Python爬虫入门教程 15-100 石家庄政民互动数据爬取
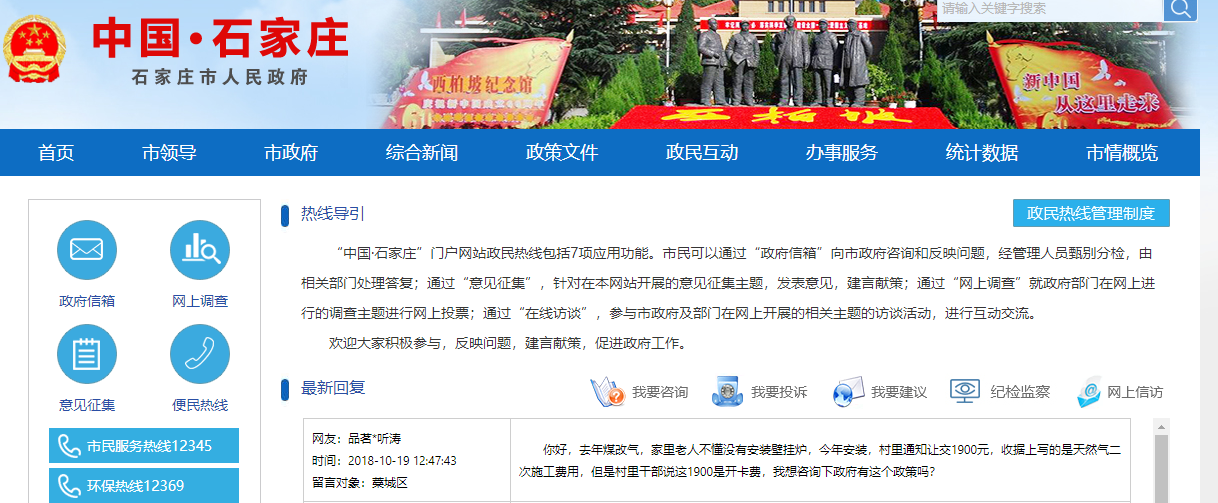
1. 石家庄政民互动数据爬取-写在前面 今天,咱抓取一个网站,这个网站呢,涉及的内容就是 网友留言和回复,特别简单,但是网站是gov的。网址为http://www.sjz.gov.cn/col/1490066682000/index.html 首先声明,为了学习,绝无恶意抓取信息,不管你信不信,数据我没有长期存储,预计存储到重装操作系统就删除。 2. 石家庄政民互动数据爬取-网页分析 点击更多回复 ,可以查看到相应的数据。 数据量很大14万条,,数据爬完,还可以用来学习数据分析,真是nice 经过分析之后,找到了列表页面。数据的爬取这次我们采用的是 selenium ,解析页面采用lxml,数据存储采用pymongo ,关于selenium 你可以去搜索引擎搜索相关的教程,好多的,主要就是打开一个浏览器,然后模拟用户的操作,你可以去系统的学习一下。 3. 石家庄政民互动数据爬取-撸代码 导入必备模块 from selenium import webdriver from selenium.common.exceptions import TimeoutException from selenium.webdriver.common.by import By from selenium.webdriver.support.ui import WebDriverWait from selenium.webdriver.support import expected_conditions as EC from lxml import etree import pymongo import time 打开浏览器,获取总页码 这个操作最重要的步骤,你搜索之后就会知道,需要提前下载一个叫做 chromedriver.exe 的东东,然后把他配置好,自行解决去吧~ # 加载浏览器引擎,需要提前下载好 chromedriver.exe 。 browser = webdriver.Chrome() wait = WebDriverWait(browser,10) def get_totle_page(): try: # 浏览器跳转 browser.get("http://www.sjz.gov.cn/zfxxinfolist.jsp?current=1&wid=1&cid=1259811582187") # 等待元素加载到 totle_page = wait.until( EC.presence_of_element_located((By.CSS_SELECTOR,'input[type="hidden"]:nth-child(4)')) ) # 获取属性 totle = totle_page.get_attribute('value') # 获取首页数据,这个地方先不必须 ############################## #get_content() ############################## return totle except TimeoutError: return get_totle_page() 上面的代码在测试之后,你会得到如下结果 这时候,你已经得到20565这个总页码数目了,只需要进行一系列循环的操作即可,接下来有一个重要的函数,叫做next_page 这个函数里面,需要进行一个模拟用户行为的操作,输入一个页码,然后点击跳转。 def main(): totle = int(get_totle_page()) # 获取完整页码 for i in range(2,totle+1): print("正在加载第{}页数据".format(i)) # 获取下一页 next_page(i) if __name__ == '__main__': print(main()) 输入页码,点击跳转 def next_page(page_num): try: input = wait.until( EC.presence_of_element_located((By.CSS_SELECTOR,"#pageto")) ) submit = wait.until( EC.element_to_be_clickable((By.CSS_SELECTOR,"#goPage")) ) input.clear() # 清空文本框 input.send_keys(page_num) # 发送页码 submit.click() # 点击跳转 #get_content(page_num) except TimeoutException: next_page(page_num) 以上代码实现的效果动态演示为 4. 石家庄政民互动数据爬取-解析页面 可以进行翻页之后,通过browser.page_source 获取网页源码,网页源码通过lxml进行解析。编写相应的方法为 def get_content(page_num=None): try: wait.until( EC.presence_of_element_located((By.CSS_SELECTOR, "table.tably")) ) html = browser.page_source # 获取网页源码 tree = etree.HTML(html) # 解析 tables = tree.xpath("//table[@class='tably']") for table in tables: name = table.xpath("tbody/tr[1]/td[1]/table/tbody/tr[1]/td")[0].text public_time = table.xpath("tbody/tr[1]/td[1]/table/tbody/tr[2]/td")[0].text to_people = table.xpath("tbody/tr[1]/td[1]/table/tbody/tr[3]/td")[0].text content = table.xpath("tbody/tr[1]/td[2]/table/tbody/tr[1]/td")[0].text repl_time = table.xpath("tbody/tr[2]/td[1]/table/tbody/tr[1]/td")[0].text repl_depart = table.xpath("tbody/tr[2]/td[1]/table/tbody/tr[2]/td")[0].text repl_content = table.xpath("tbody/tr[2]/td[2]/table/tbody/tr[1]/td")[0].text # 清理数据 consult = { "name":name.replace("网友:",""), "public_time":public_time.replace("时间:",""), "to_people":to_people.replace("留言对象:",""), "content":content, "repl_time":repl_time.replace("时间:",""), "repl_depart":repl_depart.replace("回复部门:",""), "repl_content":repl_content } # 数据存储到mongo里面 #save_mongo(consult) except Exception: # 这个地方需要特殊说明一下 print("异常错误X1") print("浏览器休息一下") time.sleep(60) browser.get("http://www.sjz.gov.cn/zfxxinfolist.jsp?current={}&wid=1&cid=1259811582187".format(page_num)) get_content() 在实际的爬取过程中发现,经过几百页之后,就会限制一下IP,所以当我们捕获页面信息出错,需要暂停一下,等待页面正常之后,在继续爬取数据。 5. 石家庄政民互动数据爬取-数据存储到mongodb里面 爬取到的最终数据,我存储到了mongodb里面,这个就没有什么难度了,我们按照常规的套路编写即可。 6. 石家庄政民互动数据爬取-写在最后 由于这次爬取的网站是gov的,所以建议不要用多线程,源码也不发送到github上去了,要不惹祸,如果有任何疑问,请评论。nice boy她专科学历27岁从零开始学习c,c++,python编程语言29岁编写百例教程30岁掌握10种编程语言,用自学的经历告诉你,学编程就找梦想橡皮擦