java之扫描包里面的class文件
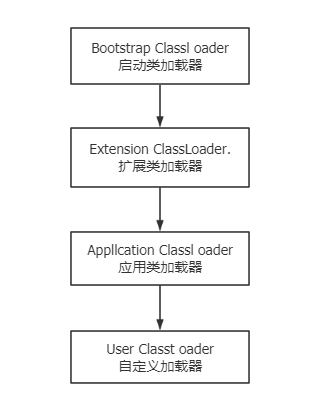
一、class作为,编译过后的产物,在很多时候,我们需要通过反射去执行class的具体方法。但是扫描class就是一个很大的问题了。 二、所以我这里写了一个简单的class文件扫描方式。 三、主要是利用ClassLoader中能够通过包铭去需要目录的绝对路径特性,写的 四、例子: /** * 提供直接调用的方法 * @param packageName * @return * @throws IOException * @throws ClassNotFoundException */ public static List<Class> findClass(String packageName) throws IOException, ClassNotFoundException { return findClass(packageName, new ArrayList<>()); } /** * * @param packageName * @param clazzs * @return * @throws ClassNotFoundException * @throws IOException */ private static List<Class> findClass(String packageName, List<Class> clazzs) throws ClassNotFoundException, IOException { //将报名替换成目录 String fileName = packageName.replaceAll("\\.", "/"); //通过classloader来获取文件列表 File file = new File(Thread.currentThread().getContextClassLoader().getResource(fileName).getFile()); File[] files = file.listFiles(); for (File f:files) { //如果是目录,这进一个寻找 if (f.isDirectory()) { //截取路径最后的文件夹名 String currentPathName = f.getAbsolutePath().substring(f.getAbsolutePath().lastIndexOf(File.separator)+1); //进一步寻找 findClass(packageName+"."+currentPathName, clazzs); } else { //如果是class文件 if (f.getName().endsWith(".class")) { //反射出实例 Class clazz = Thread.currentThread().getContextClassLoader().loadClass(packageName+"."+f.getName().replace(".class","")); clazzs.add(clazz); } } } return clazzs; } 五、测试: public static void main(String[] args) throws IOException, ClassNotFoundException { List<Class> clazzs = findClass("com.pinnet"); System.out.println(clazzs); }