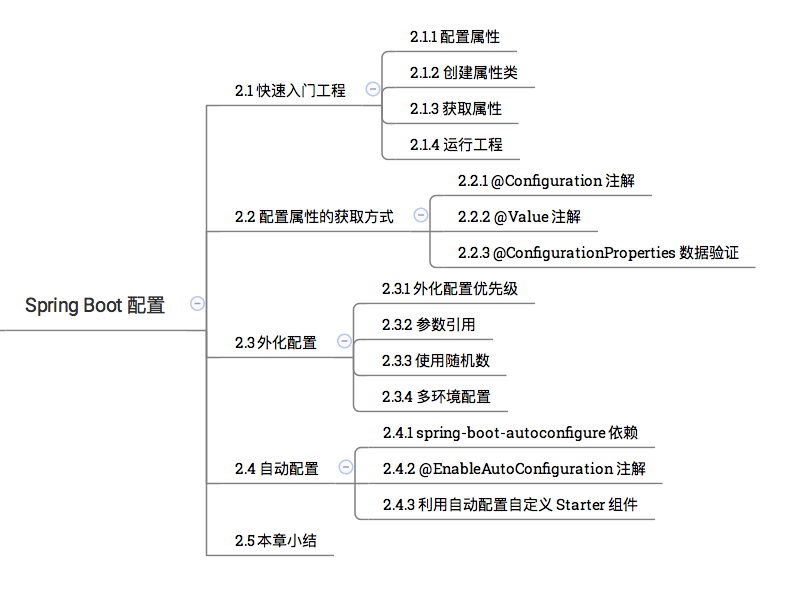
完全分布模式hadoop集群安装配置之二 添加新节点组成分布式集群
前文说到如何搭建集群中第一个节点,这篇将说到如何向集群添加节点。这篇是基于前文的,没有看过前文的可以参考此链接:http://www.cnblogs.com/mikelij/archive/2012/03/06/2380937.html 2 向集群添加节点 前文已经建立了一个节点的hadoop集群。现在要做的添加节点。安装JDK, 创建hadoop用户等见前文。这里就不重复了。 2.1 检查主机名,修改/etc/hostname, /etc/hosts 新节点需要在这个集群里叫一个名字,给此节点命名,比如slavenode1, slavenode2, etc.集群里新加入的服务器都需要在/etc/hostname中改名,将规定的服务器名放在/etc/hostname文件中。然后将已有服务器上的/etc/hosts拷贝过来。再加上此新节点的主机名。然后再复制到群里每一个服务器中。即所有集群中服务器的/etc/hosts文件要一样。 2.2 配置SSH Key以便hadoop用户无密码登录集群 与前文不同的是,此处只需要将之前的节点产生的ssh key等拷贝过来就可以了。用hadoop用户登录, sudo apt-get install ssh 安装完ssh就可以从已有的服务器上拷贝ssh key了。 mkdir /home/hadoop/.ssh scp hadoop@namenode:/home/hadoop/.ssh/* /home/hadoop/.ssh/ 这就拷贝过来了。之所以要从已有服务器上拷贝ssh key,是因为如果两个服务器的ssh key不一致,则第一次连服务器时,还是需要密码的。这里的需求是hadoop用户连任何一个集群中的服务器都不需要密码,因此需要拷贝已有服务器上的ssh key. 下面需要从此节点用ssh命令连 到已有的所有节点上去。已有的节点只有一个时,假设本节点的主机名是slavenode1, 就ssh namenode, ssh localhost, ssh slavenode1。如果已经有namenode, slavenode1, slavenode2...到slavenode6, 那么就尝试ssh namenode, ssh slavenode1, ssh slavenode2, ..., ssh slavenode6, ssh localhost. 保证这些连接都是不需要密码就可连接的就可以了。另外在换到其他机器上,都ssh 此节点的主机名,如ssh slavenode1s。这样的方法,就可以保证每台机器间都可以用ssh无密码就可以连接。用的用户都是hadoop。 2.3 安装hadoop包 可参考前文的1.5, 这里就不重复了。 2.4 namenode上的hadoop配置 集群里要加入新的节点,可以在namenode服务器上的mapred-site.xml中加入dfs.hosts和mapred.hosts两个元素。即象这样: <property> <name>dfs.hosts</name> <value>/usr/local/hadoop/hadoop-0.20.203.0/conf/slaves</value></property><property> <name>mapred.hosts</name> <value>/usr/local/hadoop/hadoop-0.20.203.0/conf/slaves</value></property> 然后再在/usr/local/hadoop/hadoop-0.20.203.0/conf/slaves文件中写上集群中所有的节点的主机名。一个主机名占一行。如: namenode slavenode1 slavenode2 ... 如果dfs.hosts和mapred.hosts已经加好了,就只需要到slaves中加入一行。 2.5 新加入节点的hadoop配置 集群中所有节点的hadoop配置要全部保持一致。即那些core-site.xml, hdfs-site.xml, mapred-site.xml, masters, slaves可以从已有节点处拷贝过来。包括/etc/environment也可以从已有节点那里拷贝过来。用scp命令,上面已经用过了,再用scp拷贝这些文件过来。 2.6 新加入节点启动 start-dfs.sh start-mapred.sh 2.7 通知namenode和jobtracker有新节点加入 在第一台服务器(namenode兼jobtracker)运行的情况下,到第一台服务器那里, hadoop dfsadmin -refreshNodes 这是通知hdfs有新节点加入 hadoop mradmin -refreshNodes 这是通知jobtracker有新节点加入 2.8 验证集群是否正常工作 还是老办法,用一些常用命令将一些服务器上的本地文件方到服务器上,如: hadoop fs -put testfolder uploadfolder 再拷贝,删除等做一做。 另外验证jobtracker和所有的tasktracker是否正常工作,还是用wordcount示例来运行: hadoop jar hadoop-examples-0.20.203.0.jar wordcount input output 得到大概这样的结果就对了, 即map增长到100%, reduce也增长到100%。 访问http://namenode:50070/可以看到集群里所有的datanode 还有http://namenode:50030/可以看到集群里所有的tasktracker 2.7 启动集群 namenode上运行: start-all.sh slavenode上运行: start-dfs.sh start-mapred.sh 2.8 停止集群 slavenode上运行: stop-mapred.sh stop-dfs.sh namenode上运行: stop-all.sh 2.9 遇到的问题 Too many fetch-failures问题 这次还是遇到了这个问题,和单机时一样的错误信息Too many fetch-failures,略有不同的是reduce不是卡在0%,而是卡在17%那里就不动了。 这次又是到处检查,最后发现是第一台服务器的/etc/hosts文件里少写了一个服务器名字。将这个服务器名字补上以后,这个wordcount示例就可以正常运行了。 所以集群中所有服务器的/etc/hosts, core-site.xml, hdfs-site.xml, mapred-site.xml, masters, slaves,还有ssh key所在.ssh目录等文件和目录都需完全一样。 以上说的是往集群里添加节点,这里说的是添加第二个节点,此过程适用于以后所有新节点的添加。第三个一直到第n个都是按同样的方法来添加。只要重复以上过程就可以了。 本文就说到这里。后文再说一些hadoop集群管理的内容。