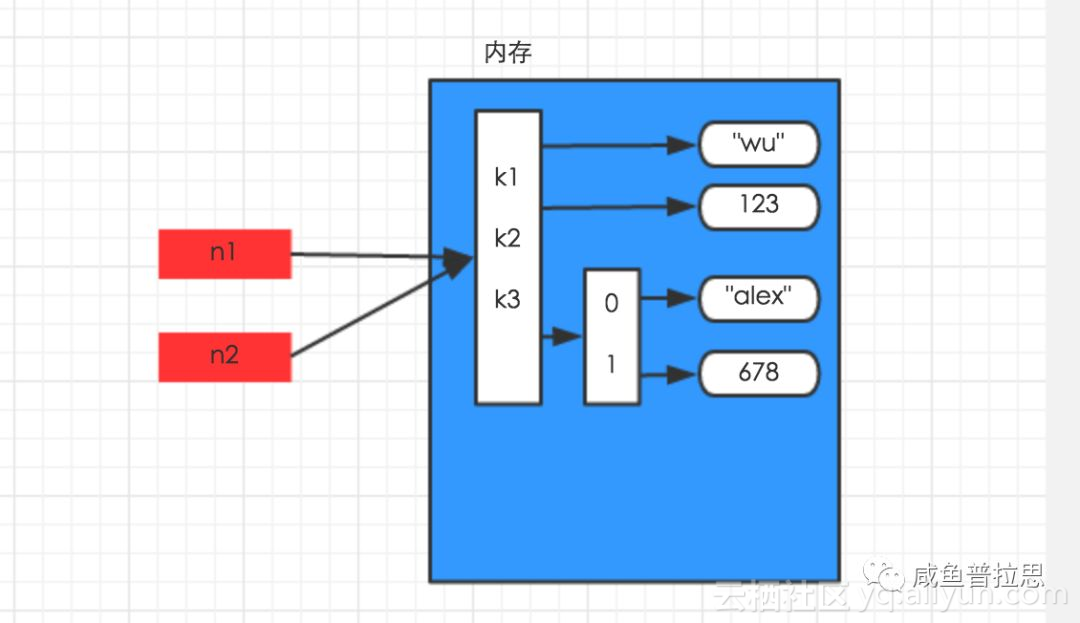
直接步入正题,聊一聊 Python 中的深浅拷贝 关于 is 和 == == 是 python 标准操作符中的比较操作符,用来比较判断两个对象的 value(值) 是否相等 。 # 例1.1 a = '2332424' b = '2332424' print(a == b) 输出: True [Finished in 0.1s] is 也被叫做同一性运算符,这个运算符比较判断的是对象间的唯一身份标识,也就是id是否相同。 # 例1.2 a = b = ['2343456'] c = ['2343456'] print(a == b, id(a), id(b)) print(a == c, id(a), id(c)) print(a is b, id(a), id(b)) print(a is c, id(a), id(c)) 输出: True 10715336 10715336 True 10715336 10717064 True 10715336 10715336 False 10715336 10717064 [Finished in 0.1s] 不同类型下, == 的结果都为True,但是 is 的结果则不一定 # 例1.3 # a 和 b 都为数值时 a = 1 b = 1 print(id(a)) print(id(b)) print(a == b) print(a is b) 1715077616 1715077616 True True [Finished in 0.1s] # a 和 b 都为字符串时 a = 'abcdefg' b = 'abcdefg' print(id(a)) print(id(b)) print(a == b) print(a is b) 11847696 11847696 True True [Finished in 0.1s] # a 和 b 都为列表时 a = ['12345678'] b = ['12345678'] print(id(a)) print(id(b)) print(a == b) print(a is b) 16941256 16942984 True False [Finished in 0.1s] # a 和 b 都是字典时 a = {'a':1,'b':2} b = {'a':1,'b':2} print(id(a)) print(id(b)) print(a == b) print(a is b) 10421192 10421256 True False [Finished in 0.1s] # a 和 b 都是元组时 a = (1,2,3) b = (1,2,3) print(id(a)) print(id(b)) print(a == b) print(a is b) 11960608 11960680 True False [Finished in 0.1s] # a 和 b 都为集合时 a = set([1,2,3]) b = set([1,2,3]) print(id(a)) print(id(b)) print(a == b) print(a is b) 16850504 16919464 True False [Finished in 0.1s] 只有数值型和字符串型的情况下,a is b才为True,当a和b是tuple,list,dict或set型时,a is b为False。 关于深浅拷贝 首先我们来看几个栗子: # 例2.1:赋值 a = [1,2,3] b = a a.append([4,5,6]) print(a) print(b) print(a is b) print(a == b) 输出: [1, 2, 3, [4, 5, 6]] [1, 2, 3, [4, 5, 6]] [Finished in 0.1s] True True 在例2.1中a的末尾新增了[4,5,6]之后,b的值也发生了变化,这是因为a把值赋值给b只是将创建的b对象指向了a对象指向的内存,这时的a和b指向的都是同一块内存空间(id),所以修改a后b的值也一起改变。 # 例2.2:赋值 a = [1,2,3] b = a a = [4,5,6] print(a) print(b) print(id(a)) print(id(b)) 输出: [4, 5, 6] [1, 2, 3] 10848136 10846408 [Finished in 0.1s] 在例2.2中先将a赋值给b,又将[4,5,6]赋值给a,这时已经给a创建了新的内存空间,所以打印a,b时a和b的值并不相同。 下面来看下深浅拷贝的不同之处: 首先字符串 、元组以及数值的深浅拷贝是没有差别的,如下例子所示: # 例3.1 # 字符串 import copy a = '1345' b = copy.copy(a) c = copy.deepcopy(a) print(id(a), id(b), id(c)) 输出: 17025040 17025040 17025040 [Finished in 0.1s] # 数值 import copy a = 1345 b = copy.copy(a) c = copy.deepcopy(a) print(id(a), id(b), id(c)) 输出: 9326480 9326480 9326480 [Finished in 0.1s] # 元组 import copy a = (1,2,3) b = copy.copy(a) c = copy.deepcopy(a) print(id(a), id(b), id(c)) 输出: 10715424 10715424 10715424 [Finished in 0.2s] 而对于字典、列表 进行浅拷贝和深拷贝时,其id是有变化的 # 列表 import copy a = [1,2,3] b = copy.copy(a) c = copy.deepcopy(a) print(id(a), id(b), id(c)) 输出: 17540104 17040264 17419656 [Finished in 0.1s] #字典 import copy a = {"a": "1", "b": 2, "c": ["c", 3]} b = copy.copy(a) c = copy.deepcopy(a) print(a, b, c) print(id(a), id(b), id(c)) a['c'] = '666' print(a, b, c) print(id(a), id(b), id(c)) 输出: {'b': 2, 'a': '1', 'c': ['c', 3]} {'b': 2, 'a': '1', 'c': ['c', 3]} {'b': 2, 'a': '1', 'c': ['c', 3]} 6882248 17105992 16886792 {'b': 2, 'a': '1', 'c': '666'} {'b': 2, 'a': '1', 'c': ['c', 3]} {'b': 2, 'a': '1', 'c': ['c', 3]} 6882248 17105992 16886792 [Finished in 0.1s] 浅拷贝 :不管多么复杂的数据结构,浅拷贝都只会copy一层,且当copy指向不可变类型时,copy不会执行copy操作。当copy指向可变类型时,copy会执行第一层拷贝,即拷贝浅层的指向。 深拷贝 :其实深拷贝就是在内存中重新开辟一块空间,不管数据结构多么复杂,只要遇到可能发生改变的数据类型,就重新开辟一块内存空间把内容复制下来,直到最后一层,不再有复杂的数据类型,就保持其原引用。这样,不管数据结构多么的复杂,数据之间的修改都不会相互影响,这就是深拷贝,也同样可以将深拷贝理解为真正意义上的复制,是两个操作独立的个体。 有关深浅拷贝相关的图片说明可以参照下面几个链接的内容,以加深理解: http://www.cnblogs.com/wupeiqi/articles/5453708.htmlhttp://www.runoob.com/w3cnote/python-understanding-dict-copy-shallow-or-deep.html也可参照下面的几张图片: 原文发布时间为:2018-07-10本文来自云栖社区合作伙伴“小詹学Python”,了解相关信息可以关注“小詹学Python”。