Hyperledger Fabric推荐Kafa用于生产环境。Kafa是一个分布式、具有水平伸缩能力、崩溃容错能力的日志系统。在Hyperledger Fabric区块链中可以有多个Kafka节点,使用zookeeper进行同步管理。本文将介绍Kfaka的基本工作原理,以及在HyperledgerFabric中使用Kafka和zookeeper实现共识的原理,并通过一个实例剖析Hyperledger Farbic中Kafka共识的达成过程。
如果希望快速掌握Fabric区块链的链码及应用开发,建议访问汇智网的在线互动课程:
一、Kafka工作原理
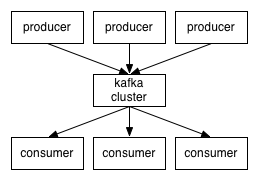
Kafka本质上是一个消息处理系统,它使用的是经典的发布-订阅模型。消息的消费者订阅特定的主题,以便收到新消息的通知,生产者则负责消息的发布。
![kafka theory]()
当主题的数据规模变得越来越大时,可以拆分为多个分区,Kafka保障在一个分区内的消息是按顺序排列的。
Kafka并不跟踪消费者读取了哪些消息,也不会自动删除已经读取的消息。Kafka会保存消息一段时间,例如一天,或者直到数据规模超过一定的阈值。消费者需要轮询新的消息,这是的他们可以根据自己的需求来定位消息,因此可以重放或重新处理事件。消费者处于不同的消费者分组,对应一个或多个消费者进程。每个分区被分贝给单一的消费者进程,因此同样的消息不会被多次读取。
崩溃容错机制是通过在多个Kafka代理之间复制分区来实现的。因此如果一个代理由于软件或硬件故障挂掉,数据也不会丢失。当然接下来还需要一个领导-跟随机制,领导者持有分区,跟随者则进行分区的复制。当领导者挂掉后,会有某个跟随者转变为新的领导者。
如果一个消费者订阅了某个主体,那么它怎么知道从哪个分区领导者来读取订阅的消息?
答案在于zookeeper服务。
zookeeper是一个分布式key-value存储库,通常用于存储元数据及集群机制的实现。zookeeper允许服务(Kafka代理)的客户端订阅变化并获得实时通知。这就是代理如何确定应当使用哪个分区领导者的原因。zookeeper有超强的故障容错能力,因此Kafka的运行严重依赖于它。
在zookeeper中存储的元数据包括:
- 消费者分组在每个分区的读取偏移量
- 访问控制清单,用于访问授权与限制
- 生产者及消费者配额,每秒最多消息数量
- 分区领导者及健康信息
二、Hyperledger Fabric中的Kafka
要理解在超级账本Hyperledger Fabric中的Kafka是如何工作的,首先需要理解几个重要的术语:
- Chain - 指的是一组客户端(通道/channel)可以访问的日志
- Channel - 一个通道类似于一个主题,授权的对等节点(peer)可以订阅并且成为通道的成员。 只有通道的成员可以在通道上交易,一个通道中的交易在其他通道中看不到。
- OSN - 即排序服务节点(Ordering Service Node),在Fabric中被称为排序节点。排序节点负责:
- 进行客户鉴权
- 允许客户端通过一个简单的接口写入或读取通道
- 执行配置交易的过滤与验证,实现通道的重新配置或创建新的通道
- RPC - 即远程过程调用(Remote Procedure Call),是一种用于调用其他机器上的服务而无需了解 通信与实现细节的通信协议,目的是像调用本地函数一样调用网络中其他机器上的函数
- 广播PRC - 交易提交调用,由排序节点执行
- 分发RPC - 交易分发请求,当交易由kafka代理处理后,分发给请求节点
注意,虽然在Hyperledger Fabric中Kafka被称为共识(Consensus),但是其核心是交易排序服务以及额外的崩溃容错能力。
在Hyperledger Fabric中的Kafka实际运行逻辑如下:
- 对于每一条链,都有一个对应的分区
- 每个链对应一个单一的分区主题
- 排序节点负责将来自特定链的交易(通过广播RPC接收)中继到对应的分区
- 排序节点可以读取分区并获得在所有排序节点间达成一致的排序交易列表
- 一个链中的交易是定时分批处理的,也就是说当一个新的批次的第一个交易进来时,开始计时
- 当交易达到最大数量时或超时后进行批次切分,生成新的区块
- 定时交易是另一个交易,由上面描述的定时器生成
- 每个排序节点为每个链维护一个本地日志,生成的区块保存在本地账本中
- 交易区块通过分发RPC返回客户端
- 当发生崩溃时,可以利用不同的排序节点分发区块,因为所有的排序节点都维护有本地日志
![kafka theory]()
三、Hyperledger Fabric Kafka实例解析
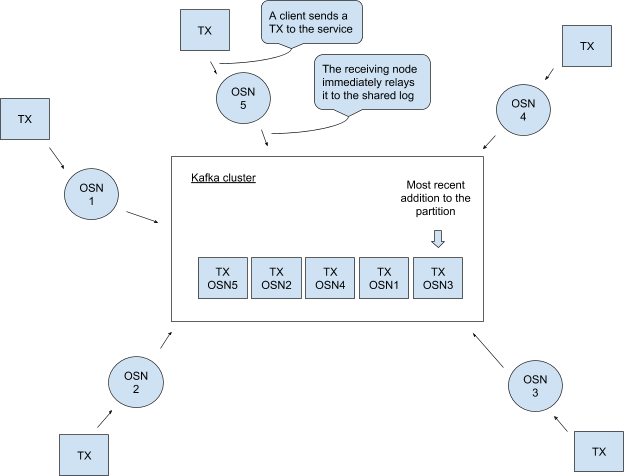
考虑下图,假设排序节点OSN0和OSN2时连接到广播客户端,OSN1连接到分发客户端。
![kafka sample]()
- OSN0已经有了交易foo,中继到kafka集群
- 此时OSN2将交易baz广播到集群中
- 最后,交易bar由OSN0发送到集群中
- 集群现在有三个交易,可以在图中看到三个交易的在日志中的位置偏移量
- 客户端发送分发请求,在OSN1的本地日志中,上述三个交易在4#区块里。
- 因此OSN1将4#区块返回客户端,处理结束
Kakfa的高性能对于Hyperledger Fabric有很大的帮助,多个排序节点通过Kafka实现同步,而Kafka本身并不是排序节点,它只是将排序节点通过流连接起来。虽然Kafka支持崩溃容错,它并不能提供对网络中恶意攻击的保护。需要一种拜占庭容错方案(BFT)才可以对抗恶意的攻击,但是目前在Farbic框架中还有待实现这一机制。
总而言之,在Hyperledger Farbic中,Kafka共识模块是可以用于生产环境的,它可以支持崩溃容错,但无法对抗恶意攻击。
原文:The ABCs of Kafka in Hyperledger Fabric