Hyperledger Fabric private data是1.2版本引入的新特性,fabric private data是利用旁支数据库(SideDB)来保存若干个通道成员之间的私有数据,从而在通道之上又提供了一层更灵活的数据保护机制。本文将介绍如何在链码开发中使用fabric private data。
![fabric private data arch]()
fabric private data利用SideDB来保存私有数据,相当于在通道之上又提供了一层更细粒度的数据隐私保护机制。本文将介绍fabric private data的引入目的、基本概念与应用场景。
什么是fabric private data?
目前在Hyperledger Fabric中实现数据隐私的方法是使用通道。但是官方并不孤立为了实现数据的隐私保护而在大型网络中创建大量通道,因为这会带来额外的开销,例如管理策略、链码版本以及成员服务提供(MSP)等。在一个通道中,所有的数据要么是公开的,要么是私有的。因此如果你想要将资产转给通道外的成员会很麻烦。这就是Hyperledger Fabric引入私有交易的原因。farbic private data允许基于策略创建私有数据集,来定义通道中的哪些成员可以访问数据。可以简单地通过添加策略来管理fabric private data。这使得可以将某些数据仅对部分成员公开。
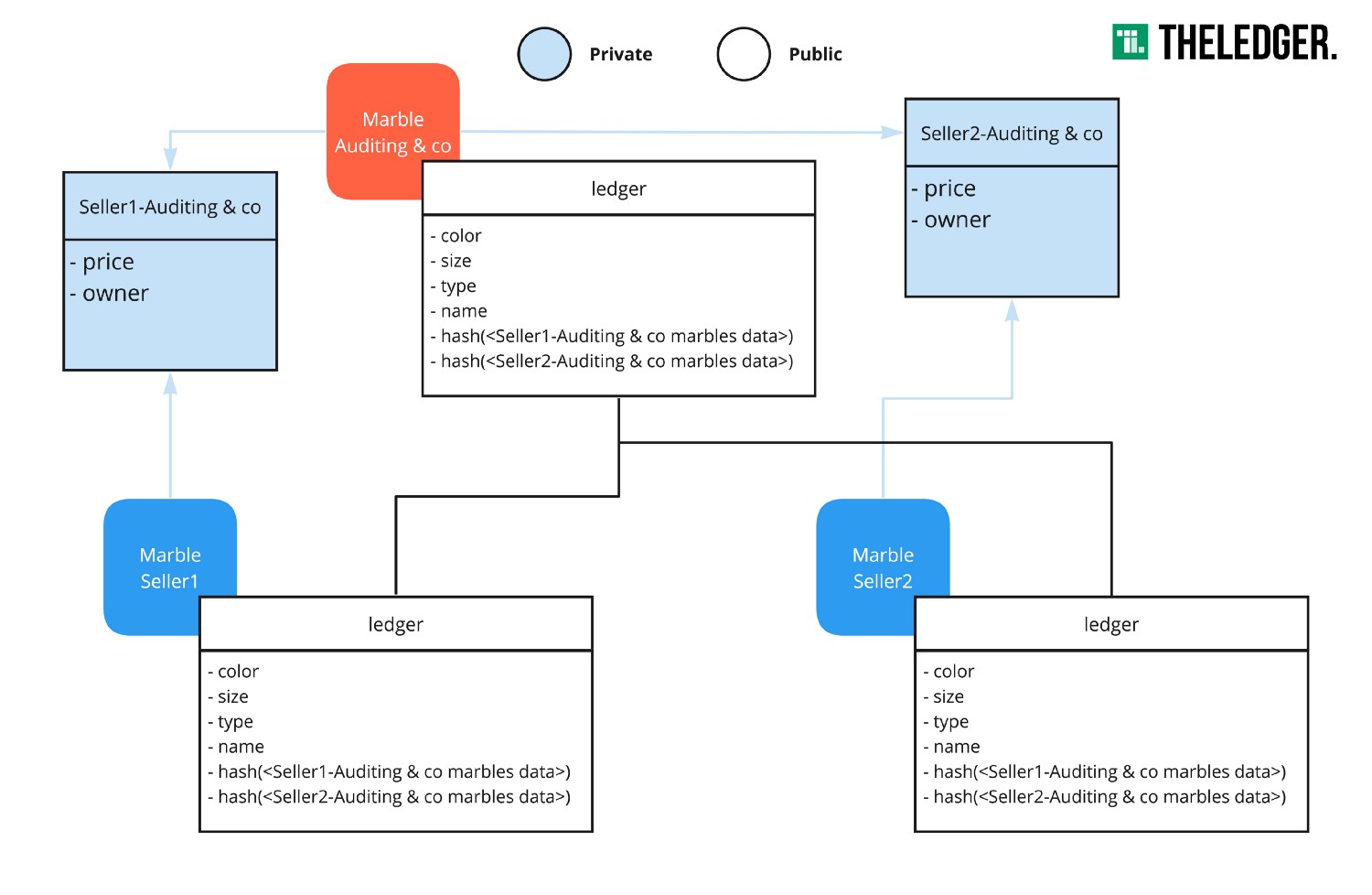
考虑一下Hyperledger Fabric的marbles示例。所有的marble数据都可以公开,除了其持有人以及价格信息,这两个数据是不能对别人公开的,价格不应该被别人了解。可能你需要跟踪这个数据,因为你需要验证在销售marble的人是否是真正的持有人。一个假想的marble审计公司可以作为你的合伙人来验证这一点。如果你使用通道,那么所有的你的行为将记录在账本状态中,而任何人都看得到。
fabric private data是如何解决上述问题的?
![concept]()
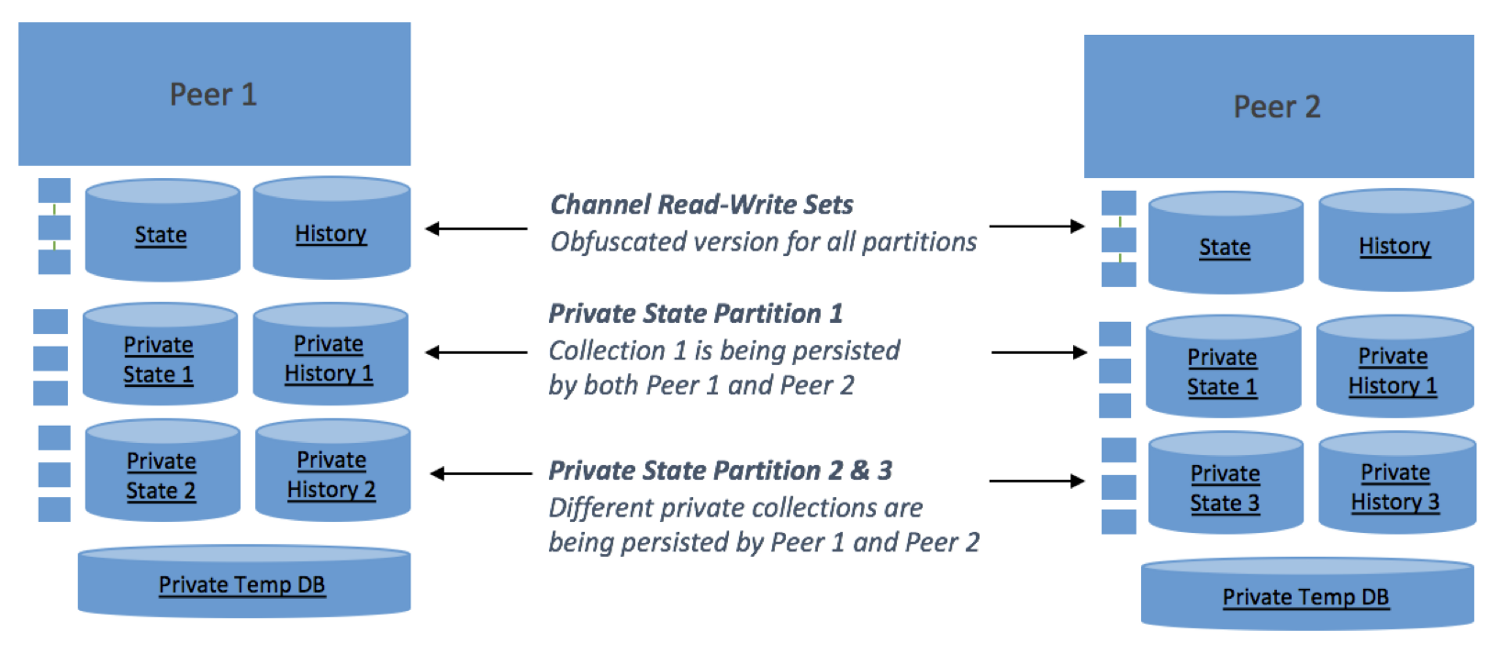
在上图中,第一个集合,Channel Read-Write Sets”是没有引入fabric private data时的架构,每一个交易都记录其状态和历史。
第二个集合,private state partition 1则显示了在两个分属不同机构的节点之间的一个共享私有状态。这个状态是根据预先的策略在节点间复制得到的。
第三个集合,private state partition 2&3则显示了fabric private data的真正为例。数据集可以被某些成员忽略。这意味着你可以为每一个marble卖家和审计者单独设立私有数据集。这些数据集允许添加一些额外的数据,主要的数据还是保存在主状态和账本中。
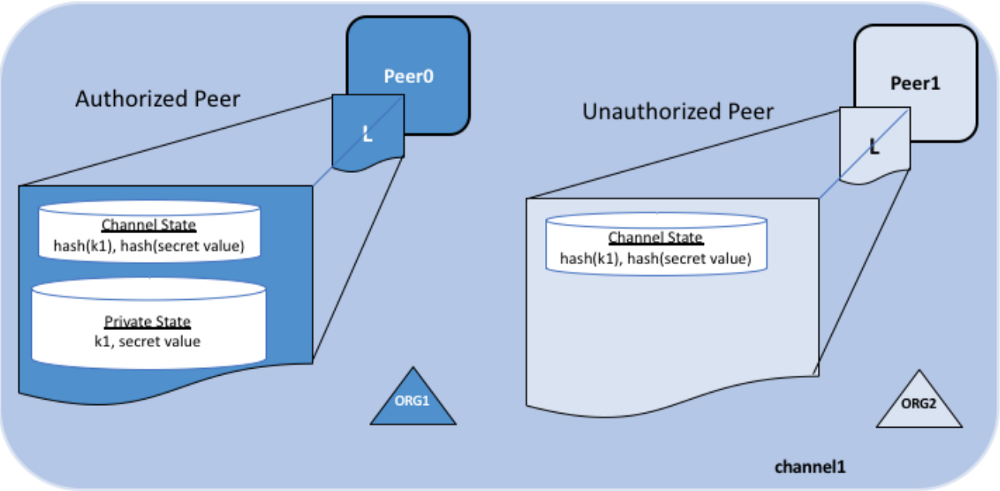
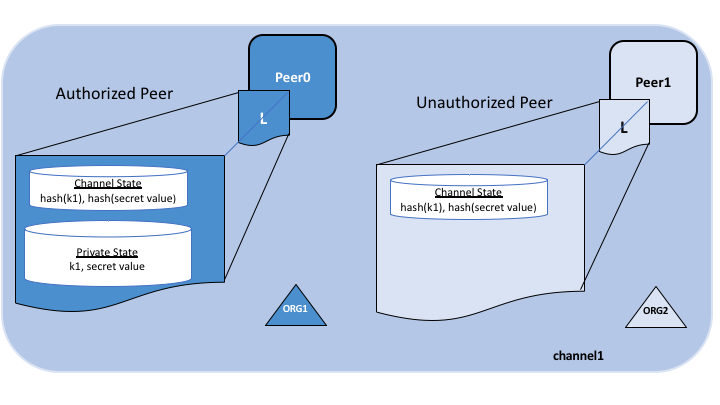
![authorized]()
被授权的节点将可以看得到在主账本上的数据哈希,以及在私有数据库中的真实数据。未得到授权的节点将不会同步私有数据库,只能看到在主账本上的数据哈希。由于哈希是不可逆的,因此这些未授权的节点无法看到真实的数据。
从更高的层面看,fabric private data解决的问题看起来是这样:
![solved]()
fabric private data用例
我们使用Hyperledger Fabric中经典的fabcar案例来展示如何使用私有数据集。initLedger函数将在我们的数据集中创建10个新车。所有的这些车辆可以被网络中的任何人查看。现在让我们创建一个私有数据库,而这个数据将只和我们持有的另一个成员车库共享。
fabric private data数据集配置
我们首先需要一个数据集配置文件collections_config.json,它包含了私有数据集名称和访问策略。访问策略类似于背书策略,这允许我们使用已经存在的策略逻辑,例如OR、AND等。
[
{
"name": "carCollection",
"policy": "OR ('Org1MSP.member','Org2MSP.member')",
"requiredPeerCount": 0,
"maxPeerCount": 3,
"blockToLive":1000000
}
]
修改链码以支持fabric private data
下面是原始的createCar函数:
async createCar(stubHelper: StubHelper, args: string[]) {
const verifiedArgs = await Helpers.checkArgs<any>(args[0], Yup.object()
.shape({
key: Yup.string().required(),
make: Yup.string().required(),
model: Yup.string().required(),
color: Yup.string().required(),
owner: Yup.string().required(),
}));
let car = {
docType: 'car',
make: verifiedArgs.make,
model: verifiedArgs.model,
color: verifiedArgs.color,
owner: verifiedArgs.owner
};
await stubHelper.putState(verifiedArgs.key, car);
}
要把数据加入私有数据集carCollection,我们需要指定目标数据集:
await stubHelper.putState(verifiedArgs.key, car, {privateCollection: 'carCollection'});
接下来,要查询车辆的话,我们也需要指定目标私有数据集:
async queryPrivateCar(stubHelper: StubHelper, args: string[]) {
const verifiedArgs = await Helpers.checkArgs<any>(args[0], Yup.object()
.shape({
key: Yup.string().required(),
}));
const car = await stubHelper.getStateAsObject(verifiedArgs.key, {privateCollection: 'carCollection'});
if (!car) {
throw new NotFoundError('Car does not exist');
}
return car;
}
同样,对于删除和更新操作,都需要指定要操作的目标私有数据集。
fabric private data链码最佳实践
当然,我们的数据中有一部分是Hyperledger Fabric网络中的任何人都看得到的。但是,其中某些数据是私有的,并且保存在私有数据集中,因此只能被数据集配置文件中定义的对等节点访问。
我们建议在公开和私有数据集中使用相同的键来保存数据,以便更易于数据的提取操作。
如果要快速掌握hyperledger fabric区块链的开发,推荐汇智网的在线互动实战教程:
原文:Fabric private data入门实战