Python打包系统简单入门
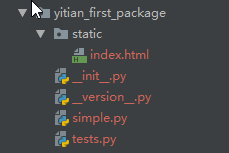
最近把pyenv、pipenv这种都研究了一下,然后我发现一个严重的问题:就是我虽然看了半天这些工具,但是我对Python自己的打包系统却完全没有了解。所以这篇文章就来研究一下Python自带的打包系统。 pip 先来详细介绍一下pip的用法,平时基本上我们用pip的时候也就是一个pip install。其实pip也有很多特性,在此先介绍一下常用的一些特性。此部分参考了pip文档,想了解更多的话可以看原文。 安装 最常用的命令就是安装了,除此以外还可以指定版本号: $ pip install SomePackage # 不指定版本号,安装最新版 $ pip install SomePackage==1.0.4 # 指定版本号 $ pip install 'SomePackage>=1.0.4' # 指定最小版本号 $ pip install -r requirements.txt # 从需求文件安装 $ pip install -e . # 从本地项目setup.py安装 使用代理服务器 当从官方的PyPI源安装比较慢的时候,可以考虑使用代理服务器,指定代理服务器的方法有三种: 使用--proxy参数在命令行指定,代理格式为[user:passwd@]proxy.server:port。 在配置文件中指定。 设置http_proxy, https_proxy 和no_proxy环境变量。 使用需求文件(requirements.txt) 在需要很多pip包的项目中,用pip一个个安装包不是一个好办法,这时候可以考虑使用需求文件。 如果要生成需求文件,用下面的命令。这会将当前Python环境中的所有包的当前版本状态保存下来,将来安装的时候会精确还原到冻结的那个状态。 pip freeze > requirements.txt 要从需求文件中安装,则是用下面的命令: pip install -r requirements.txt 官方文档还给出了一个带注释的实例需求文件: # ####### example-requirements.txt ####### # ###### 没有版本标识符的包,会安装最新版 ###### nose nose-cov beautifulsoup4 # ###### 带版本标识符的包 ###### # 版本标识符的资料 https://www.python.org/dev/peps/pep-0440/#version-specifiers docopt == 0.6.1 # Version Matching. Must be version 0.6.1 keyring >= 4.1.1 # Minimum version 4.1.1 coverage != 3.5 # Version Exclusion. Anything except version 3.5 Mopidy-Dirble ~= 1.1 # Compatible release. Same as >= 1.1, == 1.* # ###### 还可以指定其他的需求文件 ###### -r other-requirements.txt # # ###### 还可以指定本地货网络上的特定包 ###### ./downloads/numpy-1.9.2-cp34-none-win32.whl http://wxpython.org/Phoenix/snapshot-builds/wxPython_Phoenix-3.0.3.dev1820+49a8884-cp34-none-win_amd64.whl # ###### Additional Requirements without Version Specifiers ###### # 和第一部分一样,这里这些部分没有顺序需求,可以随意改变位置 rejected green # 版本标识符用来指定包的版本,有以下几个例子: SomeProject SomeProject == 1.3 SomeProject >=1.2,<.2.0 SomeProject[foo, bar] SomeProject~=1.4.2 从6.0版本开始,pip也支持环境标记(也就是分号后面跟Python版本或者系统类型): SomeProject ==5.4 ; python_version < '2.7' SomeProject; sys_platform == 'win32' 卸载 卸载某个包使用下面的命令: $ pip uninstall SomePackage 列出包 要列出所有已安装的包: $ pip list docutils (0.9.1) Jinja2 (2.6) Pygments (1.5) Sphinx (1.1.2) 要列出过时的包: $ pip list --outdated docutils (Current: 0.9.1 Latest: 0.10) Sphinx (Current: 1.1.2 Latest: 1.1.3) 要列出某个已安装的包的详细信息: $ pip show sphinx --- Name: Sphinx Version: 1.1.3 Location: /my/env/lib/pythonx.x/site-packages Requires: Pygments, Jinja2, docutils 搜索 要搜索一个包,用下面的命令,搜索结果可能有很多: $ pip search "query" 更新 要更新一个包,使用-U或者--upgrade参数: pip install -U <pkg> 如果想更新所有的包,很遗憾,pip并没有提供该功能,我在StackOverFlow上找到一个看起来比较简单的解决办法,就是在Python解释器中执行下面的代码: import pkg_resources from subprocess import call packages = [dist.project_name for dist in pkg_resources.working_set] call("pip install --upgrade " + ' '.join(packages), shell=True) 以上就是pip的一些简单用法,详情可参考官方文档。 打包项目 下面就进入本文的正题,Python的打包系统上。基本上我们不需要完全了解打包系统,只要学会简单的几个点就可以打包自己的类库了。打包需要distutils、setuptools、wheel等类库,不过基本上我们只需要写好其中最重要的setup.py,就可以完成打包工作了。distutils是官方的类库,在当年有很广泛的使用,不过到了现在很难用。distutuils类库的核心就是setup函数,我们需要将项目的各种信息作为参数传递给setup函数,然后就可以用相关命令创建项目分发包了。关于distutils的用法,可以参考官方文档。 当然现在项目基本都不用distutils了,有更好用的第三方替代品,那就是setuptools,它可以算作是distutils的加强版,功能更加强大、使用更加简单,这就是这里要介绍的。其实从文档就可以看出来,distutils毕竟时间比较早,有些接口设计的不太合理甚至有些反人类,setuptools的文档就简单多了。 准备项目 为了做演示,首先需要准备一个项目,一个项目应该包括README和LICENSE等文件,README文件是Markdown格式的文本文件,用于描述项目自身;LICENSE文件是授权文件,列出项目使用者应该遵循的各种条款。下图是我的项目结构。 项目结构 此外还可能存在几个文件: setup.cfg。对应的配置文件,一般情况下可以不要。 MANIFEST.in。清单文件,当项目中需要一些没办法自动包括到源代码分发包的文件时,可能需要用到它。 具体文件内容就不列出了。需要注意my_package/__init__.py文件中应该有如下一行标识包名: name = 'yitian_first_package' 编写setup.py文件 用setuptools来编写setup.py文件是一件非常简单的事情,而且有很多例子可供参考,我挑选了Kenneth Reitz(requests、pipenv等类库的作者)写的例子,做了一些修改并翻译了一些注释: #!/usr/bin/env python # -*- coding: utf-8 -*- # 注意 如果要使用上传功能,需要安装twine包: # $ pip install twine import io import os import sys from shutil import rmtree from setuptools import find_packages, setup, Command # 包的元信息 NAME = 'yitian_first_package' DESCRIPTION = '项目的简短描述,不超过200字符' URL = 'https://github.com/techstay/python-study' EMAIL = 'lovery521@gmail.com' AUTHOR = '易天' REQUIRES_PYTHON = '>=3.6.0' VERSION = '0.1.0' KEYWORDS = 'sample setuptools development' # 项目依赖,也就是必须安装的包 REQUIRED = [ 'requests-html' ] # 项目的可选依赖,可以不用安装 EXTRAS = { # 'fancy feature': ['django'], } # 剩下部分不用怎么管 :) # ------------------------------------------------ # 除了授权和授权文件标识符! # 如果你改了License, 记得也相应修改Trove Classifier! here = os.path.abspath(os.path.dirname(__file__)) # 导入README文件作为项目长描述. # 注意 这需要README文件存在! try: with io.open(os.path.join(here, 'README.md'), encoding='utf-8') as f: long_description = '\n' + f.read() except FileNotFoundError: long_description = DESCRIPTION # 当前面没指定版本号的时候,将包的 __version__.py 模块加载进来 about = {} if not VERSION: with open(os.path.join(here, NAME, '__version__.py')) as f: exec(f.read(), about) else: about['__version__'] = VERSION class UploadCommand(Command): """上传功能支持""" description = 'Build and publish the package.' user_options = [] @staticmethod def status(s): """Prints things in bold.""" print('\033[1m{0}\033[0m'.format(s)) def initialize_options(self): pass def finalize_options(self): pass def run(self): try: self.status('Removing previous builds…') rmtree(os.path.join(here, 'dist')) except OSError: pass self.status('Building Source and Wheel (universal) distribution…') os.system('{0} setup.py sdist bdist_wheel --universal'.format(sys.executable)) self.status('Uploading the package to PyPI via Twine…') os.system('twine upload dist/*') self.status('Pushing git tags…') os.system('git tag v{0}'.format(about['__version__'])) os.system('git push --tags') sys.exit() # 神奇的操作,一个函数完事 setup( name=NAME, version=about['__version__'], description=DESCRIPTION, long_description=long_description, long_description_content_type='text/markdown', author=AUTHOR, author_email=EMAIL, python_requires=REQUIRES_PYTHON, url=URL, keywords=KEYWORDS, # 项目中要包括和要排除的文件,setuptools可以自动搜索__init__.py文件来找到包 packages=find_packages(exclude=('tests',)), # 如果项目中包含任何不在包中的单文件模块,需要添加py_modules让setuptools能找到它们: # py_modules=['yitian_first_package'], # entry_points={ # 'console_scripts': ['mycli=mymodule:cli'], # }, install_requires=REQUIRED, extras_require=EXTRAS, # 老旧的distutils需要手动添加项目中需要的非代码文件,setuptools可以用下面参数自动添加(仅限包目录下) include_package_data=True, # 如果是包的子目录下,则需要手动添加 package_data={ 'yitian_first_package': ['static/*.html'] }, license='MIT', classifiers=[ # Trove classifiers # Full list: https://pypi.python.org/pypi?%3Aaction=list_classifiers 'License :: OSI Approved :: MIT License', 'Programming Language :: Python', 'Programming Language :: Python :: 3', 'Programming Language :: Python :: 3.7', 'Programming Language :: Python :: Implementation :: CPython', 'Programming Language :: Python :: Implementation :: PyPy' ], # $ setup.py publish support. cmdclass={ 'upload': UploadCommand, }, ) 下面再讲一些在注释里没法详细解释的东西,官方文档的内容更丰富,有需要的可以查看。示例文件中其实还有几个setup参数没写全,这里再补充一下。 project_urls project_urls参数可以列出一些相关项目的URL。 project_urls={ 'Documentation': 'https://packaging.python.org/tutorials/distributing-packages/', 'Funding': 'https://donate.pypi.org', 'Say Thanks!': 'http://saythanks.io/to/example', 'Source': 'https://github.com/pypa/sampleproject/', 'Tracker': 'https://github.com/pypa/sampleproject/issues', }, python_requires参数格式就是pip中指定包版本的标识符,,指定我们项目支持的Python版本,这里再补充几个例子。 # 大版本号大于等于3 python_requires='>=3', # 版本号大于等于3.3,但是不能超过4 python_requires='~=3.3', # 支持2.6 2.7以及所有以3.3开头的Python 3版本 python_requires='>=2.6, !=3.0.*, !=3.1.*, !=3.2.*, <4', package_data和data_file package_data和data_file参数用于指定数据文件,也就是在项目中使用到的非代码文件,一般情况下通过设置include_package_data=True自动搜索就够用了,如果需要细粒度的控制,就要使用它们了,详情见setuptools 文档 - Including Data Files。 package_data指定包括在包中的数据文件,也就是“包数据文件”,这些文件会复制到包的相应目录。 package_data={ 'package_name': ['package_data.dat'], }, data_files指定放在包外的数据文件,这些文件会被复制到项目根目录下指定的相对目录中。 data_files=[('my_data', ['data/data_file'])], entry_points entry_points参数指定一些入口点,可以看做是项目提供的一些额外功能,其中最常见的就是console_scripts,用于注册脚本接口。setuptools提供的工具链可以在安装项目分发包的时候将这些接口转化为真正的可执行脚本,更多信息参考setuptools文档 - Automatic Script Creation。 entry_points={ 'console_scripts': [ 'sample=sample:main', ], }, 版本号 下面是开发、A测、B测、发布候选、最终发布等情况的版本号实例。 1.2.0.dev1 # Development release 1.2.0a1 # Alpha Release 1.2.0b1 # Beta Release 1.2.0rc1 # Release Candidate 1.2.0 # Final Release 1.2.0.post1 # Post Release 15.10 # Date based release 23 # Serial release 开发模式 setup.py文件写完之后,项目就算是可打包状态了。当然也可以继续在项目上进行工作,这时候一般希望项目既可以作为包来安装,又希望项目是可以编辑的,这时候就可以进入开发模式。这种情况下需要用下面的命令来安装包,-e选项全称是--editable,也就是可编辑的意思;.表示当前目录,也就是setup.py存在的那个目录: pip install -e . 该命令会安装install_requires中指定的所有包,以及console_scripts部分指定的脚本。依赖项会作为普通包来安装,而项目本身会以可编辑状态来安装。特别的,如果只希望安装项目本身而不安装所有依赖包,用下面的命令: pip install -e . --no-deps 如果有需要的话,还可以安装VCS或者本地目录中保存的包来替代官方索引中的包。详情请查看文档。 打包项目 终于到了观看成果的时候了,项目可以被打包成各种类型的可分发包,这里只介绍几种最常用的。 源码分发包(sdist) 这是最低等级的一种,基本上就是复制源代码,不过因此在安装的时候有一个必须的构建(可能包括编译)过程来生成各种元信息,哪怕项目是纯的Python项目。用下面的命令来生成: python setup.py sdist Wheels(轮子) 在编程界各种第三方包不是被形象地称作轮子吗(著名梗:不要重复造轮子),这里就是这个意思。轮子是一种二进制分发包,是现在最推荐的分发包格式,轮子又可以分为好几种轮子。当然,在构建轮子之前,还需要安装wheel包来提供支持。 pip install wheel 通用轮子。也就是项目中只存在Python代码,同时兼容Python 2和Python 3的轮子,用下面的命令生成。 python setup.py bdist_wheel --universal 当然也可以在setup.cfg配置文件中指定: [bdist_wheel] universal=1 纯Python轮子。和通用轮子差不多,不过只支持Python 2或者Python 3. python setup.py bdist_wheel 平台轮子。这种轮子中不仅有Python代码,一般还包括但不限于C代码写成的扩展等,因此它们只支持特定平台。 python setup.py bdist_wheel 运行以上命令之后,会在dist文件夹中生成打包好的可发布包。 发布项目 项目打包完毕,生成可可分发包之后,最后一步就是发布项目了。几乎所有的项目都被发布到了Python Package Index(简称PyPI)上了,当然如果有需求的话还可以搭建自己的私人索引,不过这就是另一个话题了。 很有意思的是,Python官方还提供了一个测试索引,它是一个和PyPI完全一样的测试网站,定期清理,可以让我们方便的练习上传项目,同时不用担心会污染官方仓库。使用方法很简单,先注册一个账户。 上传项目需要用到另一个类库twine: pip install twine 然后用下面的命令将包上传到测试索引中,该命令会提示输入刚才注册用的用户名和密码: twine upload --repository-url https://test.pypi.org/legacy/ dist/* 稍等片刻,上传应该就完成了。然后就可以在测试索引中找到我的项目了。当然由于测试索引会定期清理的缘故,可能过段时间项目和我的账户就都不存在了。 上传完成 全部流程都熟悉之后,就可以在官方索引上注册账号,并将项目上传上去,这样一来,全世界的开发者都能用到你的项目了!