Elastic Stack学习--logstash入门
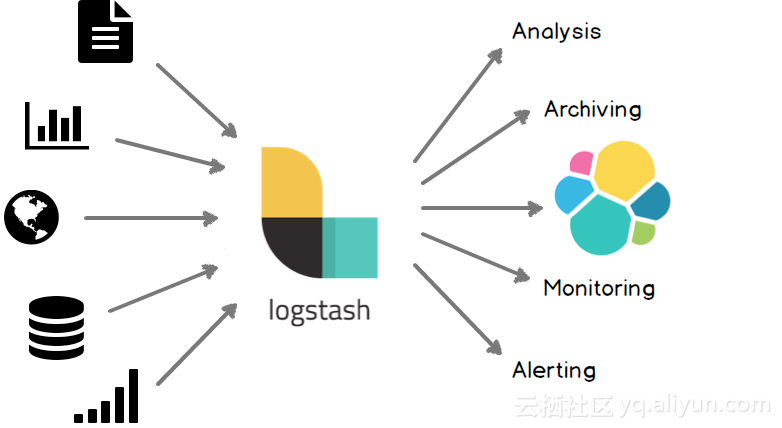
logstash是基于实时管道的数据收集引擎。它像一根处理数据的管道,收集分散的数据,进行汇总处理后输出给下游进行数据分析和展现。 logstash可以配合Beats组件或者其它第三方组件进行数据收集,数据经过处理后存放到elasticsearch中进行检索和分析。 除了对接beats以外,logstash有着丰富的组件,能够支持各种数据源接入。包括jdbc、kafka、http等。 logstash是基于pipeline方式进行数据处理的,pipeline可以理解为数据处理流程的抽象。在一条pipeline数据经过上游数据源汇总到消息队列中,然后由多个工作线程进行数据的转换处理,最后输出到下游组件。一个logstash中可以包含多个pipeline。 基本概念 pipeline:一条数据处理流程的逻辑抽象,类似于一条管道,数据从一端流入,经过处理后,从另一端流出;一个pipeline包括输入、过滤、输出3个部分,其中输入和输出部分是必选组件,过滤是可选组件; instance:一个logstash实例,可以包含多条数据处理流程,即多个pipeline; inputs:数据输入组件,用于对接各种数据源,接入数据,支持解码器,允许对数据进行编码解码操作;必选组件; filters:数据过滤组件,负责对输入数据进行加工处理;可选组件; outputs:数据输出组件,用于对接下游组件,发送处理后的数据,支持解码器,允许对数据进行编码解码操作;必选组件; event:pipeline中的数据都是基于事件的,一个event可以看作是数据流中的一条数据或者一条消息; 安装logstash 1)依赖java8,且不支持java9:检查java版本并配置JAVA_HOME环境变量。logstash基于jruby开发,logstash 6.x版本要求运行在java8环境,且目前不支持java9;2)下载并解压:下载logstash,解压文件;注意logstash所在路径中不可以包含冒号; tar -zxvf logstash-6.2.2.tar.gz cd logstash-6.2.2 3)启动logstash,发布第一个事件:通过-e指定一个pipeline的处理流程,指定从stdin中读取event,然后在stdout输出; bin/logstash -e 'input { stdin { } } output { stdout {} }' 可以看到类似如下日志: Sending Logstash's logs to /home/work/zion_package/elastic/logstash/logstash-6.2.2/logs which is now configured via log4j2.properties h[2018-03-14T14:48:00,053][INFO ][logstash.modules.scaffold] Initializing module {:module_name=>"fb_apache", :directory=>"/home/work/zion_package/elastic/logstash/logstash-6.2.2/modules/fb_apache/configuration"} [2018-03-14T14:48:00,074][INFO ][logstash.modules.scaffold] Initializing module {:module_name=>"netflow", :directory=>"/home/work/zion_package/elastic/logstash/logstash-6.2.2/modules/netflow/configuration"} [2018-03-14T14:48:00,172][INFO ][logstash.setting.writabledirectory] Creating directory {:setting=>"path.queue", :path=>"/home/work/zion_package/elastic/logstash/logstash-6.2.2/data/queue"} [2018-03-14T14:48:00,178][INFO ][logstash.setting.writabledirectory] Creating directory {:setting=>"path.dead_letter_queue", :path=>"/home/work/zion_package/elastic/logstash/logstash-6.2.2/data/dead_letter_queue"} [2018-03-14T14:48:00,631][WARN ][logstash.config.source.multilocal] Ignoring the 'pipelines.yml' file because modules or command line options are specified [2018-03-14T14:48:00,672][INFO ][logstash.agent ] No persistent UUID file found. Generating new UUID {:uuid=>"5901ab9f-fdc9-43dc-a88d-c5c636cf8224", :path=>"/home/work/zion_package/elastic/logstash/logstash-6.2.2/data/uuid"} [2018-03-14T14:48:01,337][INFO ][logstash.runner ] Starting Logstash {"logstash.version"=>"6.2.2"} [2018-03-14T14:48:01,733][INFO ][logstash.agent ] Successfully started Logstash API endpoint {:port=>9600} [2018-03-14T14:48:03,264][INFO ][logstash.pipeline ] Starting pipeline {:pipeline_id=>"main", "pipeline.workers"=>12, "pipeline.batch.size"=>125, "pipeline.batch.delay"=>50} [2018-03-14T14:48:03,453][INFO ][logstash.pipeline ] Pipeline started succesfully {:pipeline_id=>"main", :thread=>"#<Thread:0x128244e5 run>"} The stdin plugin is now waiting for input: [2018-03-14T14:48:03,546][INFO ][logstash.agent ] Pipelines running {:count=>1, :pipelines=>["main"]} 在控制台随便输入字符串按回车后,发现消息会立刻在控制台输出,此时pipeline的处理过程是从stdin接收我们的输入,然后再在stdout输出: Hello, this is my first event to logstash ! 2018-03-14T06:50:26.261Z yf-beidou-dmp00.yf01.baidu.com Hello, this is my first event to logstash ! logstash会给消息添加ip和时间戳,要退出logstash,输入ctrl+d; 通过Filebeat发送日志到logstash 配置Filebeat Filebeat用于追踪服务器上的文件数据,它的设计以可靠和低资源占用为初衷,和业务系统部署在一起时,能够避免因为资源消耗影响到业务系统的正常运行。logstash安装后默认包含Beats input组件,用于接收各种beat组件上报事件。Filebeat也可以直接上报事件给elasticsearch,而不用经过logstash。 1)下载文件样例logstash-tutorial.log.gz,上传至Filebeat将要部署的服务器并解压;该样例为官方文档提供的apache的web日志样例。2)下载Filebeat,上传服务器并解压;此处下载LINUX 64-BIT的安装包; tar -zxvf filebeat-6.2.2-linux-x86_64.tar.gz cd filebeat-6.2.2-linux-x86_64 3)配置Filebeat,修改filebeat.yml,设置监控日志文件路径和上报logstash地址; filebeat.prospectors: - type: log # 监控日志文件路径 paths: - /path/to/file/logstash-tutorial.log output.logstash: # 上报logstash地址 hosts: ["localhost:5044"] 注:设置监控日志文件的路径一定是绝对路径,支持通配符; 4)启动Filebeat;其中-e参数指定输出日志到stderr,而非输出到日志文件;-c参数指定配置文件路径;-d参数debug选择器; ./filebeat -e -c filebeat.yml -d "publish" 配置logstash 1)创建pipeline配置文件;pipeline配置格式如下: # The # character at the beginning of a line indicates a comment. Use # comments to describe your configuration. input { } # The filter part of this file is commented out to indicate that it is # optional. # filter { # # } output { } 创建一个名为first-pipeline.conf的文件,配置如下: input { beats { # 设置beats上报端口 port => "5044" } } # The filter part of this file is commented out to indicate that it is # optional. # filter { # # } output { # 输出到stdout,同时指定日志解码器为rubydebug stdout { codec => rubydebug } } 2)校验配置是否正确,命令如下。--config.test_and_exit选项会校验配置文件,并输出错误; bin/logstash -f first-pipeline.conf --config.test_and_exit 输出类似如下日志,说明配置文件格式校验通过: Configuration OK [2018-03-14T16:23:08,919][INFO ][logstash.runner ] Using config.test_and_exit mode. Config Validation Result: OK. Exiting Logstash 3)启动logstash,命令如下。--config.reload.automatic选项能够使得配置文件修改后被自动加载,从而避免重新启动logstash; bin/logstash -f first-pipeline.conf --config.reload.automatic 如果配置正确,可以看到logstash命令行有类似如下输出: { "host" => "yf-beidou-dmp00.yf01.baidu.com", "offset" => 22310, "tags" => [ [0] "beats_input_codec_plain_applied" ], "message" => "218.30.103.62 - - [04/Jan/2015:05:28:43 +0000] \"GET /blog/geekery/xvfb-firefox.html HTTP/1.1\" 200 10975 \"-\" \"Sogou web spider/4.0(+http://www.sogou.com/docs/help/webmasters.htm#07)\"", "prospector" => { "type" => "log" }, "beat" => { "name" => "yf-beidou-dmp00.yf01.baidu.com", "version" => "6.2.2", "hostname" => "yf-beidou-dmp00.yf01.baidu.com" }, "@timestamp" => 2018-03-14T08:43:52.564Z, "source" => "/home/work/zion_package/elastic/filebeat/logstash-tutorial.log", "@version" => "1" } 通过Grok过滤组件解析日志 通过上面的例子,我们可以将filebeat上报的日志经由logstash输出,接下来将添加filter组件,对日志进行处理。grok组件是logstash的filter组件之一,它可以将非结构化的数据按照一定规则整理成结构化数据,从而便于检索。这些规则需要根据日志格式事先设定好,因此需要了解采集日志的格式。因为我们的样例日志是apache的web日志,因而可以直接使用grok提供的%{COMBINEDAPACHELOG}格式进行日志的过滤,过滤后的日志格式如下: 修改first-pipeline.conf文件,增加filter,如下: input { beats { port => "5044" } } filter { grok { match => { "message" => "%{COMBINEDAPACHELOG}"} } } output { stdout { codec => rubydebug } } 因为启动logstash时添加了--config.reload.automatic选项,logstash能够自动加载修改后的配置文件,因而不需要重启;修改保存后可以看到重新加载配置,重启pipeline的日志: [2018-03-14T17:04:57,325][INFO ][logstash.pipelineaction.reload] Reloading pipeline {"pipeline.id"=>:main} [2018-03-14T17:05:01,758][INFO ][logstash.pipeline ] Pipeline has terminated {:pipeline_id=>"main", :thread=>"#<Thread:0x58f295b9 run>"} [2018-03-14T17:05:02,048][INFO ][logstash.pipeline ] Starting pipeline {:pipeline_id=>"main", "pipeline.workers"=>12, "pipeline.batch.size"=>125, "pipeline.batch.delay"=>50} [2018-03-14T17:05:02,362][INFO ][logstash.inputs.beats ] Beats inputs: Starting input listener {:address=>"0.0.0.0:5044"} [2018-03-14T17:05:02,422][INFO ][logstash.pipeline ] Pipeline started succesfully {:pipeline_id=>"main", :thread=>"#<Thread:0x5506295b sleep>"} [2018-03-14T17:05:02,429][INFO ][org.logstash.beats.Server] Starting server on port: 5044 [2018-03-14T17:05:02,453][INFO ][logstash.agent ] Pipelines running {:count=>1, :pipelines=>["main"]} 为了能够使filebeat重新读取文件,需要停止filebeat,删除读取文件的保存点记录,并重启filebeat: cd filebeat-6.2.2-linux-x86_64 rm data/registry 添加filter后,输出的日志格式如下,发现不仅输出了日志原文,同时对日志进行解析切割,存放到相应的字段中。 { "host" => "yf-beidou-dmp00.yf01.baidu.com", "clientip" => "121.107.188.202", "verb" => "GET", "tags" => [ [0] "beats_input_codec_plain_applied" ], "message" => "121.107.188.202 - - [04/Jan/2015:05:27:57 +0000] \"GET /presentations/logstash-monitorama-2013/images/kibana-dashboard3.png HTTP/1.1\" 200 171717 \"-\" \"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_9_1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/32.0.1700.107 Safari/537.36\"", "beat" => { "name" => "yf-beidou-dmp00.yf01.baidu.com", "version" => "6.2.2", "hostname" => "yf-beidou-dmp00.yf01.baidu.com" }, "httpversion" => "1.1", "auth" => "-", "response" => "200", "bytes" => "171717", "ident" => "-", "@version" => "1", "request" => "/presentations/logstash-monitorama-2013/images/kibana-dashboard3.png", "offset" => 21927, "prospector" => { "type" => "log" }, "@timestamp" => 2018-03-14T09:06:47.927Z, "source" => "/home/work/zion_package/elastic/filebeat/logstash-tutorial.log", "timestamp" => "04/Jan/2015:05:27:57 +0000", "agent" => "\"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_9_1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/32.0.1700.107 Safari/537.36\"", "referrer" => "\"-\"" } 使用Geoip过滤器组件增强数据处理 geoip也是filter组件的一种,用于从ip地址中解析出位置信息,并添加到输出日志中;geoip需要配置需要指定存放ip地址的字段,在本例中,我们使用通过gork解析后clientip字段;因为过滤器是按顺序过滤,所以需要确保geoip的过滤器在之前配置的gork过滤器之后,配置文件如下: input { beats { port => "5044" } } filter { grok { match => { "message" => "%{COMBINEDAPACHELOG}"} } geoip { # 指定要进行ip解析的字段 source => "clientip" } } output { stdout { codec => rubydebug } } 停止filebeat,删除data/registry文件,重启filebeats后再次查看日志,发现新增了地理位置信息: { "host" => "yf-beidou-dmp00.yf01.baidu.com", "clientip" => "218.30.103.62", "verb" => "GET", "tags" => [ [0] "beats_input_codec_plain_applied" ], "message" => "218.30.103.62 - - [04/Jan/2015:05:28:43 +0000] \"GET /blog/geekery/xvfb-firefox.html HTTP/1.1\" 200 10975 \"-\" \"Sogou web spider/4.0(+http://www.sogou.com/docs/help/webmasters.htm#07)\"", "beat" => { "name" => "yf-beidou-dmp00.yf01.baidu.com", "version" => "6.2.2", "hostname" => "yf-beidou-dmp00.yf01.baidu.com" }, "httpversion" => "1.1", "auth" => "-", "response" => "200", "bytes" => "10975", "ident" => "-", "@version" => "1", "request" => "/blog/geekery/xvfb-firefox.html", "geoip" => { "location" => { "lat" => 39.9289, "lon" => 116.3883 }, "latitude" => 39.9289, "continent_code" => "AS", "region_code" => "11", "country_code3" => "CN", "country_code2" => "CN", "longitude" => 116.3883, "city_name" => "Beijing", "country_name" => "China", "ip" => "218.30.103.62", "region_name" => "Beijing", "timezone" => "Asia/Shanghai" }, "offset" => 22310, "prospector" => { "type" => "log" }, "@timestamp" => 2018-03-14T09:22:31.299Z, "source" => "/home/work/zion_package/elastic/filebeat/logstash-tutorial.log", "timestamp" => "04/Jan/2015:05:28:43 +0000", "agent" => "\"Sogou web spider/4.0(+http://www.sogou.com/docs/help/webmasters.htm#07)\"", "referrer" => "\"-\"" } 将logstash数据输出到elasticsearch 1)修改output,写入数据到elasticsearch:修改first-pipeline.conf文件,配置elasticsearch访问地址; input { beats { port => "5044" } } filter { grok { match => { "message" => "%{COMBINEDAPACHELOG}"} } geoip { source => "clientip" } } output { elasticsearch { # 指定elasticsearch地址,指定多个地址,logstash会自动负载均衡 hosts => [ "ip1:port1", "ip2,port2" ] # 如果设置用户名和密码,则需要指定如下两个字段; # 用户必须具有对index的CRUD权限; user => "username" password => "password" } } 2)重新发送消息:停止filebeat,删除data/registry文件,重启filebeats;3)检索日志:执行如下语句,查询是否有日志写入elasticsearch,ip和端口是elasticsearch实例的ip和端口;因为first-pipeline.conf中未指定创建index的名称格式,默认为:logstash-yyyy.MM.dd(日期部分需要替换);如果未指定用户名/密码,则不需要-u参数; curl -XGET 'ip:port/logstash-2018.03.14/_search?pretty&q=response=200' -u username:password 检索结果类似如下json串: { "took" : 20, "timed_out" : false, "_shards" : { "total" : 5, "successful" : 5, "skipped" : 0, "failed" : 0 }, "hits" : { "total" : 98, "max_score" : 2.3988724, "hits" : [ { "_index" : "logstash-2018.03.14", "_type" : "doc", "_id" : "t76VJGIBe9U4s2F_OL_W", "_score" : 2.3988724, "_source" : { "verb" : "GET", "@timestamp" : "2018-03-14T12:56:19.779Z", "response" : "200", "agent" : "\"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_9_1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/32.0.1700.77 Safari/537.36\"", "source" : "/home/work/zion_package/elastic/filebeat/logstash-tutorial.log", "host" : "yf-beidou-dmp00.yf01.baidu.com", "auth" : "-", "clientip" : "83.149.9.216", "geoip" : { "country_code3" : "RU", "continent_code" : "EU", "ip" : "83.149.9.216", ... ... 4)在kibana上配置index-pattern,通过Discover检索日志:点击菜单:Management -> Index Pattern; 点击 Create Index Pattern,创建index pattern; 点击菜单:Discover,检索日志; 参考 官方视频:Getting Started with Logstash官方文档:Getting Started with Logstash