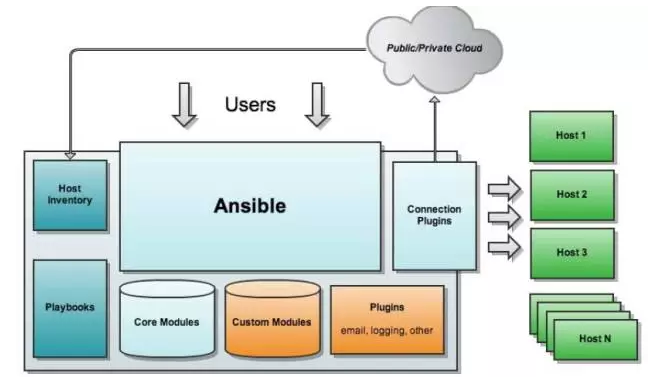
android107 指针入门
#include <stdio.h> #include <stdlib.h> //指针就是内存地址 //32为操作系统最大是4G内存,32为系统则是2的32次方, //所以只能表示2的32次方个内存地址, 也就是2的32次方个字节就是4G. main(){ int i;//i是内存空间的别名 ,i里面保存的是内存地址, i = 3; printf("%#x\n", &i); system("pause"); } #include <stdio.h> #include <stdlib.h> main(){ //野指针:没有赋值的指针 int* p; int i; double d = 3.14; p = &d; //不是野指针了, //*p = 23; printf("%#x\n", p);//打印地址,p里面存的是地址 printf("%lf\n", *p); system("pause"); } /*##*的三种用法 1. 乘法 2. int* p:定义一个指针变量p,p中存放一个内存地址,这个地址所存放的数据规定是int型 3. *p:取出p中保存的内存地址存放的数据 ##数据传递 * 所有语言所有平台,都只有值传递,引用传递传递的值是内存地址 */ #include <stdio.h> #include <stdlib.h> void swap(int* p, int* q){ int temp = *p; *p = *q; *q = temp; } main(){ int i = 3; int j = 5; printf("i=%d\n", i); printf("j=%d\n", j); swap(&i, &j); printf("i=%d\n", i); printf("j=%d\n", j); system("pause"); } #include <stdio.h> #include <stdlib.h> void function(int* p, int* q){ *p += 15; *q += 15; } main(){ int i = 10; int j = 20; function(&i, &j); printf("%d\n", i); printf("%d\n", j); system("pause"); } #include <stdio.h> #include <stdlib.h> void function(int** p){ int i = 3; printf("i的地址为%#x\n", &i); //p就是取出p内存空间的值 //*p:就是取出p内存空间值的内存空间的值, *p = &i;//修改P所指向的内存空间值的内存空间的值 } main(){ int* mainp;//mainp在栈中存的是地址,指向堆中的一个int数据 的内存空间 。 function(&mainp);//&mainp在栈中存的是地址的地址也就是 mainp的地址,也就是指向mainp的内存空间。 printf("主函数中获取i的地址为%#x\n", mainp); //数据幻影 printf("主函数中获取i的值为%d\n", *mainp);//-2因为i是局部变量已经销毁了 system("pause"); } 内存分析:0级指针,一级指针,二级指针都有, 二级指针是曾曾用名,一级指针是曾用名。 #include <stdio.h> #include <stdlib.h> main(){ //char arr[] = "hello"; int arr[5] = {1,2,3,4,5}; printf("%#x\n", &arr[0]);//0x22ff50 printf("%#x\n", &arr[1]); printf("%#x\n", &arr[2]); printf("%#x\n", &arr[3]); //arr = printf("数组名字的地址%#x\n", &arr);//也是输出第0个元素的地址 printf("数组名字的地址%#x\n", arr);//也是输出第0个元素的地址 //char* p = &arr; int* p = &arr; //+1表示向右偏移一个单位 printf("%d\n", *(p+0));// 1 printf("%d\n", *(p+1));//2 printf("%d\n", *(p+2));//3 printf("%d\n", (p+2)-p); //2 system("pause"); } #include <stdio.h> #include <stdlib.h> main(){ char* cp; int* ip; short* lizhip; int i; char c; cp = &c; ip = &i; //指针的长度都是4个字节 printf("%d\n", sizeof(cp));//4 printf("%d\n", sizeof(ip));//4 printf("%d\n", sizeof(lizhip));//4 printf("%d\n", (p+2)-p); //2,偏移量。 printf("%d\n", cp-ip);//出错, 连续内存空间相加减是可以的,非连续的内存空间相加减是没有意义的, system("pause"); } 本文转自农夫山泉别墅博客园博客,原文链接:http://www.cnblogs.com/yaowen/p/4979472.html,如需转载请自行联系原作者