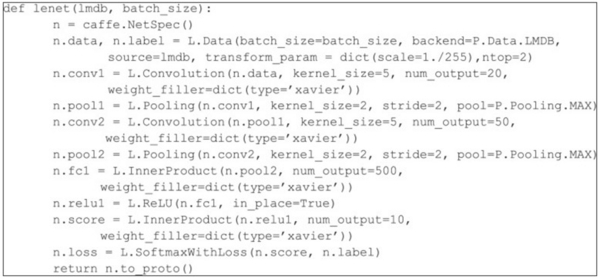
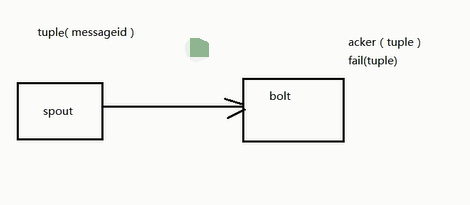
Storm编程入门API系列之Storm的可靠性的ACK消息确认机制
什么业务场景需要storm可靠性的ACK确认机制? 答:想要保住数据不丢,或者保住数据总是被处理。即若没被处理的,得让我们知道。 public void nextTuple() { num++; System.out.println("spout:"+num); int messageid = num; //开启消息确认机制,就是在发送数据的时候发送一个messageid,一般情况下,messageid可以理解为mysql数据里面的主键id字段 //要保证messageid和tuple之间有一个唯一的对应关系,这个关系需要程序员自己维护 this.collector.emit(new Values(num),messageid); Utils.sleep(1000); } 编写代码 StormTopologyAcker.java package zhouls.bigdata.stormDemo; import java.util.Map; import org.apache.storm.Config; import org.apache.storm.LocalCluster; import org.apache.storm.StormSubmitter; import org.apache.storm.generated.AlreadyAliveException; import org.apache.storm.generated.AuthorizationException; import org.apache.storm.generated.InvalidTopologyException; import org.apache.storm.spout.SpoutOutputCollector; import org.apache.storm.task.OutputCollector; import org.apache.storm.task.TopologyContext; import org.apache.storm.topology.OutputFieldsDeclarer; import org.apache.storm.topology.TopologyBuilder; import org.apache.storm.topology.base.BaseRichBolt; import org.apache.storm.topology.base.BaseRichSpout; import org.apache.storm.tuple.Fields; import org.apache.storm.tuple.Tuple; import org.apache.storm.tuple.Values; import org.apache.storm.utils.Utils; public class StormTopologyAcker { public static class MySpout extends BaseRichSpout{ private Map conf; private TopologyContext context; private SpoutOutputCollector collector; public void open(Map conf, TopologyContext context, SpoutOutputCollector collector) { this.conf = conf; this.collector = collector; this.context = context; } int num = 0; public void nextTuple() { num++; System.out.println("spout:"+num); int messageid = num; //开启消息确认机制,就是在发送数据的时候发送一个messageid,一般情况下,messageid可以理解为mysql数据里面的主键id字段 //要保证messageid和tuple之间有一个唯一的对应关系,这个关系需要程序员自己维护 this.collector.emit(new Values(num),messageid); Utils.sleep(1000); } public void declareOutputFields(OutputFieldsDeclarer declarer) { declarer.declare(new Fields("num")); } @Override public void ack(Object msgId) { System.out.println("处理成功!"+msgId); } @Override public void fail(Object msgId) { System.out.println("处理失败!"+msgId); //TODO 可以吧这个数据单独记录下来 } } public static class MyBolt extends BaseRichBolt{ private Map stormConf; private TopologyContext context; private OutputCollector collector; public void prepare(Map stormConf, TopologyContext context, OutputCollector collector) { this.stormConf = stormConf; this.context = context; this.collector = collector; } int sum = 0; public void execute(Tuple input) { try{ Integer num = input.getIntegerByField("num"); sum += num; System.out.println("sum="+sum); this.collector.ack(input); }catch(Exception e){ this.collector.fail(input); } } public void declareOutputFields(OutputFieldsDeclarer declarer) { } } public static void main(String[] args) { TopologyBuilder topologyBuilder = new TopologyBuilder(); String spout_id = MySpout.class.getSimpleName(); String bolt_id = MyBolt.class.getSimpleName(); topologyBuilder.setSpout(spout_id, new MySpout()); topologyBuilder.setBolt(bolt_id, new MyBolt()).shuffleGrouping(spout_id); Config config = new Config(); config.setMaxSpoutPending(1000);//如果设置了这个参数,必须要保证开启了acker机制才有效 String topology_name = StormTopologyAcker.class.getSimpleName(); if(args.length==0){ //在本地运行 LocalCluster localCluster = new LocalCluster(); localCluster.submitTopology(topology_name, config, topologyBuilder.createTopology()); }else{ //在集群运行 try { StormSubmitter.submitTopology(topology_name, config, topologyBuilder.createTopology()); } catch (AlreadyAliveException e) { e.printStackTrace(); } catch (InvalidTopologyException e) { e.printStackTrace(); } catch (AuthorizationException e) { e.printStackTrace(); } } } } 停掉,我们复制粘贴来分析分析 16244 [main] INFO o.a.s.s.o.a.z.s.ZooKeeperServer - Server environment:zookeeper.version=3.4.6-1569965, built on 02/20/2014 09:09 GMT 16246 [main] INFO o.a.s.s.o.a.z.s.ZooKeeperServer - Server environment:host.name=WIN-BQOBV63OBNM 16246 [main] INFO o.a.s.s.o.a.z.s.ZooKeeperServer - Server environment:java.version=1.8.0_66 16246 [main] INFO o.a.s.s.o.a.z.s.ZooKeeperServer - Server environment:java.vendor=Oracle Corporation 16246 [main] INFO o.a.s.s.o.a.z.s.ZooKeeperServer - Server environment:java.home=C:\Program Files\Java\jre1.8.0_66 16246 [main] INFO o.a.s.s.o.a.z.s.ZooKeeperServer - Server environment:java.class.path=D:\Code\eclipseMarsCode\stormDemo\target\classes;D:\SoftWare\maven\repository\org\apache\storm\storm-core\1.0.2\storm-core-1.0.2.jar;D:\SoftWare\maven\repository\com\esotericsoftware\kryo\3.0.3\kryo-3.0.3.jar;D:\SoftWare\maven\repository\com\esotericsoftware\reflectasm\1.10.1\reflectasm-1.10.1.jar;D:\SoftWare\maven\repository\org\ow2\asm\asm\5.0.3\asm-5.0.3.jar;D:\SoftWare\maven\repository\com\esotericsoftware\minlog\1.3.0\minlog-1.3.0.jar;D:\SoftWare\maven\repository\org\objenesis\objenesis\2.1\objenesis-2.1.jar;D:\SoftWare\maven\repository\org\clojure\clojure\1.7.0\clojure-1.7.0.jar;D:\SoftWare\maven\repository\com\lmax\disruptor\3.3.2\disruptor-3.3.2.jar;D:\SoftWare\maven\repository\org\apache\logging\log4j\log4j-api\2.1\log4j-api-2.1.jar;D:\SoftWare\maven\repository\org\apache\logging\log4j\log4j-core\2.1\log4j-core-2.1.jar;D:\SoftWare\maven\repository\org\apache\logging\log4j\log4j-slf4j-impl\2.1\log4j-slf4j-impl-2.1.jar;D:\SoftWare\maven\repository\org\slf4j\log4j-over-slf4j\1.6.6\log4j-over-slf4j-1.6.6.jar;D:\SoftWare\maven\repository\javax\servlet\servlet-api\2.5\servlet-api-2.5.jar;D:\SoftWare\maven\repository\org\slf4j\slf4j-api\1.7.7\slf4j-api-1.7.7.jar 16246 [main] INFO o.a.s.s.o.a.z.s.ZooKeeperServer - Server environment:java.library.path=C:\Program Files\Java\jre1.8.0_66\bin;C:\Windows\Sun\Java\bin;C:\Windows\system32;C:\Windows;C:/Program Files/Java/jre1.8.0_66/bin/server;C:/Program Files/Java/jre1.8.0_66/bin;C:/Program Files/Java/jre1.8.0_66/lib/amd64;%WEKA39_HOME%\lib\mysql-connector-java-5.1.21-bin.jar;%WEKA37_HOME%\lib\mysql-connector-java-5.1.21-bin.jar;C:\Program Files\Java\jdk1.8.0_66\jre\lib\ext\mysql-connector-java-5.1.21-bin.jar;C:\ProgramData\Oracle\Java\javapath;C:\Windows\system32;C:\Windows;C:\Windows\System32\Wbem;C:\Windows\System32\WindowsPowerShell\v1.0\;D:\SoftWare\MATLAB R2013a\runtime\win64;D:\SoftWare\MATLAB R2013a\bin;C:\Program Files (x86)\IDM Computer Solutions\UltraCompare;C:\Program Files\Java\jdk1.8.0_66\bin;C:\Program Files\Java\jdk1.8.0_66\jre\bin;D:\SoftWare\apache-ant-1.9.0\bin;HADOOP_HOME\bin;D:\SoftWare\apache-maven-3.3.9\bin;D:\SoftWare\Scala\bin;D:\SoftWare\Scala\jre\bin;%MYSQL_HOME\bin;D:\SoftWare\MySQL\mysql-5.7.11-winx64;;D:\SoftWare\apache-tomcat-7.0.69\bin;%C:\Windows\System32;%C:\Windows\SysWOW64;;D:\SoftWare\apache-maven-3.3.9\bin;D:\SoftWare\apache-tomcat-7.0.69\bin;D:\SoftWare\apache-tomcat-7.0.69\bin;D:\SoftWare\Anaconda2;D:\SoftWare\Anaconda2\Scripts;D:\SoftWare\Anaconda2\Library\bin;D:\SoftWare\MySQL Server\MySQL Server 5.0\bin;D:\SoftWare\Python\Python36\Scripts\;D:\SoftWare\Python\Python36\;D:\SoftWare\SSH Secure Shell;D:\SoftWare\eclipse;;. 16246 [main] INFO o.a.s.s.o.a.z.s.ZooKeeperServer - Server environment:java.io.tmpdir=C:\Users\ADMINI~1\AppData\Local\Temp\ 16246 [main] INFO o.a.s.s.o.a.z.s.ZooKeeperServer - Server environment:java.compiler=<NA> 16246 [main] INFO o.a.s.s.o.a.z.s.ZooKeeperServer - Server environment:os.name=Windows 7 16246 [main] INFO o.a.s.s.o.a.z.s.ZooKeeperServer - Server environment:os.arch=amd64 16246 [main] INFO o.a.s.s.o.a.z.s.ZooKeeperServer - Server environment:os.version=6.1 16246 [main] INFO o.a.s.s.o.a.z.s.ZooKeeperServer - Server environment:user.name=Administrator 16246 [main] INFO o.a.s.s.o.a.z.s.ZooKeeperServer - Server environment:user.home=C:\Users\Administrator 16247 [main] INFO o.a.s.s.o.a.z.s.ZooKeeperServer - Server environment:user.dir=D:\Code\eclipseMarsCode\stormDemo 16320 [main] INFO o.a.s.s.o.a.z.s.ZooKeeperServer - Created server with tickTime 2000 minSessionTimeout 4000 maxSessionTimeout 40000 datadir C:\Users\ADMINI~1\AppData\Local\Temp\0d2c165c-61e3-45ea-957f-8ecaeea3b694\version-2 snapdir C:\Users\ADMINI~1\AppData\Local\Temp\0d2c165c-61e3-45ea-957f-8ecaeea3b694\version-2 16626 [main] INFO o.a.s.s.o.a.z.s.NIOServerCnxnFactory - binding to port 0.0.0.0/0.0.0.0:2000 16630 [main] INFO o.a.s.s.o.a.z.s.NIOServerCnxnFactory - binding to port 0.0.0.0/0.0.0.0:2001 16637 [main] INFO o.a.s.zookeeper - Starting inprocess zookeeper at port 2001 and dir C:\Users\ADMINI~1\AppData\Local\Temp\0d2c165c-61e3-45ea-957f-8ecaeea3b694 16848 [main] INFO o.a.s.d.nimbus - Starting Nimbus with conf {"topology.builtin.metrics.bucket.size.secs" 60, "nimbus.childopts" "-Xmx1024m", "ui.filter.params" nil, "storm.cluster.mode" "local", "storm.messaging.netty.client_worker_threads" 1, "logviewer.max.per.worker.logs.size.mb" 2048, "supervisor.run.worker.as.user" false, "topology.max.task.parallelism" nil, "topology.priority" 29, "zmq.threads" 1, "storm.group.mapping.service" "org.apache.storm.security.auth.ShellBasedGroupsMapping", "transactional.zookeeper.root" "/transactional", "topology.sleep.spout.wait.strategy.time.ms" 1, "scheduler.display.resource" false, "topology.max.replication.wait.time.sec" 60, "drpc.invocations.port" 3773, "supervisor.localizer.cache.target.size.mb" 10240, "topology.multilang.serializer" "org.apache.storm.multilang.JsonSerializer", "storm.messaging.netty.server_worker_threads" 1, "nimbus.blobstore.class" "org.apache.storm.blobstore.LocalFsBlobStore", "resource.aware.scheduler.eviction.strategy" "org.apache.storm.scheduler.resource.strategies.eviction.DefaultEvictionStrategy", "topology.max.error.report.per.interval" 5, "storm.thrift.transport" "org.apache.storm.security.auth.SimpleTransportPlugin", "zmq.hwm" 0, "storm.group.mapping.service.params" nil, "worker.profiler.enabled" false, "storm.principal.tolocal" "org.apache.storm.security.auth.DefaultPrincipalToLocal", "supervisor.worker.shutdown.sleep.secs" 1, "pacemaker.host" "localhost", "storm.zookeeper.retry.times" 5, "ui.actions.enabled" true, "zmq.linger.millis" 0, "supervisor.enable" true, "topology.stats.sample.rate" 0.05, "storm.messaging.netty.min_wait_ms" 100, "worker.log.level.reset.poll.secs" 30, "storm.zookeeper.port" 2001, "supervisor.heartbeat.frequency.secs" 5, "topology.enable.message.timeouts" true, "supervisor.cpu.capacity" 400.0, "drpc.worker.threads" 64, "supervisor.blobstore.download.thread.count" 5, "drpc.queue.size" 128, "topology.backpressure.enable" false, "supervisor.blobstore.class" "org.apache.storm.blobstore.NimbusBlobStore", "storm.blobstore.inputstream.buffer.size.bytes" 65536, "topology.shellbolt.max.pending" 100, "drpc.https.keystore.password" "", "nimbus.code.sync.freq.secs" 120, "logviewer.port" 8000, "topology.scheduler.strategy" "org.apache.storm.scheduler.resource.strategies.scheduling.DefaultResourceAwareStrategy", "topology.executor.send.buffer.size" 1024, "resource.aware.scheduler.priority.strategy" "org.apache.storm.scheduler.resource.strategies.priority.DefaultSchedulingPriorityStrategy", "pacemaker.auth.method" "NONE", "storm.daemon.metrics.reporter.plugins" ["org.apache.storm.daemon.metrics.reporters.JmxPreparableReporter"], "topology.worker.logwriter.childopts" "-Xmx64m", "topology.spout.wait.strategy" "org.apache.storm.spout.SleepSpoutWaitStrategy", "ui.host" "0.0.0.0", "storm.nimbus.retry.interval.millis" 2000, "nimbus.inbox.jar.expiration.secs" 3600, "dev.zookeeper.path" "/tmp/dev-storm-zookeeper", "topology.acker.executors" nil, "topology.fall.back.on.java.serialization" true, "topology.eventlogger.executors" 0, "supervisor.localizer.cleanup.interval.ms" 600000, "storm.zookeeper.servers" ["localhost"], "nimbus.thrift.threads" 64, "logviewer.cleanup.age.mins" 10080, "topology.worker.childopts" nil, "topology.classpath" nil, "supervisor.monitor.frequency.secs" 3, "nimbus.credential.renewers.freq.secs" 600, "topology.skip.missing.kryo.registrations" true, "drpc.authorizer.acl.filename" "drpc-auth-acl.yaml", "pacemaker.kerberos.users" [], "storm.group.mapping.service.cache.duration.secs" 120, "topology.testing.always.try.serialize" false, "nimbus.monitor.freq.secs" 10, "storm.health.check.timeout.ms" 5000, "supervisor.supervisors" [], "topology.tasks" nil, "topology.bolts.outgoing.overflow.buffer.enable" false, "storm.messaging.netty.socket.backlog" 500, "topology.workers" 1, "pacemaker.base.threads" 10, "storm.local.dir" "C:\\Users\\ADMINI~1\\AppData\\Local\\Temp\\d7cdc68c-f54c-4677-ac0e-d73c3b2effb3", "topology.disable.loadaware" false, "worker.childopts" "-Xmx%HEAP-MEM%m -XX:+PrintGCDetails -Xloggc:artifacts/gc.log -XX:+PrintGCDateStamps -XX:+PrintGCTimeStamps -XX:+UseGCLogFileRotation -XX:NumberOfGCLogFiles=10 -XX:GCLogFileSize=1M -XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=artifacts/heapdump", "storm.auth.simple-white-list.users" [], "topology.disruptor.batch.timeout.millis" 1, "topology.message.timeout.secs" 30, "topology.state.synchronization.timeout.secs" 60, "topology.tuple.serializer" "org.apache.storm.serialization.types.ListDelegateSerializer", "supervisor.supervisors.commands" [], "nimbus.blobstore.expiration.secs" 600, "logviewer.childopts" "-Xmx128m", "topology.environment" nil, "topology.debug" false, "topology.disruptor.batch.size" 100, "storm.messaging.netty.max_retries" 300, "ui.childopts" "-Xmx768m", "storm.network.topography.plugin" "org.apache.storm.networktopography.DefaultRackDNSToSwitchMapping", "storm.zookeeper.session.timeout" 20000, "drpc.childopts" "-Xmx768m", "drpc.http.creds.plugin" "org.apache.storm.security.auth.DefaultHttpCredentialsPlugin", "storm.zookeeper.connection.timeout" 15000, "storm.zookeeper.auth.user" nil, "storm.meta.serialization.delegate" "org.apache.storm.serialization.GzipThriftSerializationDelegate", "topology.max.spout.pending" nil, "storm.codedistributor.class" "org.apache.storm.codedistributor.LocalFileSystemCodeDistributor", "nimbus.supervisor.timeout.secs" 60, "nimbus.task.timeout.secs" 30, "drpc.port" 3772, "pacemaker.max.threads" 50, "storm.zookeeper.retry.intervalceiling.millis" 30000, "nimbus.thrift.port" 6627, "storm.auth.simple-acl.admins" [], "topology.component.cpu.pcore.percent" 10.0, "supervisor.memory.capacity.mb" 3072.0, "storm.nimbus.retry.times" 5, "supervisor.worker.start.timeout.secs" 120, "storm.zookeeper.retry.interval" 1000, "logs.users" nil, "worker.profiler.command" "flight.bash", "transactional.zookeeper.port" nil, "drpc.max_buffer_size" 1048576, "pacemaker.thread.timeout" 10, "task.credentials.poll.secs" 30, "blobstore.superuser" "Administrator", "drpc.https.keystore.type" "JKS", "topology.worker.receiver.thread.count" 1, "topology.state.checkpoint.interval.ms" 1000, "supervisor.slots.ports" [6700 6701 6702 6703], "topology.transfer.buffer.size" 1024, "storm.health.check.dir" "healthchecks", "topology.worker.shared.thread.pool.size" 4, "drpc.authorizer.acl.strict" false, "nimbus.file.copy.expiration.secs" 600, "worker.profiler.childopts" "-XX:+UnlockCommercialFeatures -XX:+FlightRecorder", "topology.executor.receive.buffer.size" 1024, "backpressure.disruptor.low.watermark" 0.4, "nimbus.task.launch.secs" 120, "storm.local.mode.zmq" false, "storm.messaging.netty.buffer_size" 5242880, "storm.cluster.state.store" "org.apache.storm.cluster_state.zookeeper_state_factory", "worker.heartbeat.frequency.secs" 1, "storm.log4j2.conf.dir" "log4j2", "ui.http.creds.plugin" "org.apache.storm.security.auth.DefaultHttpCredentialsPlugin", "storm.zookeeper.root" "/storm", "topology.tick.tuple.freq.secs" nil, "drpc.https.port" -1, "storm.workers.artifacts.dir" "workers-artifacts", "supervisor.blobstore.download.max_retries" 3, "task.refresh.poll.secs" 10, "storm.exhibitor.port" 8080, "task.heartbeat.frequency.secs" 3, "pacemaker.port" 6699, "storm.messaging.netty.max_wait_ms" 1000, "topology.component.resources.offheap.memory.mb" 0.0, "drpc.http.port" 3774, "topology.error.throttle.interval.secs" 10, "storm.messaging.transport" "org.apache.storm.messaging.netty.Context", "storm.messaging.netty.authentication" false, "topology.component.resources.onheap.memory.mb" 128.0, "topology.kryo.factory" "org.apache.storm.serialization.DefaultKryoFactory", "worker.gc.childopts" "", "nimbus.topology.validator" "org.apache.storm.nimbus.DefaultTopologyValidator", "nimbus.seeds" ["localhost"], "nimbus.queue.size" 100000, "nimbus.cleanup.inbox.freq.secs" 600, "storm.blobstore.replication.factor" 3, "worker.heap.memory.mb" 768, "logviewer.max.sum.worker.logs.size.mb" 4096, "pacemaker.childopts" "-Xmx1024m", "ui.users" nil, "transactional.zookeeper.servers" nil, "supervisor.worker.timeout.secs" 30, "storm.zookeeper.auth.password" nil, "storm.blobstore.acl.validation.enabled" false, "client.blobstore.class" "org.apache.storm.blobstore.NimbusBlobStore", "supervisor.childopts" "-Xmx256m", "topology.worker.max.heap.size.mb" 768.0, "ui.http.x-frame-options" "DENY", "backpressure.disruptor.high.watermark" 0.9, "ui.filter" nil, "ui.header.buffer.bytes" 4096, "topology.min.replication.count" 1, "topology.disruptor.wait.timeout.millis" 1000, "storm.nimbus.retry.intervalceiling.millis" 60000, "topology.trident.batch.emit.interval.millis" 50, "storm.auth.simple-acl.users" [], "drpc.invocations.threads" 64, "java.library.path" "/usr/local/lib:/opt/local/lib:/usr/lib", "ui.port" 8080, "storm.exhibitor.poll.uripath" "/exhibitor/v1/cluster/list", "storm.messaging.netty.transfer.batch.size" 262144, "logviewer.appender.name" "A1", "nimbus.thrift.max_buffer_size" 1048576, "storm.auth.simple-acl.users.commands" [], "drpc.request.timeout.secs" 600} 17556 [main] INFO o.a.s.s.o.a.c.f.i.CuratorFrameworkImpl - Starting 17612 [main] INFO o.a.s.s.o.a.z.ZooKeeper - Client environment:zookeeper.version=3.4.6-1569965, built on 02/20/2014 09:09 GMT 17613 [main] INFO o.a.s.s.o.a.z.ZooKeeper - Client environment:host.name=WIN-BQOBV63OBNM 17613 [main] INFO o.a.s.s.o.a.z.ZooKeeper - Client environment:java.version=1.8.0_66 17613 [main] INFO o.a.s.s.o.a.z.ZooKeeper - Client environment:java.vendor=Oracle Corporation 17613 [main] INFO o.a.s.s.o.a.z.ZooKeeper - Client environment:java.home=C:\Program Files\Java\jre1.8.0_66 17614 [main] INFO o.a.s.s.o.a.z.ZooKeeper - Client environment:java.class.path=D:\Code\eclipseMarsCode\stormDemo\target\classes;D:\SoftWare\maven\repository\org\apache\storm\storm-core\1.0.2\storm-core-1.0.2.jar;D:\SoftWare\maven\repository\com\esotericsoftware\kryo\3.0.3\kryo-3.0.3.jar;D:\SoftWare\maven\repository\com\esotericsoftware\reflectasm\1.10.1\reflectasm-1.10.1.jar;D:\SoftWare\maven\repository\org\ow2\asm\asm\5.0.3\asm-5.0.3.jar;D:\SoftWare\maven\repository\com\esotericsoftware\minlog\1.3.0\minlog-1.3.0.jar;D:\SoftWare\maven\repository\org\objenesis\objenesis\2.1\objenesis-2.1.jar;D:\SoftWare\maven\repository\org\clojure\clojure\1.7.0\clojure-1.7.0.jar;D:\SoftWare\maven\repository\com\lmax\disruptor\3.3.2\disruptor-3.3.2.jar;D:\SoftWare\maven\repository\org\apache\logging\log4j\log4j-api\2.1\log4j-api-2.1.jar;D:\SoftWare\maven\repository\org\apache\logging\log4j\log4j-core\2.1\log4j-core-2.1.jar;D:\SoftWare\maven\repository\org\apache\logging\log4j\log4j-slf4j-impl\2.1\log4j-slf4j-impl-2.1.jar;D:\SoftWare\maven\repository\org\slf4j\log4j-over-slf4j\1.6.6\log4j-over-slf4j-1.6.6.jar;D:\SoftWare\maven\repository\javax\servlet\servlet-api\2.5\servlet-api-2.5.jar;D:\SoftWare\maven\repository\org\slf4j\slf4j-api\1.7.7\slf4j-api-1.7.7.jar 17614 [main] INFO o.a.s.s.o.a.z.ZooKeeper - Client environment:java.library.path=C:\Program Files\Java\jre1.8.0_66\bin;C:\Windows\Sun\Java\bin;C:\Windows\system32;C:\Windows;C:/Program Files/Java/jre1.8.0_66/bin/server;C:/Program Files/Java/jre1.8.0_66/bin;C:/Program Files/Java/jre1.8.0_66/lib/amd64;%WEKA39_HOME%\lib\mysql-connector-java-5.1.21-bin.jar;%WEKA37_HOME%\lib\mysql-connector-java-5.1.21-bin.jar;C:\Program Files\Java\jdk1.8.0_66\jre\lib\ext\mysql-connector-java-5.1.21-bin.jar;C:\ProgramData\Oracle\Java\javapath;C:\Windows\system32;C:\Windows;C:\Windows\System32\Wbem;C:\Windows\System32\WindowsPowerShell\v1.0\;D:\SoftWare\MATLAB R2013a\runtime\win64;D:\SoftWare\MATLAB R2013a\bin;C:\Program Files (x86)\IDM Computer Solutions\UltraCompare;C:\Program Files\Java\jdk1.8.0_66\bin;C:\Program Files\Java\jdk1.8.0_66\jre\bin;D:\SoftWare\apache-ant-1.9.0\bin;HADOOP_HOME\bin;D:\SoftWare\apache-maven-3.3.9\bin;D:\SoftWare\Scala\bin;D:\SoftWare\Scala\jre\bin;%MYSQL_HOME\bin;D:\SoftWare\MySQL\mysql-5.7.11-winx64;;D:\SoftWare\apache-tomcat-7.0.69\bin;%C:\Windows\System32;%C:\Windows\SysWOW64;;D:\SoftWare\apache-maven-3.3.9\bin;D:\SoftWare\apache-tomcat-7.0.69\bin;D:\SoftWare\apache-tomcat-7.0.69\bin;D:\SoftWare\Anaconda2;D:\SoftWare\Anaconda2\Scripts;D:\SoftWare\Anaconda2\Library\bin;D:\SoftWare\MySQL Server\MySQL Server 5.0\bin;D:\SoftWare\Python\Python36\Scripts\;D:\SoftWare\Python\Python36\;D:\SoftWare\SSH Secure Shell;D:\SoftWare\eclipse;;. 17614 [main] INFO o.a.s.s.o.a.z.ZooKeeper - Client environment:java.io.tmpdir=C:\Users\ADMINI~1\AppData\Local\Temp\ 17614 [main] INFO o.a.s.s.o.a.z.ZooKeeper - Client environment:java.compiler=<NA> 17614 [main] INFO o.a.s.s.o.a.z.ZooKeeper - Client environment:os.name=Windows 7 17614 [main] INFO o.a.s.s.o.a.z.ZooKeeper - Client environment:os.arch=amd64 17615 [main] INFO o.a.s.s.o.a.z.ZooKeeper - Client environment:os.version=6.1 17615 [main] INFO o.a.s.s.o.a.z.ZooKeeper - Client environment:user.name=Administrator 17615 [main] INFO o.a.s.s.o.a.z.ZooKeeper - Client environment:user.home=C:\Users\Administrator 17615 [main] INFO o.a.s.s.o.a.z.ZooKeeper - Client environment:user.dir=D:\Code\eclipseMarsCode\stormDemo 17620 [main] INFO o.a.s.s.o.a.z.ZooKeeper - Initiating client connection, connectString=localhost:2001/storm sessionTimeout=20000 watcher=org.apache.storm.shade.org.apache.curator.ConnectionState@6824b913 17786 [main-SendThread(127.0.0.1:2001)] INFO o.a.s.s.o.a.z.ClientCnxn - Opening socket connection to server 127.0.0.1/127.0.0.1:2001. Will not attempt to authenticate using SASL (unknown error) 17796 [NIOServerCxn.Factory:0.0.0.0/0.0.0.0:2001] INFO o.a.s.s.o.a.z.s.NIOServerCnxnFactory - Accepted socket connection from /127.0.0.1:60042 17801 [main-SendThread(127.0.0.1:2001)] INFO o.a.s.s.o.a.z.ClientCnxn - Socket connection established to 127.0.0.1/127.0.0.1:2001, initiating session 17915 [NIOServerCxn.Factory:0.0.0.0/0.0.0.0:2001] INFO o.a.s.s.o.a.z.s.ZooKeeperServer - Client attempting to establish new session at /127.0.0.1:60042 17938 [SyncThread:0] INFO o.a.s.s.o.a.z.s.p.FileTxnLog - Creating new log file: log.1 17963 [main] INFO o.a.s.b.FileBlobStoreImpl - Creating new blob store based in C:\Users\ADMINI~1\AppData\Local\Temp\d7cdc68c-f54c-4677-ac0e-d73c3b2effb3\blobs 18047 [main] INFO o.a.s.d.nimbus - Using default scheduler 18138 [main] INFO o.a.s.s.o.a.c.f.i.CuratorFrameworkImpl - Starting 18140 [SyncThread:0] INFO o.a.s.s.o.a.z.s.ZooKeeperServer - Established session 0x15d87b848820000 with negotiated timeout 20000 for client /127.0.0.1:60042 18141 [main-SendThread(127.0.0.1:2001)] INFO o.a.s.s.o.a.z.ClientCnxn - Session establishment complete on server 127.0.0.1/127.0.0.1:2001, sessionid = 0x15d87b848820000, negotiated timeout = 20000 18187 [main] INFO o.a.s.s.o.a.z.ZooKeeper - Initiating client connection, connectString=localhost:2001 sessionTimeout=20000 watcher=org.apache.storm.shade.org.apache.curator.ConnectionState@21a9a705 18279 [main-SendThread(127.0.0.1:2001)] INFO o.a.s.s.o.a.z.ClientCnxn - Opening socket connection to server 127.0.0.1/127.0.0.1:2001. Will not attempt to authenticate using SASL (unknown error) 18282 [NIOServerCxn.Factory:0.0.0.0/0.0.0.0:2001] INFO o.a.s.s.o.a.z.s.NIOServerCnxnFactory - Accepted socket connection from /127.0.0.1:60045 18282 [main-SendThread(127.0.0.1:2001)] INFO o.a.s.s.o.a.z.ClientCnxn - Socket connection established to 127.0.0.1/127.0.0.1:2001, initiating session 18283 [NIOServerCxn.Factory:0.0.0.0/0.0.0.0:2001] INFO o.a.s.s.o.a.z.s.ZooKeeperServer - Client attempting to establish new session at /127.0.0.1:60045 18327 [main-EventThread] INFO o.a.s.s.o.a.c.f.s.ConnectionStateManager - State change: CONNECTED 18388 [SyncThread:0] INFO o.a.s.s.o.a.z.s.ZooKeeperServer - Established session 0x15d87b848820001 with negotiated timeout 20000 for client /127.0.0.1:60045 18389 [main-SendThread(127.0.0.1:2001)] INFO o.a.s.s.o.a.z.ClientCnxn - Session establishment complete on server 127.0.0.1/127.0.0.1:2001, sessionid = 0x15d87b848820001, negotiated timeout = 20000 18393 [main-EventThread] INFO o.a.s.s.o.a.c.f.s.ConnectionStateManager - State change: CONNECTED 18395 [main-EventThread] INFO o.a.s.zookeeper - Zookeeper state update: :connected:none 18459 [main] INFO o.a.s.s.o.a.c.f.i.CuratorFrameworkImpl - Starting 18460 [main] INFO o.a.s.s.o.a.z.ZooKeeper - Initiating client connection, connectString=localhost:2001 sessionTimeout=20000 watcher=org.apache.storm.shade.org.apache.curator.ConnectionState@753fd7a1 18536 [main-SendThread(127.0.0.1:2001)] INFO o.a.s.s.o.a.z.ClientCnxn - Opening socket connection to server 127.0.0.1/127.0.0.1:2001. Will not attempt to authenticate using SASL (unknown error) 18538 [NIOServerCxn.Factory:0.0.0.0/0.0.0.0:2001] INFO o.a.s.s.o.a.z.s.NIOServerCnxnFactory - Accepted socket connection from /127.0.0.1:60048 18538 [main-SendThread(127.0.0.1:2001)] INFO o.a.s.s.o.a.z.ClientCnxn - Socket connection established to 127.0.0.1/127.0.0.1:2001, initiating session 18540 [NIOServerCxn.Factory:0.0.0.0/0.0.0.0:2001] INFO o.a.s.s.o.a.z.s.ZooKeeperServer - Client attempting to establish new session at /127.0.0.1:60048 18653 [SyncThread:0] INFO o.a.s.s.o.a.z.s.ZooKeeperServer - Established session 0x15d87b848820002 with negotiated timeout 20000 for client /127.0.0.1:60048 18653 [main-SendThread(127.0.0.1:2001)] INFO o.a.s.s.o.a.z.ClientCnxn - Session establishment complete on server 127.0.0.1/127.0.0.1:2001, sessionid = 0x15d87b848820002, negotiated timeout = 20000 18654 [main-EventThread] INFO o.a.s.s.o.a.c.f.s.ConnectionStateManager - State change: CONNECTED 18655 [main-EventThread] INFO o.a.s.zookeeper - Zookeeper state update: :connected:none 19007 [Curator-Framework-0] INFO o.a.s.s.o.a.c.f.i.CuratorFrameworkImpl - backgroundOperationsLoop exiting 19035 [ProcessThread(sid:0 cport:-1):] INFO o.a.s.s.o.a.z.s.PrepRequestProcessor - Processed session termination for sessionid: 0x15d87b848820002 19078 [main] INFO o.a.s.s.o.a.z.ZooKeeper - Session: 0x15d87b848820002 closed 19078 [main-EventThread] INFO o.a.s.s.o.a.z.ClientCnxn - EventThread shut down 19082 [NIOServerCxn.Factory:0.0.0.0/0.0.0.0:2001] INFO o.a.s.s.o.a.z.s.NIOServerCnxn - Closed socket connection for client /127.0.0.1:60048 which had sessionid 0x15d87b848820002 19084 [main] INFO o.a.s.s.o.a.c.f.i.CuratorFrameworkImpl - Starting 19085 [main] INFO o.a.s.s.o.a.z.ZooKeeper - Initiating client connection, connectString=localhost:2001/storm sessionTimeout=20000 watcher=org.apache.storm.shade.org.apache.curator.ConnectionState@70025b99 19091 [main-SendThread(127.0.0.1:2001)] INFO o.a.s.s.o.a.z.ClientCnxn - Opening socket connection to server 127.0.0.1/127.0.0.1:2001. Will not attempt to authenticate using SASL (unknown error) 19092 [main-SendThread(127.0.0.1:2001)] INFO o.a.s.s.o.a.z.ClientCnxn - Socket connection established to 127.0.0.1/127.0.0.1:2001, initiating session 19093 [NIOServerCxn.Factory:0.0.0.0/0.0.0.0:2001] INFO o.a.s.s.o.a.z.s.NIOServerCnxnFactory - Accepted socket connection from /127.0.0.1:60051 19093 [NIOServerCxn.Factory:0.0.0.0/0.0.0.0:2001] INFO o.a.s.s.o.a.z.s.ZooKeeperServer - Client attempting to establish new session at /127.0.0.1:60051 19095 [main] INFO o.a.s.s.o.a.c.f.i.CuratorFrameworkImpl - Starting 19096 [main] INFO o.a.s.s.o.a.z.ZooKeeper - Initiating client connection, connectString=localhost:2001/storm sessionTimeout=20000 watcher=org.apache.storm.shade.org.apache.curator.ConnectionState@3ba3d4b6 19103 [main-SendThread(127.0.0.1:2001)] INFO o.a.s.s.o.a.z.ClientCnxn - Opening socket connection to server 127.0.0.1/127.0.0.1:2001. Will not attempt to authenticate using SASL (unknown error) 19105 [main-SendThread(127.0.0.1:2001)] INFO o.a.s.s.o.a.z.ClientCnxn - Socket connection established to 127.0.0.1/127.0.0.1:2001, initiating session 19105 [NIOServerCxn.Factory:0.0.0.0/0.0.0.0:2001] INFO o.a.s.s.o.a.z.s.NIOServerCnxnFactory - Accepted socket connection from /127.0.0.1:60054 19106 [NIOServerCxn.Factory:0.0.0.0/0.0.0.0:2001] INFO o.a.s.s.o.a.z.s.ZooKeeperServer - Client attempting to establish new session at /127.0.0.1:60054 19108 [SyncThread:0] INFO o.a.s.s.o.a.z.s.ZooKeeperServer - Established session 0x15d87b848820003 with negotiated timeout 20000 for client /127.0.0.1:60051 19111 [main-SendThread(127.0.0.1:2001)] INFO o.a.s.s.o.a.z.ClientCnxn - Session establishment complete on server 127.0.0.1/127.0.0.1:2001, sessionid = 0x15d87b848820003, negotiated timeout = 20000 19112 [main-EventThread] INFO o.a.s.s.o.a.c.f.s.ConnectionStateManager - State change: CONNECTED 19180 [SyncThread:0] INFO o.a.s.s.o.a.z.s.ZooKeeperServer - Established session 0x15d87b848820004 with negotiated timeout 20000 for client /127.0.0.1:60054 19180 [main-SendThread(127.0.0.1:2001)] INFO o.a.s.s.o.a.z.ClientCnxn - Session establishment complete on server 127.0.0.1/127.0.0.1:2001, sessionid = 0x15d87b848820004, negotiated timeout = 20000 19182 [main-EventThread] INFO o.a.s.s.o.a.c.f.s.ConnectionStateManager - State change: CONNECTED 19990 [main] INFO o.a.s.zookeeper - Queued up for leader lock. 20060 [ProcessThread(sid:0 cport:-1):] INFO o.a.s.s.o.a.z.s.PrepRequestProcessor - Got user-level KeeperException when processing sessionid:0x15d87b848820001 type:create cxid:0x1 zxid:0x12 txntype:-1 reqpath:n/a Error Path:/storm/leader-lock Error:KeeperErrorCode = NoNode for /storm/leader-lock 20249 [Curator-Framework-0] WARN o.a.s.s.o.a.c.u.ZKPaths - The version of ZooKeeper being used doesn't support Container nodes. CreateMode.PERSISTENT will be used instead. 20504 [main] INFO o.a.s.d.m.MetricsUtils - Using statistics reporter plugin:org.apache.storm.daemon.metrics.reporters.JmxPreparableReporter 20508 [main] INFO o.a.s.d.m.r.JmxPreparableReporter - Preparing... 20616 [main-EventThread] INFO o.a.s.zookeeper - WIN-BQOBV63OBNM gained leadership, checking if it has all the topology code locally. 20621 [main] INFO o.a.s.d.common - Started statistics report plugin... 20693 [main] INFO o.a.s.s.o.a.c.f.i.CuratorFrameworkImpl - Starting 20695 [main] INFO o.a.s.s.o.a.z.ZooKeeper - Initiating client connection, connectString=localhost:2001 sessionTimeout=20000 watcher=org.apache.storm.shade.org.apache.curator.ConnectionState@1b9d9a2b 20760 [main-EventThread] INFO o.a.s.zookeeper - active-topology-ids [] local-topology-ids [] diff-topology [] 20760 [main-EventThread] INFO o.a.s.zookeeper - Accepting leadership, all active topology found localy. 20769 [main-SendThread(127.0.0.1:2001)] INFO o.a.s.s.o.a.z.ClientCnxn - Opening socket connection to server 127.0.0.1/127.0.0.1:2001. Will not attempt to authenticate using SASL (unknown error) 20771 [main-SendThread(127.0.0.1:2001)] INFO o.a.s.s.o.a.z.ClientCnxn - Socket connection established to 127.0.0.1/127.0.0.1:2001, initiating session 20771 [NIOServerCxn.Factory:0.0.0.0/0.0.0.0:2001] INFO o.a.s.s.o.a.z.s.NIOServerCnxnFactory - Accepted socket connection from /127.0.0.1:60057 20773 [NIOServerCxn.Factory:0.0.0.0/0.0.0.0:2001] INFO o.a.s.s.o.a.z.s.ZooKeeperServer - Client attempting to establish new session at /127.0.0.1:60057 20857 [SyncThread:0] INFO o.a.s.s.o.a.z.s.ZooKeeperServer - Established session 0x15d87b848820005 with negotiated timeout 20000 for client /127.0.0.1:60057 20858 [main-SendThread(127.0.0.1:2001)] INFO o.a.s.s.o.a.z.ClientCnxn - Session establishment complete on server 127.0.0.1/127.0.0.1:2001, sessionid = 0x15d87b848820005, negotiated timeout = 20000 20858 [main-EventThread] INFO o.a.s.s.o.a.c.f.s.ConnectionStateManager - State change: CONNECTED 20859 [main-EventThread] INFO o.a.s.zookeeper - Zookeeper state update: :connected:none 20867 [Curator-Framework-0] INFO o.a.s.s.o.a.c.f.i.CuratorFrameworkImpl - backgroundOperationsLoop exiting 20870 [ProcessThread(sid:0 cport:-1):] INFO o.a.s.s.o.a.z.s.PrepRequestProcessor - Processed session termination for sessionid: 0x15d87b848820005 20903 [NIOServerCxn.Factory:0.0.0.0/0.0.0.0:2001] INFO o.a.s.s.o.a.z.s.NIOServerCnxn - Closed socket connection for client /127.0.0.1:60057 which had sessionid 0x15d87b848820005 20907 [main] INFO o.a.s.s.o.a.z.ZooKeeper - Session: 0x15d87b848820005 closed 20909 [main] INFO o.a.s.s.o.a.c.f.i.CuratorFrameworkImpl - Starting 20911 [main] INFO o.a.s.s.o.a.z.ZooKeeper - Initiating client connection, connectString=localhost:2001/storm sessionTimeout=20000 watcher=org.apache.storm.shade.org.apache.curator.ConnectionState@7c281eb8 20921 [main-EventThread] INFO o.a.s.s.o.a.z.ClientCnxn - EventThread shut down 20934 [main] INFO o.a.s.s.o.a.c.f.i.CuratorFrameworkImpl - Starting 20941 [main] INFO o.a.s.s.o.a.z.ZooKeeper - Initiating client connection, connectString=localhost:2001 sessionTimeout=20000 watcher=org.apache.storm.shade.org.apache.curator.ConnectionState@4a8ffd75 20994 [main-SendThread(127.0.0.1:2001)] INFO o.a.s.s.o.a.z.ClientCnxn - Opening socket connection to server 127.0.0.1/127.0.0.1:2001. Will not attempt to authenticate using SASL (unknown error) 20995 [main-SendThread(127.0.0.1:2001)] INFO o.a.s.s.o.a.z.ClientCnxn - Socket connection established to 127.0.0.1/127.0.0.1:2001, initiating session 20995 [NIOServerCxn.Factory:0.0.0.0/0.0.0.0:2001] INFO o.a.s.s.o.a.z.s.NIOServerCnxnFactory - Accepted socket connection from /127.0.0.1:60062 20996 [NIOServerCxn.Factory:0.0.0.0/0.0.0.0:2001] INFO o.a.s.s.o.a.z.s.ZooKeeperServer - Client attempting to establish new session at /127.0.0.1:60062 20998 [main-SendThread(127.0.0.1:2001)] INFO o.a.s.s.o.a.z.ClientCnxn - Opening socket connection to server 127.0.0.1/127.0.0.1:2001. Will not attempt to authenticate using SASL (unknown error) 21002 [NIOServerCxn.Factory:0.0.0.0/0.0.0.0:2001] INFO o.a.s.s.o.a.z.s.NIOServerCnxnFactory - Accepted socket connection from /127.0.0.1:60063 21003 [main-SendThread(127.0.0.1:2001)] INFO o.a.s.s.o.a.z.ClientCnxn - Socket connection established to 127.0.0.1/127.0.0.1:2001, initiating session 21005 [NIOServerCxn.Factory:0.0.0.0/0.0.0.0:2001] INFO o.a.s.s.o.a.z.s.ZooKeeperServer - Client attempting to establish new session at /127.0.0.1:60063 21065 [main-SendThread(127.0.0.1:2001)] INFO o.a.s.s.o.a.z.ClientCnxn - Session establishment complete on server 127.0.0.1/127.0.0.1:2001, sessionid = 0x15d87b848820006, negotiated timeout = 20000 21065 [SyncThread:0] INFO o.a.s.s.o.a.z.s.ZooKeeperServer - Established session 0x15d87b848820006 with negotiated timeout 20000 for client /127.0.0.1:60062 21070 [main-EventThread] INFO o.a.s.s.o.a.c.f.s.ConnectionStateManager - State change: CONNECTED 21086 [main-SendThread(127.0.0.1:2001)] INFO o.a.s.s.o.a.z.ClientCnxn - Session establishment complete on server 127.0.0.1/127.0.0.1:2001, sessionid = 0x15d87b848820007, negotiated timeout = 20000 21087 [SyncThread:0] INFO o.a.s.s.o.a.z.s.ZooKeeperServer - Established session 0x15d87b848820007 with negotiated timeout 20000 for client /127.0.0.1:60063 21089 [main-EventThread] INFO o.a.s.s.o.a.c.f.s.ConnectionStateManager - State change: CONNECTED 21089 [main-EventThread] INFO o.a.s.zookeeper - Zookeeper state update: :connected:none 21100 [Curator-Framework-0] INFO o.a.s.s.o.a.c.f.i.CuratorFrameworkImpl - backgroundOperationsLoop exiting 21107 [ProcessThread(sid:0 cport:-1):] INFO o.a.s.s.o.a.z.s.PrepRequestProcessor - Processed session termination for sessionid: 0x15d87b848820007 21131 [Curator-ConnectionStateManager-0] WARN o.a.s.s.o.a.c.f.s.ConnectionStateManager - There are no ConnectionStateListeners registered. 21151 [main] INFO o.a.s.s.o.a.z.ZooKeeper - Session: 0x15d87b848820007 closed 21154 [main] INFO o.a.s.s.o.a.c.f.i.CuratorFrameworkImpl - Starting 21158 [main] INFO o.a.s.s.o.a.z.ZooKeeper - Initiating client connection, connectString=localhost:2001/storm sessionTimeout=20000 watcher=org.apache.storm.shade.org.apache.curator.ConnectionState@3e05586b 21153 [NIOServerCxn.Factory:0.0.0.0/0.0.0.0:2001] WARN o.a.s.s.o.a.z.s.NIOServerCnxn - caught end of stream exception org.apache.storm.shade.org.apache.zookeeper.server.ServerCnxn$EndOfStreamException: Unable to read additional data from client sessionid 0x15d87b848820007, likely client has closed socket at org.apache.storm.shade.org.apache.zookeeper.server.NIOServerCnxn.doIO(NIOServerCnxn.java:228) [storm-core-1.0.2.jar:1.0.2] at org.apache.storm.shade.org.apache.zookeeper.server.NIOServerCnxnFactory.run(NIOServerCnxnFactory.java:208) [storm-core-1.0.2.jar:1.0.2] at java.lang.Thread.run(Unknown Source) [?:1.8.0_66] 21180 [NIOServerCxn.Factory:0.0.0.0/0.0.0.0:2001] INFO o.a.s.s.o.a.z.s.NIOServerCnxn - Closed socket connection for client /127.0.0.1:60063 which had sessionid 0x15d87b848820007 21184 [main-EventThread] INFO o.a.s.s.o.a.z.ClientCnxn - EventThread shut down 21203 [main-SendThread(127.0.0.1:2001)] INFO o.a.s.s.o.a.z.ClientCnxn - Opening socket connection to server 127.0.0.1/127.0.0.1:2001. Will not attempt to authenticate using SASL (unknown error) 21205 [main-SendThread(127.0.0.1:2001)] INFO o.a.s.s.o.a.z.ClientCnxn - Socket connection established to 127.0.0.1/127.0.0.1:2001, initiating session 21205 [NIOServerCxn.Factory:0.0.0.0/0.0.0.0:2001] INFO o.a.s.s.o.a.z.s.NIOServerCnxnFactory - Accepted socket connection from /127.0.0.1:60066 21206 [NIOServerCxn.Factory:0.0.0.0/0.0.0.0:2001] INFO o.a.s.s.o.a.z.s.ZooKeeperServer - Client attempting to establish new session at /127.0.0.1:60066 21261 [main-SendThread(127.0.0.1:2001)] INFO o.a.s.s.o.a.z.ClientCnxn - Session establishment complete on server 127.0.0.1/127.0.0.1:2001, sessionid = 0x15d87b848820008, negotiated timeout = 20000 21261 [SyncThread:0] INFO o.a.s.s.o.a.z.s.ZooKeeperServer - Established session 0x15d87b848820008 with negotiated timeout 20000 for client /127.0.0.1:60066 21272 [main-EventThread] INFO o.a.s.s.o.a.c.f.s.ConnectionStateManager - State change: CONNECTED 21408 [main] INFO o.a.s.d.supervisor - Starting Supervisor with conf {"topology.builtin.metrics.bucket.size.secs" 60, "nimbus.childopts" "-Xmx1024m", "ui.filter.params" nil, "storm.cluster.mode" "local", "storm.messaging.netty.client_worker_threads" 1, "logviewer.max.per.worker.logs.size.mb" 2048, "supervisor.run.worker.as.user" false, "topology.max.task.parallelism" nil, "topology.priority" 29, "zmq.threads" 1, "storm.group.mapping.service" "org.apache.storm.security.auth.ShellBasedGroupsMapping", "transactional.zookeeper.root" "/transactional", "topology.sleep.spout.wait.strategy.time.ms" 1, "scheduler.display.resource" false, "topology.max.replication.wait.time.sec" 60, "drpc.invocations.port" 3773, "supervisor.localizer.cache.target.size.mb" 10240, "topology.multilang.serializer" "org.apache.storm.multilang.JsonSerializer", "storm.messaging.netty.server_worker_threads" 1, "nimbus.blobstore.class" "org.apache.storm.blobstore.LocalFsBlobStore", "resource.aware.scheduler.eviction.strategy" "org.apache.storm.scheduler.resource.strategies.eviction.DefaultEvictionStrategy", "topology.max.error.report.per.interval" 5, "storm.thrift.transport" "org.apache.storm.security.auth.SimpleTransportPlugin", "zmq.hwm" 0, "storm.group.mapping.service.params" nil, "worker.profiler.enabled" false, "storm.principal.tolocal" "org.apache.storm.security.auth.DefaultPrincipalToLocal", "supervisor.worker.shutdown.sleep.secs" 1, "pacemaker.host" "localhost", "storm.zookeeper.retry.times" 5, "ui.actions.enabled" true, "zmq.linger.millis" 0, "supervisor.enable" true, "topology.stats.sample.rate" 0.05, "storm.messaging.netty.min_wait_ms" 100, "worker.log.level.reset.poll.secs" 30, "storm.zookeeper.port" 2001, "supervisor.heartbeat.frequency.secs" 5, "topology.enable.message.timeouts" true, "supervisor.cpu.capacity" 400.0, "drpc.worker.threads" 64, "supervisor.blobstore.download.thread.count" 5, "drpc.queue.size" 128, "topology.backpressure.enable" false, "supervisor.blobstore.class" "org.apache.storm.blobstore.NimbusBlobStore", "storm.blobstore.inputstream.buffer.size.bytes" 65536, "topology.shellbolt.max.pending" 100, "drpc.https.keystore.password" "", "nimbus.code.sync.freq.secs" 120, "logviewer.port" 8000, "topology.scheduler.strategy" "org.apache.storm.scheduler.resource.strategies.scheduling.DefaultResourceAwareStrategy", "topology.executor.send.buffer.size" 1024, "resource.aware.scheduler.priority.strategy" "org.apache.storm.scheduler.resource.strategies.priority.DefaultSchedulingPriorityStrategy", "pacemaker.auth.method" "NONE", "storm.daemon.metrics.reporter.plugins" ["org.apache.storm.daemon.metrics.reporters.JmxPreparableReporter"], "topology.worker.logwriter.childopts" "-Xmx64m", "topology.spout.wait.strategy" "org.apache.storm.spout.SleepSpoutWaitStrategy", "ui.host" "0.0.0.0", "storm.nimbus.retry.interval.millis" 2000, "nimbus.inbox.jar.expiration.secs" 3600, "dev.zookeeper.path" "/tmp/dev-storm-zookeeper", "topology.acker.executors" nil, "topology.fall.back.on.java.serialization" true, "topology.eventlogger.executors" 0, "supervisor.localizer.cleanup.interval.ms" 600000, "storm.zookeeper.servers" ["localhost"], "nimbus.thrift.threads" 64, "logviewer.cleanup.age.mins" 10080, "topology.worker.childopts" nil, "topology.classpath" nil, "supervisor.monitor.frequency.secs" 3, "nimbus.credential.renewers.freq.secs" 600, "topology.skip.missing.kryo.registrations" true, "drpc.authorizer.acl.filename" "drpc-auth-acl.yaml", "pacemaker.kerberos.users" [], "storm.group.mapping.service.cache.duration.secs" 120, "topology.testing.always.try.serialize" false, "nimbus.monitor.freq.secs" 10, "storm.health.check.timeout.ms" 5000, "supervisor.supervisors" [], "topology.tasks" nil, "topology.bolts.outgoing.overflow.buffer.enable" false, "storm.messaging.netty.socket.backlog" 500, "topology.workers" 1, "pacemaker.base.threads" 10, "storm.local.dir" "C:\\Users\\ADMINI~1\\AppData\\Local\\Temp\\fc1c162d-e299-4a9e-8599-3ca874fdcb76", "topology.disable.loadaware" false, "worker.childopts" "-Xmx%HEAP-MEM%m -XX:+PrintGCDetails -Xloggc:artifacts/gc.log -XX:+PrintGCDateStamps -XX:+PrintGCTimeStamps -XX:+UseGCLogFileRotation -XX:NumberOfGCLogFiles=10 -XX:GCLogFileSize=1M -XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=artifacts/heapdump", "storm.auth.simple-white-list.users" [], "topology.disruptor.batch.timeout.millis" 1, "topology.message.timeout.secs" 30, "topology.state.synchronization.timeout.secs" 60, "topology.tuple.serializer" "org.apache.storm.serialization.types.ListDelegateSerializer", "supervisor.supervisors.commands" [], "nimbus.blobstore.expiration.secs" 600, "logviewer.childopts" "-Xmx128m", "topology.environment" nil, "topology.debug" false, "topology.disruptor.batch.size" 100, "storm.messaging.netty.max_retries" 300, "ui.childopts" "-Xmx768m", "storm.network.topography.plugin" "org.apache.storm.networktopography.DefaultRackDNSToSwitchMapping", "storm.zookeeper.session.timeout" 20000, "drpc.childopts" "-Xmx768m", "drpc.http.creds.plugin" "org.apache.storm.security.auth.DefaultHttpCredentialsPlugin", "storm.zookeeper.connection.timeout" 15000, "storm.zookeeper.auth.user" nil, "storm.meta.serialization.delegate" "org.apache.storm.serialization.GzipThriftSerializationDelegate", "topology.max.spout.pending" nil, "storm.codedistributor.class" "org.apache.storm.codedistributor.LocalFileSystemCodeDistributor", "nimbus.supervisor.timeout.secs" 60, "nimbus.task.timeout.secs" 30, "drpc.port" 3772, "pacemaker.max.threads" 50, "storm.zookeeper.retry.intervalceiling.millis" 30000, "nimbus.thrift.port" 6627, "storm.auth.simple-acl.admins" [], "topology.component.cpu.pcore.percent" 10.0, "supervisor.memory.capacity.mb" 3072.0, "storm.nimbus.retry.times" 5, "supervisor.worker.start.timeout.secs" 120, "storm.zookeeper.retry.interval" 1000, "logs.users" nil, "worker.profiler.command" "flight.bash", "transactional.zookeeper.port" nil, "drpc.max_buffer_size" 1048576, "pacemaker.thread.timeout" 10, "task.credentials.poll.secs" 30, "blobstore.superuser" "Administrator", "drpc.https.keystore.type" "JKS", "topology.worker.receiver.thread.count" 1, "topology.state.checkpoint.interval.ms" 1000, "supervisor.slots.ports" (1024 1025 1026), "topology.transfer.buffer.size" 1024, "storm.health.check.dir" "healthchecks", "topology.worker.shared.thread.pool.size" 4, "drpc.authorizer.acl.strict" false, "nimbus.file.copy.expiration.secs" 600, "worker.profiler.childopts" "-XX:+UnlockCommercialFeatures -XX:+FlightRecorder", "topology.executor.receive.buffer.size" 1024, "backpressure.disruptor.low.watermark" 0.4, "nimbus.task.launch.secs" 120, "storm.local.mode.zmq" false, "storm.messaging.netty.buffer_size" 5242880, "storm.cluster.state.store" "org.apache.storm.cluster_state.zookeeper_state_factory", "worker.heartbeat.frequency.secs" 1, "storm.log4j2.conf.dir" "log4j2", "ui.http.creds.plugin" "org.apache.storm.security.auth.DefaultHttpCredentialsPlugin", "storm.zookeeper.root" "/storm", "topology.tick.tuple.freq.secs" nil, "drpc.https.port" -1, "storm.workers.artifacts.dir" "workers-artifacts", "supervisor.blobstore.download.max_retries" 3, "task.refresh.poll.secs" 10, "storm.exhibitor.port" 8080, "task.heartbeat.frequency.secs" 3, "pacemaker.port" 6699, "storm.messaging.netty.max_wait_ms" 1000, "topology.component.resources.offheap.memory.mb" 0.0, "drpc.http.port" 3774, "topology.error.throttle.interval.secs" 10, "storm.messaging.transport" "org.apache.storm.messaging.netty.Context", "storm.messaging.netty.authentication" false, "topology.component.resources.onheap.memory.mb" 128.0, "topology.kryo.factory" "org.apache.storm.serialization.DefaultKryoFactory", "worker.gc.childopts" "", "nimbus.topology.validator" "org.apache.storm.nimbus.DefaultTopologyValidator", "nimbus.seeds" ["localhost"], "nimbus.queue.size" 100000, "nimbus.cleanup.inbox.freq.secs" 600, "storm.blobstore.replication.factor" 3, "worker.heap.memory.mb" 768, "logviewer.max.sum.worker.logs.size.mb" 4096, "pacemaker.childopts" "-Xmx1024m", "ui.users" nil, "transactional.zookeeper.servers" nil, "supervisor.worker.timeout.secs" 30, "storm.zookeeper.auth.password" nil, "storm.blobstore.acl.validation.enabled" false, "client.blobstore.class" "org.apache.storm.blobstore.NimbusBlobStore", "supervisor.childopts" "-Xmx256m", "topology.worker.max.heap.size.mb" 768.0, "ui.http.x-frame-options" "DENY", "backpressure.disruptor.high.watermark" 0.9, "ui.filter" nil, "ui.header.buffer.bytes" 4096, "topology.min.replication.count" 1, "topology.disruptor.wait.timeout.millis" 1000, "storm.nimbus.retry.intervalceiling.millis" 60000, "topology.trident.batch.emit.interval.millis" 50, "storm.auth.simple-acl.users" [], "drpc.invocations.threads" 64, "java.library.path" "/usr/local/lib:/opt/local/lib:/usr/lib", "ui.port" 8080, "storm.exhibitor.poll.uripath" "/exhibitor/v1/cluster/list", "storm.messaging.netty.transfer.batch.size" 262144, "logviewer.appender.name" "A1", "nimbus.thrift.max_buffer_size" 1048576, "storm.auth.simple-acl.users.commands" [], "drpc.request.timeout.secs" 600} 21952 [main] INFO o.a.s.l.Localizer - Reconstruct localized resource: C:\Users\ADMINI~1\AppData\Local\Temp\fc1c162d-e299-4a9e-8599-3ca874fdcb76\supervisor\usercache 21952 [main] WARN o.a.s.l.Localizer - No left over resources found for any user during reconstructing of local resources at: C:\Users\ADMINI~1\AppData\Local\Temp\fc1c162d-e299-4a9e-8599-3ca874fdcb76\supervisor\usercache 21963 [main] INFO o.a.s.s.o.a.c.f.i.CuratorFrameworkImpl - Starting 21964 [main] INFO o.a.s.s.o.a.z.ZooKeeper - Initiating client connection, connectString=localhost:2001 sessionTimeout=20000 watcher=org.apache.storm.shade.org.apache.curator.ConnectionState@294aba23 21977 [main-SendThread(127.0.0.1:2001)] INFO o.a.s.s.o.a.z.ClientCnxn - Opening socket connection to server 127.0.0.1/127.0.0.1:2001. Will not attempt to authenticate using SASL (unknown error) 21978 [main-SendThread(127.0.0.1:2001)] INFO o.a.s.s.o.a.z.ClientCnxn - Socket connection established to 127.0.0.1/127.0.0.1:2001, initiating session 21979 [NIOServerCxn.Factory:0.0.0.0/0.0.0.0:2001] INFO o.a.s.s.o.a.z.s.NIOServerCnxnFactory - Accepted socket connection from /127.0.0.1:60069 21980 [NIOServerCxn.Factory:0.0.0.0/0.0.0.0:2001] INFO o.a.s.s.o.a.z.s.ZooKeeperServer - Client attempting to establish new session at /127.0.0.1:60069 22009 [SyncThread:0] INFO o.a.s.s.o.a.z.s.ZooKeeperServer - Established session 0x15d87b848820009 with negotiated timeout 20000 for client /127.0.0.1:60069 22009 [main-SendThread(127.0.0.1:2001)] INFO o.a.s.s.o.a.z.ClientCnxn - Session establishment complete on server 127.0.0.1/127.0.0.1:2001, sessionid = 0x15d87b848820009, negotiated timeout = 20000 22010 [main-EventThread] INFO o.a.s.s.o.a.c.f.s.ConnectionStateManager - State change: CONNECTED 22011 [main-EventThread] INFO o.a.s.zookeeper - Zookeeper state update: :connected:none 22016 [Curator-Framework-0] INFO o.a.s.s.o.a.c.f.i.CuratorFrameworkImpl - backgroundOperationsLoop exiting 22018 [ProcessThread(sid:0 cport:-1):] INFO o.a.s.s.o.a.z.s.PrepRequestProcessor - Processed session termination for sessionid: 0x15d87b848820009 22054 [main] INFO o.a.s.s.o.a.z.ZooKeeper - Session: 0x15d87b848820009 closed 22054 [NIOServerCxn.Factory:0.0.0.0/0.0.0.0:2001] INFO o.a.s.s.o.a.z.s.NIOServerCnxn - Closed socket connection for client /127.0.0.1:60069 which had sessionid 0x15d87b848820009 22055 [main-EventThread] INFO o.a.s.s.o.a.z.ClientCnxn - EventThread shut down 22056 [main] INFO o.a.s.s.o.a.c.f.i.CuratorFrameworkImpl - Starting 22056 [main] INFO o.a.s.s.o.a.z.ZooKeeper - Initiating client connection, connectString=localhost:2001/storm sessionTimeout=20000 watcher=org.apache.storm.shade.org.apache.curator.ConnectionState@5f5827d0 22064 [main-SendThread(127.0.0.1:2001)] INFO o.a.s.s.o.a.z.ClientCnxn - Opening socket connection to server 127.0.0.1/127.0.0.1:2001. Will not attempt to authenticate using SASL (unknown error) 22065 [main-SendThread(127.0.0.1:2001)] INFO o.a.s.s.o.a.z.ClientCnxn - Socket connection established to 127.0.0.1/127.0.0.1:2001, initiating session 22065 [NIOServerCxn.Factory:0.0.0.0/0.0.0.0:2001] INFO o.a.s.s.o.a.z.s.NIOServerCnxnFactory - Accepted socket connection from /127.0.0.1:60072 22066 [NIOServerCxn.Factory:0.0.0.0/0.0.0.0:2001] INFO o.a.s.s.o.a.z.s.ZooKeeperServer - Client attempting to establish new session at /127.0.0.1:60072 22084 [SyncThread:0] INFO o.a.s.s.o.a.z.s.ZooKeeperServer - Established session 0x15d87b84882000a with negotiated timeout 20000 for client /127.0.0.1:60072 22084 [main-SendThread(127.0.0.1:2001)] INFO o.a.s.s.o.a.z.ClientCnxn - Session establishment complete on server 127.0.0.1/127.0.0.1:2001, sessionid = 0x15d87b84882000a, negotiated timeout = 20000 22084 [main-EventThread] INFO o.a.s.s.o.a.c.f.s.ConnectionStateManager - State change: CONNECTED 22217 [main] INFO o.a.s.d.supervisor - Starting supervisor with id a8e2250d-ca68-48bb-bb91-53a2e7ba9080 at host WIN-BQOBV63OBNM 22224 [main] INFO o.a.s.d.supervisor - Starting Supervisor with conf {"topology.builtin.metrics.bucket.size.secs" 60, "nimbus.childopts" "-Xmx1024m", "ui.filter.params" nil, "storm.cluster.mode" "local", "storm.messaging.netty.client_worker_threads" 1, "logviewer.max.per.worker.logs.size.mb" 2048, "supervisor.run.worker.as.user" false, "topology.max.task.parallelism" nil, "topology.priority" 29, "zmq.threads" 1, "storm.group.mapping.service" "org.apache.storm.security.auth.ShellBasedGroupsMapping", "transactional.zookeeper.root" "/transactional", "topology.sleep.spout.wait.strategy.time.ms" 1, "scheduler.display.resource" false, "topology.max.replication.wait.time.sec" 60, "drpc.invocations.port" 3773, "supervisor.localizer.cache.target.size.mb" 10240, "topology.multilang.serializer" "org.apache.storm.multilang.JsonSerializer", "storm.messaging.netty.server_worker_threads" 1, "nimbus.blobstore.class" "org.apache.storm.blobstore.LocalFsBlobStore", "resource.aware.scheduler.eviction.strategy" "org.apache.storm.scheduler.resource.strategies.eviction.DefaultEvictionStrategy", "topology.max.error.report.per.interval" 5, "storm.thrift.transport" "org.apache.storm.security.auth.SimpleTransportPlugin", "zmq.hwm" 0, "storm.group.mapping.service.params" nil, "worker.profiler.enabled" false, "storm.principal.tolocal" "org.apache.storm.security.auth.DefaultPrincipalToLocal", "supervisor.worker.shutdown.sleep.secs" 1, "pacemaker.host" "localhost", "storm.zookeeper.retry.times" 5, "ui.actions.enabled" true, "zmq.linger.millis" 0, "supervisor.enable" true, "topology.stats.sample.rate" 0.05, "storm.messaging.netty.min_wait_ms" 100, "worker.log.level.reset.poll.secs" 30, "storm.zookeeper.port" 2001, "supervisor.heartbeat.frequency.secs" 5, "topology.enable.message.timeouts" true, "supervisor.cpu.capacity" 400.0, "drpc.worker.threads" 64, "supervisor.blobstore.download.thread.count" 5, "drpc.queue.size" 128, "topology.backpressure.enable" false, "supervisor.blobstore.class" "org.apache.storm.blobstore.NimbusBlobStore", "storm.blobstore.inputstream.buffer.size.bytes" 65536, "topology.shellbolt.max.pending" 100, "drpc.https.keystore.password" "", "nimbus.code.sync.freq.secs" 120, "logviewer.port" 8000, "topology.scheduler.strategy" "org.apache.storm.scheduler.resource.strategies.scheduling.DefaultResourceAwareStrategy", "topology.executor.send.buffer.size" 1024, "resource.aware.scheduler.priority.strategy" "org.apache.storm.scheduler.resource.strategies.priority.DefaultSchedulingPriorityStrategy", "pacemaker.auth.method" "NONE", "storm.daemon.metrics.reporter.plugins" ["org.apache.storm.daemon.metrics.reporters.JmxPreparableReporter"], "topology.worker.logwriter.childopts" "-Xmx64m", "topology.spout.wait.strategy" "org.apache.storm.spout.SleepSpoutWaitStrategy", "ui.host" "0.0.0.0", "storm.nimbus.retry.interval.millis" 2000, "nimbus.inbox.jar.expiration.secs" 3600, "dev.zookeeper.path" "/tmp/dev-storm-zookeeper", "topology.acker.executors" nil, "topology.fall.back.on.java.serialization" true, "topology.eventlogger.executors" 0, "supervisor.localizer.cleanup.interval.ms" 600000, "storm.zookeeper.servers" ["localhost"], "nimbus.thrift.threads" 64, "logviewer.cleanup.age.mins" 10080, "topology.worker.childopts" nil, "topology.classpath" nil, "supervisor.monitor.frequency.secs" 3, "nimbus.credential.renewers.freq.secs" 600, "topology.skip.missing.kryo.registrations" true, "drpc.authorizer.acl.filename" "drpc-auth-acl.yaml", "pacemaker.kerberos.users" [], "storm.group.mapping.service.cache.duration.secs" 120, "topology.testing.always.try.serialize" false, "nimbus.monitor.freq.secs" 10, "storm.health.check.timeout.ms" 5000, "supervisor.supervisors" [], "topology.tasks" nil, "topology.bolts.outgoing.overflow.buffer.enable" false, "storm.messaging.netty.socket.backlog" 500, "topology.workers" 1, "pacemaker.base.threads" 10, "storm.local.dir" "C:\\Users\\ADMINI~1\\AppData\\Local\\Temp\\afb39ee7-3111-41c1-9c53-fc75cec05822", "topology.disable.loadaware" false, "worker.childopts" "-Xmx%HEAP-MEM%m -XX:+PrintGCDetails -Xloggc:artifacts/gc.log -XX:+PrintGCDateStamps -XX:+PrintGCTimeStamps -XX:+UseGCLogFileRotation -XX:NumberOfGCLogFiles=10 -XX:GCLogFileSize=1M -XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=artifacts/heapdump", "storm.auth.simple-white-list.users" [], "topology.disruptor.batch.timeout.millis" 1, "topology.message.timeout.secs" 30, "topology.state.synchronization.timeout.secs" 60, "topology.tuple.serializer" "org.apache.storm.serialization.types.ListDelegateSerializer", "supervisor.supervisors.commands" [], "nimbus.blobstore.expiration.secs" 600, "logviewer.childopts" "-Xmx128m", "topology.environment" nil, "topology.debug" false, "topology.disruptor.batch.size" 100, "storm.messaging.netty.max_retries" 300, "ui.childopts" "-Xmx768m", "storm.network.topography.plugin" "org.apache.storm.networktopography.DefaultRackDNSToSwitchMapping", "storm.zookeeper.session.timeout" 20000, "drpc.childopts" "-Xmx768m", "drpc.http.creds.plugin" "org.apache.storm.security.auth.DefaultHttpCredentialsPlugin", "storm.zookeeper.connection.timeout" 15000, "storm.zookeeper.auth.user" nil, "storm.meta.serialization.delegate" "org.apache.storm.serialization.GzipThriftSerializationDelegate", "topology.max.spout.pending" nil, "storm.codedistributor.class" "org.apache.storm.codedistributor.LocalFileSystemCodeDistributor", "nimbus.supervisor.timeout.secs" 60, "nimbus.task.timeout.secs" 30, "drpc.port" 3772, "pacemaker.max.threads" 50, "storm.zookeeper.retry.intervalceiling.millis" 30000, "nimbus.thrift.port" 6627, "storm.auth.simple-acl.admins" [], "topology.component.cpu.pcore.percent" 10.0, "supervisor.memory.capacity.mb" 3072.0, "storm.nimbus.retry.times" 5, "supervisor.worker.start.timeout.secs" 120, "storm.zookeeper.retry.interval" 1000, "logs.users" nil, "worker.profiler.command" "flight.bash", "transactional.zookeeper.port" nil, "drpc.max_buffer_size" 1048576, "pacemaker.thread.timeout" 10, "task.credentials.poll.secs" 30, "blobstore.superuser" "Administrator", "drpc.https.keystore.type" "JKS", "topology.worker.receiver.thread.count" 1, "topology.state.checkpoint.interval.ms" 1000, "supervisor.slots.ports" (1027 1028 1029), "topology.transfer.buffer.size" 1024, "storm.health.check.dir" "healthchecks", "topology.worker.shared.thread.pool.size" 4, "drpc.authorizer.acl.strict" false, "nimbus.file.copy.expiration.secs" 600, "worker.profiler.childopts" "-XX:+UnlockCommercialFeatures -XX:+FlightRecorder", "topology.executor.receive.buffer.size" 1024, "backpressure.disruptor.low.watermark" 0.4, "nimbus.task.launch.secs" 120, "storm.local.mode.zmq" false, "storm.messaging.netty.buffer_size" 5242880, "storm.cluster.state.store" "org.apache.storm.cluster_state.zookeeper_state_factory", "worker.heartbeat.frequency.secs" 1, "storm.log4j2.conf.dir" "log4j2", "ui.http.creds.plugin" "org.apache.storm.security.auth.DefaultHttpCredentialsPlugin", "storm.zookeeper.root" "/storm", "topology.tick.tuple.freq.secs" nil, "drpc.https.port" -1, "storm.workers.artifacts.dir" "workers-artifacts", "supervisor.blobstore.download.max_retries" 3, "task.refresh.poll.secs" 10, "storm.exhibitor.port" 8080, "task.heartbeat.frequency.secs" 3, "pacemaker.port" 6699, "storm.messaging.netty.max_wait_ms" 1000, "topology.component.resources.offheap.memory.mb" 0.0, "drpc.http.port" 3774, "topology.error.throttle.interval.secs" 10, "storm.messaging.transport" "org.apache.storm.messaging.netty.Context", "storm.messaging.netty.authentication" false, "topology.component.resources.onheap.memory.mb" 128.0, "topology.kryo.factory" "org.apache.storm.serialization.DefaultKryoFactory", "worker.gc.childopts" "", "nimbus.topology.validator" "org.apache.storm.nimbus.DefaultTopologyValidator", "nimbus.seeds" ["localhost"], "nimbus.queue.size" 100000, "nimbus.cleanup.inbox.freq.secs" 600, "storm.blobstore.replication.factor" 3, "worker.heap.memory.mb" 768, "logviewer.max.sum.worker.logs.size.mb" 4096, "pacemaker.childopts" "-Xmx1024m", "ui.users" nil, "transactional.zookeeper.servers" nil, "supervisor.worker.timeout.secs" 30, "storm.zookeeper.auth.password" nil, "storm.blobstore.acl.validation.enabled" false, "client.blobstore.class" "org.apache.storm.blobstore.NimbusBlobStore", "supervisor.childopts" "-Xmx256m", "topology.worker.max.heap.size.mb" 768.0, "ui.http.x-frame-options" "DENY", "backpressure.disruptor.high.watermark" 0.9, "ui.filter" nil, "ui.header.buffer.bytes" 4096, "topology.min.replication.count" 1, "topology.disruptor.wait.timeout.millis" 1000, "storm.nimbus.retry.intervalceiling.millis" 60000, "topology.trident.batch.emit.interval.millis" 50, "storm.auth.simple-acl.users" [], "drpc.invocations.threads" 64, "java.library.path" "/usr/local/lib:/opt/local/lib:/usr/lib", "ui.port" 8080, "storm.exhibitor.poll.uripath" "/exhibitor/v1/cluster/list", "storm.messaging.netty.transfer.batch.size" 262144, "logviewer.appender.name" "A1", "nimbus.thrift.max_buffer_size" 1048576, "storm.auth.simple-acl.users.commands" [], "drpc.request.timeout.secs" 600} 22233 [main] INFO o.a.s.l.Localizer - Reconstruct localized resource: C:\Users\ADMINI~1\AppData\Local\Temp\afb39ee7-3111-41c1-9c53-fc75cec05822\supervisor\usercache 22234 [main] WARN o.a.s.l.Localizer - No left over resources found for any user during reconstructing of local resources at: C:\Users\ADMINI~1\AppData\Local\Temp\afb39ee7-3111-41c1-9c53-fc75cec05822\supervisor\usercache 22236 [main] INFO o.a.s.s.o.a.c.f.i.CuratorFrameworkImpl - Starting 22237 [main] INFO o.a.s.s.o.a.z.ZooKeeper - Initiating client connection, connectString=localhost:2001 sessionTimeout=20000 watcher=org.apache.storm.shade.org.apache.curator.ConnectionState@c689973 22242 [main-SendThread(127.0.0.1:2001)] INFO o.a.s.s.o.a.z.ClientCnxn - Opening socket connection to server 127.0.0.1/127.0.0.1:2001. Will not attempt to authenticate using SASL (unknown error) 22243 [main-SendThread(127.0.0.1:2001)] INFO o.a.s.s.o.a.z.ClientCnxn - Socket connection established to 127.0.0.1/127.0.0.1:2001, initiating session 22243 [NIOServerCxn.Factory:0.0.0.0/0.0.0.0:2001] INFO o.a.s.s.o.a.z.s.NIOServerCnxnFactory - Accepted socket connection from /127.0.0.1:60075 22243 [NIOServerCxn.Factory:0.0.0.0/0.0.0.0:2001] INFO o.a.s.s.o.a.z.s.ZooKeeperServer - Client attempting to establish new session at /127.0.0.1:60075 22321 [SyncThread:0] INFO o.a.s.s.o.a.z.s.ZooKeeperServer - Established session 0x15d87b84882000b with negotiated timeout 20000 for client /127.0.0.1:60075 22321 [main-SendThread(127.0.0.1:2001)] INFO o.a.s.s.o.a.z.ClientCnxn - Session establishment complete on server 127.0.0.1/127.0.0.1:2001, sessionid = 0x15d87b84882000b, negotiated timeout = 20000 22322 [main-EventThread] INFO o.a.s.s.o.a.c.f.s.ConnectionStateManager - State change: CONNECTED 22322 [main-EventThread] INFO o.a.s.zookeeper - Zookeeper state update: :connected:none 22325 [Curator-Framework-0] INFO o.a.s.s.o.a.c.f.i.CuratorFrameworkImpl - backgroundOperationsLoop exiting 22327 [ProcessThread(sid:0 cport:-1):] INFO o.a.s.s.o.a.z.s.PrepRequestProcessor - Processed session termination for sessionid: 0x15d87b84882000b 22355 [main] INFO o.a.s.s.o.a.z.ZooKeeper - Session: 0x15d87b84882000b closed 22357 [main] INFO o.a.s.s.o.a.c.f.i.CuratorFrameworkImpl - Starting 22357 [NIOServerCxn.Factory:0.0.0.0/0.0.0.0:2001] INFO o.a.s.s.o.a.z.s.NIOServerCnxn - Closed socket connection for client /127.0.0.1:60075 which had sessionid 0x15d87b84882000b 22358 [main-EventThread] INFO o.a.s.s.o.a.z.ClientCnxn - EventThread shut down 22389 [main] INFO o.a.s.s.o.a.z.ZooKeeper - Initiating client connection, connectString=localhost:2001/storm sessionTimeout=20000 watcher=org.apache.storm.shade.org.apache.curator.ConnectionState@2b148329 22407 [main-SendThread(127.0.0.1:2001)] INFO o.a.s.s.o.a.z.ClientCnxn - Opening socket connection to server 127.0.0.1/127.0.0.1:2001. Will not attempt to authenticate using SASL (unknown error) 22409 [main-SendThread(127.0.0.1:2001)] INFO o.a.s.s.o.a.z.ClientCnxn - Socket connection established to 127.0.0.1/127.0.0.1:2001, initiating session 22410 [NIOServerCxn.Factory:0.0.0.0/0.0.0.0:2001] INFO o.a.s.s.o.a.z.s.NIOServerCnxnFactory - Accepted socket connection from /127.0.0.1:60078 22411 [NIOServerCxn.Factory:0.0.0.0/0.0.0.0:2001] INFO o.a.s.s.o.a.z.s.ZooKeeperServer - Client attempting to establish new session at /127.0.0.1:60078 22445 [main-SendThread(127.0.0.1:2001)] INFO o.a.s.s.o.a.z.ClientCnxn - Session establishment complete on server 127.0.0.1/127.0.0.1:2001, sessionid = 0x15d87b84882000c, negotiated timeout = 20000 22445 [main-EventThread] INFO o.a.s.s.o.a.c.f.s.ConnectionStateManager - State change: CONNECTED 22445 [SyncThread:0] INFO o.a.s.s.o.a.z.s.ZooKeeperServer - Established session 0x15d87b84882000c with negotiated timeout 20000 for client /127.0.0.1:60078 22592 [main] INFO o.a.s.d.supervisor - Starting supervisor with id 22a78b3c-3d5f-4bac-9d9f-392742596655 at host WIN-BQOBV63OBNM 22757 [main] INFO o.a.s.l.ThriftAccessLogger - Request ID: 1 access from: principal: operation: submitTopology 23083 [main] INFO o.a.s.d.nimbus - Received topology submission for StormTopologyAcker with conf {"topology.max.task.parallelism" nil, "topology.submitter.principal" "", "topology.acker.executors" nil, "topology.eventlogger.executors" 0, "topology.max.spout.pending" 1000, "storm.zookeeper.superACL" nil, "topology.users" (), "topology.submitter.user" "Administrator", "topology.kryo.register" nil, "topology.kryo.decorators" (), "storm.id" "StormTopologyAcker-1-1501220593", "topology.name" "StormTopologyAcker"} 23345 [main] INFO o.a.s.d.nimbus - uploadedJar 23412 [main] INFO o.a.s.s.o.a.c.f.i.CuratorFrameworkImpl - Starting 23413 [main] INFO o.a.s.s.o.a.z.ZooKeeper - Initiating client connection, connectString=localhost:2001/storm sessionTimeout=20000 watcher=org.apache.storm.shade.org.apache.curator.ConnectionState@460b50df 23421 [main-SendThread(127.0.0.1:2001)] INFO o.a.s.s.o.a.z.ClientCnxn - Opening socket connection to server 127.0.0.1/127.0.0.1:2001. Will not attempt to authenticate using SASL (unknown error) 23422 [main-SendThread(127.0.0.1:2001)] INFO o.a.s.s.o.a.z.ClientCnxn - Socket connection established to 127.0.0.1/127.0.0.1:2001, initiating session 23422 [NIOServerCxn.Factory:0.0.0.0/0.0.0.0:2001] INFO o.a.s.s.o.a.z.s.NIOServerCnxnFactory - Accepted socket connection from /127.0.0.1:60081 23423 [NIOServerCxn.Factory:0.0.0.0/0.0.0.0:2001] INFO o.a.s.s.o.a.z.s.ZooKeeperServer - Client attempting to establish new session at /127.0.0.1:60081 23455 [SyncThread:0] INFO o.a.s.s.o.a.z.s.ZooKeeperServer - Established session 0x15d87b84882000d with negotiated timeout 20000 for client /127.0.0.1:60081 23456 [main-SendThread(127.0.0.1:2001)] INFO o.a.s.s.o.a.z.ClientCnxn - Session establishment complete on server 127.0.0.1/127.0.0.1:2001, sessionid = 0x15d87b84882000d, negotiated timeout = 20000 23456 [main-EventThread] INFO o.a.s.s.o.a.c.f.s.ConnectionStateManager - State change: CONNECTED 23461 [ProcessThread(sid:0 cport:-1):] INFO o.a.s.s.o.a.z.s.PrepRequestProcessor - Got user-level KeeperException when processing sessionid:0x15d87b84882000d type:create cxid:0x2 zxid:0x27 txntype:-1 reqpath:n/a Error Path:/storm/blobstoremaxkeysequencenumber Error:KeeperErrorCode = NoNode for /storm/blobstoremaxkeysequencenumber 23584 [Curator-Framework-0] INFO o.a.s.s.o.a.c.f.i.CuratorFrameworkImpl - backgroundOperationsLoop exiting 23587 [ProcessThread(sid:0 cport:-1):] INFO o.a.s.s.o.a.z.s.PrepRequestProcessor - Processed session termination for sessionid: 0x15d87b84882000d 23636 [main] INFO o.a.s.s.o.a.z.ZooKeeper - Session: 0x15d87b84882000d closed 23636 [NIOServerCxn.Factory:0.0.0.0/0.0.0.0:2001] INFO o.a.s.s.o.a.z.s.NIOServerCnxn - Closed socket connection for client /127.0.0.1:60081 which had sessionid 0x15d87b84882000d 23636 [main-EventThread] INFO o.a.s.s.o.a.z.ClientCnxn - EventThread shut down 23638 [main] INFO o.a.s.cluster - setup-path/blobstore/StormTopologyAcker-1-1501220593-stormconf.ser/WIN-BQOBV63OBNM:6627-1 23806 [main] INFO o.a.s.s.o.a.c.f.i.CuratorFrameworkImpl - Starting 23807 [main] INFO o.a.s.s.o.a.z.ZooKeeper - Initiating client connection, connectString=localhost:2001/storm sessionTimeout=20000 watcher=org.apache.storm.shade.org.apache.curator.ConnectionState@2cd388f5 23816 [main-SendThread(127.0.0.1:2001)] INFO o.a.s.s.o.a.z.ClientCnxn - Opening socket connection to server 127.0.0.1/127.0.0.1:2001. Will not attempt to authenticate using SASL (unknown error) 23818 [main-SendThread(127.0.0.1:2001)] INFO o.a.s.s.o.a.z.ClientCnxn - Socket connection established to 127.0.0.1/127.0.0.1:2001, initiating session 23818 [NIOServerCxn.Factory:0.0.0.0/0.0.0.0:2001] INFO o.a.s.s.o.a.z.s.NIOServerCnxnFactory - Accepted socket connection from /127.0.0.1:60084 23818 [NIOServerCxn.Factory:0.0.0.0/0.0.0.0:2001] INFO o.a.s.s.o.a.z.s.ZooKeeperServer - Client attempting to establish new session at /127.0.0.1:60084 23880 [main-SendThread(127.0.0.1:2001)] INFO o.a.s.s.o.a.z.ClientCnxn - Session establishment complete on server 127.0.0.1/127.0.0.1:2001, sessionid = 0x15d87b84882000e, negotiated timeout = 20000 23880 [SyncThread:0] INFO o.a.s.s.o.a.z.s.ZooKeeperServer - Established session 0x15d87b84882000e with negotiated timeout 20000 for client /127.0.0.1:60084 23881 [main-EventThread] INFO o.a.s.s.o.a.c.f.s.ConnectionStateManager - State change: CONNECTED 23947 [Curator-Framework-0] INFO o.a.s.s.o.a.c.f.i.CuratorFrameworkImpl - backgroundOperationsLoop exiting 23950 [ProcessThread(sid:0 cport:-1):] INFO o.a.s.s.o.a.z.s.PrepRequestProcessor - Processed session termination for sessionid: 0x15d87b84882000e 23990 [main] INFO o.a.s.s.o.a.z.ZooKeeper - Session: 0x15d87b84882000e closed 23991 [main-EventThread] INFO o.a.s.s.o.a.z.ClientCnxn - EventThread shut down 23993 [NIOServerCxn.Factory:0.0.0.0/0.0.0.0:2001] WARN o.a.s.s.o.a.z.s.NIOServerCnxn - caught end of stream exception org.apache.storm.shade.org.apache.zookeeper.server.ServerCnxn$EndOfStreamException: Unable to read additional data from client sessionid 0x15d87b84882000e, likely client has closed socket at org.apache.storm.shade.org.apache.zookeeper.server.NIOServerCnxn.doIO(NIOServerCnxn.java:228) [storm-core-1.0.2.jar:1.0.2] at org.apache.storm.shade.org.apache.zookeeper.server.NIOServerCnxnFactory.run(NIOServerCnxnFactory.java:208) [storm-core-1.0.2.jar:1.0.2] at java.lang.Thread.run(Unknown Source) [?:1.8.0_66] 23993 [main] INFO o.a.s.cluster - setup-path/blobstore/StormTopologyAcker-1-1501220593-stormcode.ser/WIN-BQOBV63OBNM:6627-1 23994 [NIOServerCxn.Factory:0.0.0.0/0.0.0.0:2001] INFO o.a.s.s.o.a.z.s.NIOServerCnxn - Closed socket connection for client /127.0.0.1:60084 which had sessionid 0x15d87b84882000e 24096 [main] INFO o.a.s.d.nimbus - desired replication count 1 achieved, current-replication-count for conf key = 1, current-replication-count for code key = 1, current-replication-count for jar key = 1 24396 [main] INFO o.a.s.d.nimbus - Activating StormTopologyAcker: StormTopologyAcker-1-1501220593 32768 [timer] INFO o.a.s.s.EvenScheduler - Available slots: (["a8e2250d-ca68-48bb-bb91-53a2e7ba9080" 1024] ["a8e2250d-ca68-48bb-bb91-53a2e7ba9080" 1025] ["a8e2250d-ca68-48bb-bb91-53a2e7ba9080" 1026] ["22a78b3c-3d5f-4bac-9d9f-392742596655" 1027] ["22a78b3c-3d5f-4bac-9d9f-392742596655" 1028] ["22a78b3c-3d5f-4bac-9d9f-392742596655" 1029]) 32878 [timer] INFO o.a.s.d.nimbus - Setting new assignment for topology id StormTopologyAcker-1-1501220593: #org.apache.storm.daemon.common.Assignment{:master-code-dir "C:\\Users\\ADMINI~1\\AppData\\Local\\Temp\\d7cdc68c-f54c-4677-ac0e-d73c3b2effb3", :node->host {"a8e2250d-ca68-48bb-bb91-53a2e7ba9080" "WIN-BQOBV63OBNM"}, :executor->node+port {[2 2] ["a8e2250d-ca68-48bb-bb91-53a2e7ba9080" 1024], [1 1] ["a8e2250d-ca68-48bb-bb91-53a2e7ba9080" 1024], [3 3] ["a8e2250d-ca68-48bb-bb91-53a2e7ba9080" 1024]}, :executor->start-time-secs {[1 1] 1501220603, [2 2] 1501220603, [3 3] 1501220603}, :worker->resources {["a8e2250d-ca68-48bb-bb91-53a2e7ba9080" 1024] [0.0 0.0 0.0]}} 33108 [Thread-7] INFO o.a.s.d.supervisor - Downloading code for storm id StormTopologyAcker-1-1501220593 33116 [Thread-7] INFO o.a.s.s.o.a.c.f.i.CuratorFrameworkImpl - Starting 33117 [Thread-7] INFO o.a.s.s.o.a.z.ZooKeeper - Initiating client connection, connectString=localhost:2001/storm sessionTimeout=20000 watcher=org.apache.storm.shade.org.apache.curator.ConnectionState@284a8f8c 33127 [Thread-7] INFO o.a.s.b.FileBlobStoreImpl - Creating new blob store based in C:\Users\ADMINI~1\AppData\Local\Temp\d7cdc68c-f54c-4677-ac0e-d73c3b2effb3\blobs 33143 [Thread-7-SendThread(127.0.0.1:2001)] INFO o.a.s.s.o.a.z.ClientCnxn - Opening socket connection to server 127.0.0.1/127.0.0.1:2001. Will not attempt to authenticate using SASL (unknown error) 33145 [Thread-7-SendThread(127.0.0.1:2001)] INFO o.a.s.s.o.a.z.ClientCnxn - Socket connection established to 127.0.0.1/127.0.0.1:2001, initiating session 33145 [NIOServerCxn.Factory:0.0.0.0/0.0.0.0:2001] INFO o.a.s.s.o.a.z.s.NIOServerCnxnFactory - Accepted socket connection from /127.0.0.1:60087 33146 [NIOServerCxn.Factory:0.0.0.0/0.0.0.0:2001] INFO o.a.s.s.o.a.z.s.ZooKeeperServer - Client attempting to establish new session at /127.0.0.1:60087 33202 [SyncThread:0] INFO o.a.s.s.o.a.z.s.ZooKeeperServer - Established session 0x15d87b84882000f with negotiated timeout 20000 for client /127.0.0.1:60087 33202 [Thread-7-SendThread(127.0.0.1:2001)] INFO o.a.s.s.o.a.z.ClientCnxn - Session establishment complete on server 127.0.0.1/127.0.0.1:2001, sessionid = 0x15d87b84882000f, negotiated timeout = 20000 33203 [Thread-7-EventThread] INFO o.a.s.s.o.a.c.f.s.ConnectionStateManager - State change: CONNECTED 33261 [Curator-Framework-0] INFO o.a.s.s.o.a.c.f.i.CuratorFrameworkImpl - backgroundOperationsLoop exiting 33266 [ProcessThread(sid:0 cport:-1):] INFO o.a.s.s.o.a.z.s.PrepRequestProcessor - Processed session termination for sessionid: 0x15d87b84882000f 33322 [NIOServerCxn.Factory:0.0.0.0/0.0.0.0:2001] WARN o.a.s.s.o.a.z.s.NIOServerCnxn - caught end of stream exception org.apache.storm.shade.org.apache.zookeeper.server.ServerCnxn$EndOfStreamException: Unable to read additional data from client sessionid 0x15d87b84882000f, likely client has closed socket at org.apache.storm.shade.org.apache.zookeeper.server.NIOServerCnxn.doIO(NIOServerCnxn.java:228) [storm-core-1.0.2.jar:1.0.2] at org.apache.storm.shade.org.apache.zookeeper.server.NIOServerCnxnFactory.run(NIOServerCnxnFactory.java:208) [storm-core-1.0.2.jar:1.0.2] at java.lang.Thread.run(Unknown Source) [?:1.8.0_66] 33323 [NIOServerCxn.Factory:0.0.0.0/0.0.0.0:2001] INFO o.a.s.s.o.a.z.s.NIOServerCnxn - Closed socket connection for client /127.0.0.1:60087 which had sessionid 0x15d87b84882000f 33325 [Thread-7] INFO o.a.s.s.o.a.z.ZooKeeper - Session: 0x15d87b84882000f closed 33344 [Thread-7-EventThread] INFO o.a.s.s.o.a.z.ClientCnxn - EventThread shut down 34504 [Thread-7] INFO o.a.s.d.supervisor - Finished downloading code for storm id StormTopologyAcker-1-1501220593 34591 [Thread-8] INFO o.a.s.d.supervisor - Launching worker with assignment {:storm-id "StormTopologyAcker-1-1501220593", :executors [[2 2] [1 1] [3 3]], :resources #object[org.apache.storm.generated.WorkerResources 0x53f66d42 "WorkerResources(mem_on_heap:0.0, mem_off_heap:0.0, cpu:0.0)"]} for this supervisor a8e2250d-ca68-48bb-bb91-53a2e7ba9080 on port 1024 with id 715c933e-5f3a-4a1c-b2f3-b4ace693b7fc 34611 [Thread-8] INFO o.a.s.d.worker - Launching worker for StormTopologyAcker-1-1501220593 on a8e2250d-ca68-48bb-bb91-53a2e7ba9080:1024 with id 715c933e-5f3a-4a1c-b2f3-b4ace693b7fc and conf {"topology.builtin.metrics.bucket.size.secs" 60, "nimbus.childopts" "-Xmx1024m", "ui.filter.params" nil, "storm.cluster.mode" "local", "storm.messaging.netty.client_worker_threads" 1, "logviewer.max.per.worker.logs.size.mb" 2048, "supervisor.run.worker.as.user" false, "topology.max.task.parallelism" nil, "topology.priority" 29, "zmq.threads" 1, "storm.group.mapping.service" "org.apache.storm.security.auth.ShellBasedGroupsMapping", "transactional.zookeeper.root" "/transactional", "topology.sleep.spout.wait.strategy.time.ms" 1, "scheduler.display.resource" false, "topology.max.replication.wait.time.sec" 60, "drpc.invocations.port" 3773, "supervisor.localizer.cache.target.size.mb" 10240, "topology.multilang.serializer" "org.apache.storm.multilang.JsonSerializer", "storm.messaging.netty.server_worker_threads" 1, "nimbus.blobstore.class" "org.apache.storm.blobstore.LocalFsBlobStore", "resource.aware.scheduler.eviction.strategy" "org.apache.storm.scheduler.resource.strategies.eviction.DefaultEvictionStrategy", "topology.max.error.report.per.interval" 5, "storm.thrift.transport" "org.apache.storm.security.auth.SimpleTransportPlugin", "zmq.hwm" 0, "storm.group.mapping.service.params" nil, "worker.profiler.enabled" false, "storm.principal.tolocal" "org.apache.storm.security.auth.DefaultPrincipalToLocal", "supervisor.worker.shutdown.sleep.secs" 1, "pacemaker.host" "localhost", "storm.zookeeper.retry.times" 5, "ui.actions.enabled" true, "zmq.linger.millis" 0, "supervisor.enable" true, "topology.stats.sample.rate" 0.05, "storm.messaging.netty.min_wait_ms" 100, "worker.log.level.reset.poll.secs" 30, "storm.zookeeper.port" 2001, "supervisor.heartbeat.frequency.secs" 5, "topology.enable.message.timeouts" true, "supervisor.cpu.capacity" 400.0, "drpc.worker.threads" 64, "supervisor.blobstore.download.thread.count" 5, "drpc.queue.size" 128, "topology.backpressure.enable" false, "supervisor.blobstore.class" "org.apache.storm.blobstore.NimbusBlobStore", "storm.blobstore.inputstream.buffer.size.bytes" 65536, "topology.shellbolt.max.pending" 100, "drpc.https.keystore.password" "", "nimbus.code.sync.freq.secs" 120, "logviewer.port" 8000, "topology.scheduler.strategy" "org.apache.storm.scheduler.resource.strategies.scheduling.DefaultResourceAwareStrategy", "topology.executor.send.buffer.size" 1024, "resource.aware.scheduler.priority.strategy" "org.apache.storm.scheduler.resource.strategies.priority.DefaultSchedulingPriorityStrategy", "pacemaker.auth.method" "NONE", "storm.daemon.metrics.reporter.plugins" ["org.apache.storm.daemon.metrics.reporters.JmxPreparableReporter"], "topology.worker.logwriter.childopts" "-Xmx64m", "topology.spout.wait.strategy" "org.apache.storm.spout.SleepSpoutWaitStrategy", "ui.host" "0.0.0.0", "storm.nimbus.retry.interval.millis" 2000, "nimbus.inbox.jar.expiration.secs" 3600, "dev.zookeeper.path" "/tmp/dev-storm-zookeeper", "topology.acker.executors" nil, "topology.fall.back.on.java.serialization" true, "topology.eventlogger.executors" 0, "supervisor.localizer.cleanup.interval.ms" 600000, "storm.zookeeper.servers" ["localhost"], "nimbus.thrift.threads" 64, "logviewer.cleanup.age.mins" 10080, "topology.worker.childopts" nil, "topology.classpath" nil, "supervisor.monitor.frequency.secs" 3, "nimbus.credential.renewers.freq.secs" 600, "topology.skip.missing.kryo.registrations" true, "drpc.authorizer.acl.filename" "drpc-auth-acl.yaml", "pacemaker.kerberos.users" [], "storm.group.mapping.service.cache.duration.secs" 120, "topology.testing.always.try.serialize" false, "nimbus.monitor.freq.secs" 10, "storm.health.check.timeout.ms" 5000, "supervisor.supervisors" [], "topology.tasks" nil, "topology.bolts.outgoing.overflow.buffer.enable" false, "storm.messaging.netty.socket.backlog" 500, "topology.workers" 1, "pacemaker.base.threads" 10, "storm.local.dir" "C:\\Users\\ADMINI~1\\AppData\\Local\\Temp\\fc1c162d-e299-4a9e-8599-3ca874fdcb76", "topology.disable.loadaware" false, "worker.childopts" "-Xmx%HEAP-MEM%m -XX:+PrintGCDetails -Xloggc:artifacts/gc.log -XX:+PrintGCDateStamps -XX:+PrintGCTimeStamps -XX:+UseGCLogFileRotation -XX:NumberOfGCLogFiles=10 -XX:GCLogFileSize=1M -XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=artifacts/heapdump", "storm.auth.simple-white-list.users" [], "topology.disruptor.batch.timeout.millis" 1, "topology.message.timeout.secs" 30, "topology.state.synchronization.timeout.secs" 60, "topology.tuple.serializer" "org.apache.storm.serialization.types.ListDelegateSerializer", "supervisor.supervisors.commands" [], "nimbus.blobstore.expiration.secs" 600, "logviewer.childopts" "-Xmx128m", "topology.environment" nil, "topology.debug" false, "topology.disruptor.batch.size" 100, "storm.messaging.netty.max_retries" 300, "ui.childopts" "-Xmx768m", "storm.network.topography.plugin" "org.apache.storm.networktopography.DefaultRackDNSToSwitchMapping", "storm.zookeeper.session.timeout" 20000, "drpc.childopts" "-Xmx768m", "drpc.http.creds.plugin" "org.apache.storm.security.auth.DefaultHttpCredentialsPlugin", "storm.zookeeper.connection.timeout" 15000, "storm.zookeeper.auth.user" nil, "storm.meta.serialization.delegate" "org.apache.storm.serialization.GzipThriftSerializationDelegate", "topology.max.spout.pending" nil, "storm.codedistributor.class" "org.apache.storm.codedistributor.LocalFileSystemCodeDistributor", "nimbus.supervisor.timeout.secs" 60, "nimbus.task.timeout.secs" 30, "drpc.port" 3772, "pacemaker.max.threads" 50, "storm.zookeeper.retry.intervalceiling.millis" 30000, "nimbus.thrift.port" 6627, "storm.auth.simple-acl.admins" [], "topology.component.cpu.pcore.percent" 10.0, "supervisor.memory.capacity.mb" 3072.0, "storm.nimbus.retry.times" 5, "supervisor.worker.start.timeout.secs" 120, "storm.zookeeper.retry.interval" 1000, "logs.users" nil, "worker.profiler.command" "flight.bash", "transactional.zookeeper.port" nil, "drpc.max_buffer_size" 1048576, "pacemaker.thread.timeout" 10, "task.credentials.poll.secs" 30, "blobstore.superuser" "Administrator", "drpc.https.keystore.type" "JKS", "topology.worker.receiver.thread.count" 1, "topology.state.checkpoint.interval.ms" 1000, "supervisor.slots.ports" (1024 1025 1026), "topology.transfer.buffer.size" 1024, "storm.health.check.dir" "healthchecks", "topology.worker.shared.thread.pool.size" 4, "drpc.authorizer.acl.strict" false, "nimbus.file.copy.expiration.secs" 600, "worker.profiler.childopts" "-XX:+UnlockCommercialFeatures -XX:+FlightRecorder", "topology.executor.receive.buffer.size" 1024, "backpressure.disruptor.low.watermark" 0.4, "nimbus.task.launch.secs" 120, "storm.local.mode.zmq" false, "storm.messaging.netty.buffer_size" 5242880, "storm.cluster.state.store" "org.apache.storm.cluster_state.zookeeper_state_factory", "worker.heartbeat.frequency.secs" 1, "storm.log4j2.conf.dir" "log4j2", "ui.http.creds.plugin" "org.apache.storm.security.auth.DefaultHttpCredentialsPlugin", "storm.zookeeper.root" "/storm", "topology.tick.tuple.freq.secs" nil, "drpc.https.port" -1, "storm.workers.artifacts.dir" "workers-artifacts", "supervisor.blobstore.download.max_retries" 3, "task.refresh.poll.secs" 10, "storm.exhibitor.port" 8080, "task.heartbeat.frequency.secs" 3, "pacemaker.port" 6699, "storm.messaging.netty.max_wait_ms" 1000, "topology.component.resources.offheap.memory.mb" 0.0, "drpc.http.port" 3774, "topology.error.throttle.interval.secs" 10, "storm.messaging.transport" "org.apache.storm.messaging.netty.Context", "storm.messaging.netty.authentication" false, "topology.component.resources.onheap.memory.mb" 128.0, "topology.kryo.factory" "org.apache.storm.serialization.DefaultKryoFactory", "worker.gc.childopts" "", "nimbus.topology.validator" "org.apache.storm.nimbus.DefaultTopologyValidator", "nimbus.seeds" ["localhost"], "nimbus.queue.size" 100000, "nimbus.cleanup.inbox.freq.secs" 600, "storm.blobstore.replication.factor" 3, "worker.heap.memory.mb" 768, "logviewer.max.sum.worker.logs.size.mb" 4096, "pacemaker.childopts" "-Xmx1024m", "ui.users" nil, "transactional.zookeeper.servers" nil, "supervisor.worker.timeout.secs" 30, "storm.zookeeper.auth.password" nil, "storm.blobstore.acl.validation.enabled" false, "client.blobstore.class" "org.apache.storm.blobstore.NimbusBlobStore", "supervisor.childopts" "-Xmx256m", "topology.worker.max.heap.size.mb" 768.0, "ui.http.x-frame-options" "DENY", "backpressure.disruptor.high.watermark" 0.9, "ui.filter" nil, "ui.header.buffer.bytes" 4096, "topology.min.replication.count" 1, "topology.disruptor.wait.timeout.millis" 1000, "storm.nimbus.retry.intervalceiling.millis" 60000, "topology.trident.batch.emit.interval.millis" 50, "storm.auth.simple-acl.users" [], "drpc.invocations.threads" 64, "java.library.path" "/usr/local/lib:/opt/local/lib:/usr/lib", "ui.port" 8080, "storm.exhibitor.poll.uripath" "/exhibitor/v1/cluster/list", "storm.messaging.netty.transfer.batch.size" 262144, "logviewer.appender.name" "A1", "nimbus.thrift.max_buffer_size" 1048576, "storm.auth.simple-acl.users.commands" [], "drpc.request.timeout.secs" 600} 34626 [Thread-8] INFO o.a.s.s.o.a.c.f.i.CuratorFrameworkImpl - Starting 34629 [Thread-8] INFO o.a.s.s.o.a.z.ZooKeeper - Initiating client connection, connectString=localhost:2001 sessionTimeout=20000 watcher=org.apache.storm.shade.org.apache.curator.ConnectionState@fe8f4c9 34651 [Thread-8-SendThread(127.0.0.1:2001)] INFO o.a.s.s.o.a.z.ClientCnxn - Opening socket connection to server 127.0.0.1/127.0.0.1:2001. Will not attempt to authenticate using SASL (unknown error) 34652 [NIOServerCxn.Factory:0.0.0.0/0.0.0.0:2001] INFO o.a.s.s.o.a.z.s.NIOServerCnxnFactory - Accepted socket connection from /127.0.0.1:60090 34653 [Thread-8-SendThread(127.0.0.1:2001)] INFO o.a.s.s.o.a.z.ClientCnxn - Socket connection established to 127.0.0.1/127.0.0.1:2001, initiating session 34653 [NIOServerCxn.Factory:0.0.0.0/0.0.0.0:2001] INFO o.a.s.s.o.a.z.s.ZooKeeperServer - Client attempting to establish new session at /127.0.0.1:60090 34789 [SyncThread:0] INFO o.a.s.s.o.a.z.s.ZooKeeperServer - Established session 0x15d87b848820010 with negotiated timeout 20000 for client /127.0.0.1:60090 34790 [Thread-8-SendThread(127.0.0.1:2001)] INFO o.a.s.s.o.a.z.ClientCnxn - Session establishment complete on server 127.0.0.1/127.0.0.1:2001, sessionid = 0x15d87b848820010, negotiated timeout = 20000 34790 [Thread-8-EventThread] INFO o.a.s.s.o.a.c.f.s.ConnectionStateManager - State change: CONNECTED 34791 [Thread-8-EventThread] INFO o.a.s.zookeeper - Zookeeper state update: :connected:none 34793 [Curator-Framework-0] INFO o.a.s.s.o.a.c.f.i.CuratorFrameworkImpl - backgroundOperationsLoop exiting 34795 [ProcessThread(sid:0 cport:-1):] INFO o.a.s.s.o.a.z.s.PrepRequestProcessor - Processed session termination for sessionid: 0x15d87b848820010 34935 [Thread-8] INFO o.a.s.s.o.a.z.ZooKeeper - Session: 0x15d87b848820010 closed 34935 [Thread-8-EventThread] INFO o.a.s.s.o.a.z.ClientCnxn - EventThread shut down 34936 [Thread-8] INFO o.a.s.s.o.a.c.f.i.CuratorFrameworkImpl - Starting 34936 [NIOServerCxn.Factory:0.0.0.0/0.0.0.0:2001] WARN o.a.s.s.o.a.z.s.NIOServerCnxn - caught end of stream exception org.apache.storm.shade.org.apache.zookeeper.server.ServerCnxn$EndOfStreamException: Unable to read additional data from client sessionid 0x15d87b848820010, likely client has closed socket at org.apache.storm.shade.org.apache.zookeeper.server.NIOServerCnxn.doIO(NIOServerCnxn.java:228) [storm-core-1.0.2.jar:1.0.2] at org.apache.storm.shade.org.apache.zookeeper.server.NIOServerCnxnFactory.run(NIOServerCnxnFactory.java:208) [storm-core-1.0.2.jar:1.0.2] at java.lang.Thread.run(Unknown Source) [?:1.8.0_66] 34936 [Thread-8] INFO o.a.s.s.o.a.z.ZooKeeper - Initiating client connection, connectString=localhost:2001/storm sessionTimeout=20000 watcher=org.apache.storm.shade.org.apache.curator.ConnectionState@12401e6d 34937 [NIOServerCxn.Factory:0.0.0.0/0.0.0.0:2001] INFO o.a.s.s.o.a.z.s.NIOServerCnxn - Closed socket connection for client /127.0.0.1:60090 which had sessionid 0x15d87b848820010 34940 [Thread-8-SendThread(127.0.0.1:2001)] INFO o.a.s.s.o.a.z.ClientCnxn - Opening socket connection to server 127.0.0.1/127.0.0.1:2001. Will not attempt to authenticate using SASL (unknown error) 34941 [Thread-8-SendThread(127.0.0.1:2001)] INFO o.a.s.s.o.a.z.ClientCnxn - Socket connection established to 127.0.0.1/127.0.0.1:2001, initiating session 34941 [NIOServerCxn.Factory:0.0.0.0/0.0.0.0:2001] INFO o.a.s.s.o.a.z.s.NIOServerCnxnFactory - Accepted socket connection from /127.0.0.1:60093 34942 [NIOServerCxn.Factory:0.0.0.0/0.0.0.0:2001] INFO o.a.s.s.o.a.z.s.ZooKeeperServer - Client attempting to establish new session at /127.0.0.1:60093 34965 [SyncThread:0] INFO o.a.s.s.o.a.z.s.ZooKeeperServer - Established session 0x15d87b848820011 with negotiated timeout 20000 for client /127.0.0.1:60093 34965 [Thread-8-SendThread(127.0.0.1:2001)] INFO o.a.s.s.o.a.z.ClientCnxn - Session establishment complete on server 127.0.0.1/127.0.0.1:2001, sessionid = 0x15d87b848820011, negotiated timeout = 20000 34965 [Thread-8-EventThread] INFO o.a.s.s.o.a.c.f.s.ConnectionStateManager - State change: CONNECTED 34974 [Thread-8] INFO o.a.s.s.a.AuthUtils - Got AutoCreds [] 34978 [Thread-8] INFO o.a.s.d.worker - Reading Assignments. 35151 [Thread-8] INFO o.a.s.d.worker - Registering IConnectionCallbacks for a8e2250d-ca68-48bb-bb91-53a2e7ba9080:1024 35230 [Thread-8] INFO o.a.s.d.executor - Loading executor MySpout:[2 2] 35300 [Thread-8] INFO o.a.s.d.executor - Loaded executor tasks MySpout:[2 2] 35774 [Thread-8] INFO o.a.s.d.executor - Finished loading executor MySpout:[2 2] 35800 [Thread-8] INFO o.a.s.d.executor - Loading executor __acker:[3 3] 35805 [Thread-8] INFO o.a.s.d.executor - Loaded executor tasks __acker:[3 3] 35846 [Thread-8] INFO o.a.s.d.executor - Timeouts disabled for executor __acker:[3 3] 35846 [Thread-8] INFO o.a.s.d.executor - Finished loading executor __acker:[3 3] 35855 [Thread-8] INFO o.a.s.d.executor - Loading executor MyBolt:[1 1] 35856 [Thread-8] INFO o.a.s.d.executor - Loaded executor tasks MyBolt:[1 1] 35859 [Thread-8] INFO o.a.s.d.executor - Finished loading executor MyBolt:[1 1] 35872 [Thread-8] INFO o.a.s.d.executor - Loading executor __system:[-1 -1] 35874 [Thread-8] INFO o.a.s.d.executor - Loaded executor tasks __system:[-1 -1] 35879 [Thread-8] INFO o.a.s.d.executor - Finished loading executor __system:[-1 -1] 35899 [Thread-8] INFO o.a.s.d.worker - Started with log levels: {"" #object[org.apache.logging.log4j.Level 0x2c9c9097 "INFO"], "org.apache.zookeeper" #object[org.apache.logging.log4j.Level 0xd4f4340 "WARN"]} 35912 [Thread-8] INFO o.a.s.d.worker - Worker has topology config {"topology.builtin.metrics.bucket.size.secs" 60, "nimbus.childopts" "-Xmx1024m", "ui.filter.params" nil, "storm.cluster.mode" "local", "storm.messaging.netty.client_worker_threads" 1, "logviewer.max.per.worker.logs.size.mb" 2048, "supervisor.run.worker.as.user" false, "topology.max.task.parallelism" nil, "topology.priority" 29, "zmq.threads" 1, "storm.group.mapping.service" "org.apache.storm.security.auth.ShellBasedGroupsMapping", "transactional.zookeeper.root" "/transactional", "topology.sleep.spout.wait.strategy.time.ms" 1, "scheduler.display.resource" false, "topology.max.replication.wait.time.sec" 60, "drpc.invocations.port" 3773, "supervisor.localizer.cache.target.size.mb" 10240, "topology.multilang.serializer" "org.apache.storm.multilang.JsonSerializer", "storm.messaging.netty.server_worker_threads" 1, "nimbus.blobstore.class" "org.apache.storm.blobstore.LocalFsBlobStore", "resource.aware.scheduler.eviction.strategy" "org.apache.storm.scheduler.resource.strategies.eviction.DefaultEvictionStrategy", "topology.max.error.report.per.interval" 5, "storm.thrift.transport" "org.apache.storm.security.auth.SimpleTransportPlugin", "zmq.hwm" 0, "storm.group.mapping.service.params" nil, "worker.profiler.enabled" false, "storm.principal.tolocal" "org.apache.storm.security.auth.DefaultPrincipalToLocal", "supervisor.worker.shutdown.sleep.secs" 1, "pacemaker.host" "localhost", "storm.zookeeper.retry.times" 5, "ui.actions.enabled" true, "zmq.linger.millis" 0, "supervisor.enable" true, "topology.stats.sample.rate" 0.05, "storm.messaging.netty.min_wait_ms" 100, "worker.log.level.reset.poll.secs" 30, "storm.zookeeper.port" 2001, "supervisor.heartbeat.frequency.secs" 5, "topology.enable.message.timeouts" true, "supervisor.cpu.capacity" 400.0, "drpc.worker.threads" 64, "supervisor.blobstore.download.thread.count" 5, "drpc.queue.size" 128, "topology.backpressure.enable" false, "supervisor.blobstore.class" "org.apache.storm.blobstore.NimbusBlobStore", "storm.blobstore.inputstream.buffer.size.bytes" 65536, "topology.shellbolt.max.pending" 100, "drpc.https.keystore.password" "", "nimbus.code.sync.freq.secs" 120, "logviewer.port" 8000, "topology.scheduler.strategy" "org.apache.storm.scheduler.resource.strategies.scheduling.DefaultResourceAwareStrategy", "topology.executor.send.buffer.size" 1024, "resource.aware.scheduler.priority.strategy" "org.apache.storm.scheduler.resource.strategies.priority.DefaultSchedulingPriorityStrategy", "pacemaker.auth.method" "NONE", "storm.daemon.metrics.reporter.plugins" ["org.apache.storm.daemon.metrics.reporters.JmxPreparableReporter"], "topology.worker.logwriter.childopts" "-Xmx64m", "topology.spout.wait.strategy" "org.apache.storm.spout.SleepSpoutWaitStrategy", "ui.host" "0.0.0.0", "topology.submitter.principal" "", "storm.nimbus.retry.interval.millis" 2000, "nimbus.inbox.jar.expiration.secs" 3600, "dev.zookeeper.path" "/tmp/dev-storm-zookeeper", "topology.acker.executors" nil, "topology.fall.back.on.java.serialization" true, "topology.eventlogger.executors" 0, "supervisor.localizer.cleanup.interval.ms" 600000, "storm.zookeeper.servers" ["localhost"], "nimbus.thrift.threads" 64, "logviewer.cleanup.age.mins" 10080, "topology.worker.childopts" nil, "topology.classpath" nil, "supervisor.monitor.frequency.secs" 3, "nimbus.credential.renewers.freq.secs" 600, "topology.skip.missing.kryo.registrations" true, "drpc.authorizer.acl.filename" "drpc-auth-acl.yaml", "pacemaker.kerberos.users" [], "storm.group.mapping.service.cache.duration.secs" 120, "topology.testing.always.try.serialize" false, "nimbus.monitor.freq.secs" 10, "storm.health.check.timeout.ms" 5000, "supervisor.supervisors" [], "topology.tasks" nil, "topology.bolts.outgoing.overflow.buffer.enable" false, "storm.messaging.netty.socket.backlog" 500, "topology.workers" 1, "pacemaker.base.threads" 10, "storm.local.dir" "C:\\Users\\ADMINI~1\\AppData\\Local\\Temp\\d7cdc68c-f54c-4677-ac0e-d73c3b2effb3", "topology.disable.loadaware" false, "worker.childopts" "-Xmx%HEAP-MEM%m -XX:+PrintGCDetails -Xloggc:artifacts/gc.log -XX:+PrintGCDateStamps -XX:+PrintGCTimeStamps -XX:+UseGCLogFileRotation -XX:NumberOfGCLogFiles=10 -XX:GCLogFileSize=1M -XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=artifacts/heapdump", "storm.auth.simple-white-list.users" [], "topology.disruptor.batch.timeout.millis" 1, "topology.message.timeout.secs" 30, "topology.state.synchronization.timeout.secs" 60, "topology.tuple.serializer" "org.apache.storm.serialization.types.ListDelegateSerializer", "supervisor.supervisors.commands" [], "nimbus.blobstore.expiration.secs" 600, "logviewer.childopts" "-Xmx128m", "topology.environment" nil, "topology.debug" false, "topology.disruptor.batch.size" 100, "storm.messaging.netty.max_retries" 300, "ui.childopts" "-Xmx768m", "storm.network.topography.plugin" "org.apache.storm.networktopography.DefaultRackDNSToSwitchMapping", "storm.zookeeper.session.timeout" 20000, "drpc.childopts" "-Xmx768m", "drpc.http.creds.plugin" "org.apache.storm.security.auth.DefaultHttpCredentialsPlugin", "storm.zookeeper.connection.timeout" 15000, "storm.zookeeper.auth.user" nil, "storm.meta.serialization.delegate" "org.apache.storm.serialization.GzipThriftSerializationDelegate", "topology.max.spout.pending" 1000, "storm.codedistributor.class" "org.apache.storm.codedistributor.LocalFileSystemCodeDistributor", "nimbus.supervisor.timeout.secs" 60, "nimbus.task.timeout.secs" 30, "storm.zookeeper.superACL" nil, "drpc.port" 3772, "pacemaker.max.threads" 50, "storm.zookeeper.retry.intervalceiling.millis" 30000, "nimbus.thrift.port" 6627, "storm.auth.simple-acl.admins" [], "topology.component.cpu.pcore.percent" 10.0, "supervisor.memory.capacity.mb" 3072.0, "storm.nimbus.retry.times" 5, "supervisor.worker.start.timeout.secs" 120, "storm.zookeeper.retry.interval" 1000, "logs.users" nil, "worker.profiler.command" "flight.bash", "transactional.zookeeper.port" nil, "drpc.max_buffer_size" 1048576, "pacemaker.thread.timeout" 10, "task.credentials.poll.secs" 30, "blobstore.superuser" "Administrator", "drpc.https.keystore.type" "JKS", "topology.worker.receiver.thread.count" 1, "topology.state.checkpoint.interval.ms" 1000, "supervisor.slots.ports" [6700 6701 6702 6703], "topology.transfer.buffer.size" 1024, "storm.health.check.dir" "healthchecks", "topology.worker.shared.thread.pool.size" 4, "drpc.authorizer.acl.strict" false, "nimbus.file.copy.expiration.secs" 600, "worker.profiler.childopts" "-XX:+UnlockCommercialFeatures -XX:+FlightRecorder", "topology.executor.receive.buffer.size" 1024, "backpressure.disruptor.low.watermark" 0.4, "topology.users" [], "nimbus.task.launch.secs" 120, "storm.local.mode.zmq" false, "storm.messaging.netty.buffer_size" 5242880, "storm.cluster.state.store" "org.apache.storm.cluster_state.zookeeper_state_factory", "worker.heartbeat.frequency.secs" 1, "storm.log4j2.conf.dir" "log4j2", "ui.http.creds.plugin" "org.apache.storm.security.auth.DefaultHttpCredentialsPlugin", "storm.zookeeper.root" "/storm", "topology.submitter.user" "Administrator", "topology.tick.tuple.freq.secs" nil, "drpc.https.port" -1, "storm.workers.artifacts.dir" "workers-artifacts", "supervisor.blobstore.download.max_retries" 3, "task.refresh.poll.secs" 10, "storm.exhibitor.port" 8080, "task.heartbeat.frequency.secs" 3, "pacemaker.port" 6699, "storm.messaging.netty.max_wait_ms" 1000, "topology.component.resources.offheap.memory.mb" 0.0, "drpc.http.port" 3774, "topology.error.throttle.interval.secs" 10, "storm.messaging.transport" "org.apache.storm.messaging.netty.Context", "storm.messaging.netty.authentication" false, "topology.component.resources.onheap.memory.mb" 128.0, "topology.kryo.factory" "org.apache.storm.serialization.DefaultKryoFactory", "topology.kryo.register" nil, "worker.gc.childopts" "", "nimbus.topology.validator" "org.apache.storm.nimbus.DefaultTopologyValidator", "nimbus.seeds" ["localhost"], "nimbus.queue.size" 100000, "nimbus.cleanup.inbox.freq.secs" 600, "storm.blobstore.replication.factor" 3, "worker.heap.memory.mb" 768, "logviewer.max.sum.worker.logs.size.mb" 4096, "pacemaker.childopts" "-Xmx1024m", "ui.users" nil, "transactional.zookeeper.servers" nil, "supervisor.worker.timeout.secs" 30, "storm.zookeeper.auth.password" nil, "storm.blobstore.acl.validation.enabled" false, "client.blobstore.class" "org.apache.storm.blobstore.NimbusBlobStore", "supervisor.childopts" "-Xmx256m", "topology.worker.max.heap.size.mb" 768.0, "ui.http.x-frame-options" "DENY", "backpressure.disruptor.high.watermark" 0.9, "ui.filter" nil, "ui.header.buffer.bytes" 4096, "topology.min.replication.count" 1, "topology.disruptor.wait.timeout.millis" 1000, "storm.nimbus.retry.intervalceiling.millis" 60000, "topology.trident.batch.emit.interval.millis" 50, "storm.auth.simple-acl.users" [], "drpc.invocations.threads" 64, "java.library.path" "/usr/local/lib:/opt/local/lib:/usr/lib", "ui.port" 8080, "topology.kryo.decorators" [], "storm.id" "StormTopologyAcker-1-1501220593", "topology.name" "StormTopologyAcker", "storm.exhibitor.poll.uripath" "/exhibitor/v1/cluster/list", "storm.messaging.netty.transfer.batch.size" 262144, "logviewer.appender.name" "A1", "nimbus.thrift.max_buffer_size" 1048576, "storm.auth.simple-acl.users.commands" [], "drpc.request.timeout.secs" 600} 35912 [Thread-8] INFO o.a.s.d.worker - Worker 715c933e-5f3a-4a1c-b2f3-b4ace693b7fc for storm StormTopologyAcker-1-1501220593 on a8e2250d-ca68-48bb-bb91-53a2e7ba9080:1024 has finished loading 35913 [Thread-8] INFO o.a.s.config - SET worker-user 715c933e-5f3a-4a1c-b2f3-b4ace693b7fc 36092 [refresh-active-timer] INFO o.a.s.d.worker - All connections are ready for worker a8e2250d-ca68-48bb-bb91-53a2e7ba9080:1024 with id 715c933e-5f3a-4a1c-b2f3-b4ace693b7fc 36199 [Thread-14-MySpout-executor[2 2]] INFO o.a.s.d.executor - Opening spout MySpout:(2) 36206 [Thread-14-MySpout-executor[2 2]] INFO o.a.s.d.executor - Opened spout MySpout:(2) 36211 [Thread-14-MySpout-executor[2 2]] INFO o.a.s.d.executor - Activating spout MySpout:(2) spout:1 36215 [Thread-18-MyBolt-executor[1 1]] INFO o.a.s.d.executor - Preparing bolt MyBolt:(1) 36221 [Thread-18-MyBolt-executor[1 1]] INFO o.a.s.d.executor - Prepared bolt MyBolt:(1) 36315 [Thread-20-__system-executor[-1 -1]] INFO o.a.s.d.executor - Preparing bolt __system:(-1) 36334 [Thread-20-__system-executor[-1 -1]] INFO o.a.s.d.executor - Prepared bolt __system:(-1) 36335 [Thread-16-__acker-executor[3 3]] INFO o.a.s.d.executor - Preparing bolt __acker:(3) 36337 [Thread-16-__acker-executor[3 3]] INFO o.a.s.d.executor - Prepared bolt __acker:(3) sum=1 处理成功!1 spout:2 sum=3 处理成功!2 spout:3 sum=6 处理成功!3 spout:4 sum=10 处理成功!4 spout:5 sum=15 处理成功!5 spout:6 sum=21 处理成功!6 spout:7 sum=28 处理成功!7 spout:8 sum=36 处理成功!8 spout:9 sum=45 处理成功!9 spout:10 sum=55 处理成功!10 spout:11 sum=66 处理成功!11 spout:12 sum=78 处理成功!12 spout:13 sum=91 处理成功!13 spout:14 sum=105 处理成功!14 spout:15 sum=120 处理成功!15 spout:16 sum=136 处理成功!16 spout:17 sum=153 处理成功!17 spout:18 sum=171 处理成功!18 spout:19 sum=190 处理成功!19 spout:20 sum=210 处理成功!20 spout:21 sum=231 处理成功!21 spout:22 sum=253 处理成功!22 spout:23 sum=276 处理成功!23 spout:24 sum=300 处理成功!24 spout:25 sum=325 处理成功!25 spout:26 sum=351 处理成功!26 spout:27 sum=378 处理成功!27 spout:28 sum=406 处理成功!28 spout:29 sum=435 处理成功!29 spout:30 sum=465 处理成功!30 spout:31 sum=496 处理成功!31 spout:32 sum=528 处理成功!32 spout:33 sum=561 处理成功!33 spout:34 sum=595 处理成功!34 spout:35 sum=630 处理成功!35 spout:36 sum=666 处理成功!36 spout:37 sum=703 处理成功!37 spout:38 sum=741 处理成功!38 spout:39 sum=780 处理成功!39 spout:40 sum=820 处理成功!40 spout:41 sum=861 处理成功!41 spout:42 sum=903 处理成功!42 spout:43 sum=946 处理成功!43 spout:44 sum=990 处理成功!44 spout:45 sum=1035 处理成功!45 spout:46 sum=1081 处理成功!46 spout:47 sum=1128 处理成功!47 spout:48 sum=1176 处理成功!48 spout:49 sum=1225 处理成功!49 spout:50 sum=1275 处理成功!50 spout:51 sum=1326 处理成功!51 spout:52 sum=1378 处理成功!52 spout:53 sum=1431 处理成功!53 spout:54 sum=1485 处理成功!54 spout:55 sum=1540 处理成功!55 spout:56 sum=1596 处理成功!56 spout:57 sum=1653