dubbo 入门
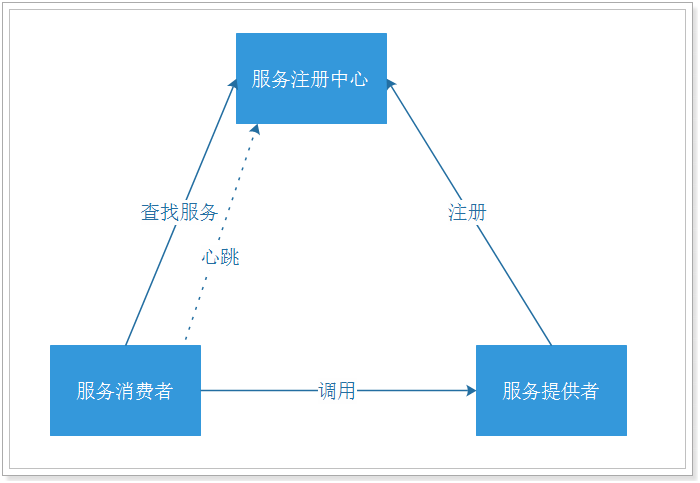
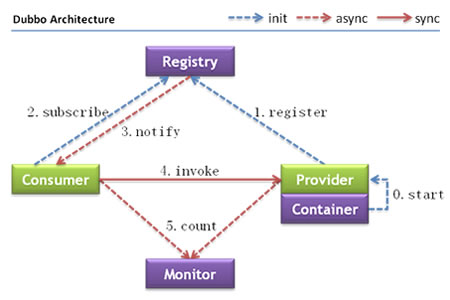
1 介绍 1.1 背景 随着互联网的发展,网站应用的规模不断扩大,常规的垂直应用架构已无法应对,分布式服务架构以及流动计算架构势在必行,亟需一个治理系统确保架构有条不紊的演进。 1.2 说明 DUBBO是一个分布式服务框架,致力于提供高性能和透明化的RPC远程服务调用方案,是阿里巴巴SOA服务化治理方案的核心框架。 1.3 功能 启动时检查、集群容错、负载均衡、线程模型、直连提供者、只订阅、只注册、静态服务、多协议、多注册中心、服务分组、多版本、分组聚合、参数验证、结果缓存、泛化引用、泛化实现、回声测试、上下文信息、隐式传参、异步调用、本地调用、参数回调、事件通知、本地存根、本地伪装、延迟暴露、并发控制、连接控制、延迟连接、粘滞连接、令牌验证、路由规则、配置规则、服务降级、优雅停机、主机绑定、日志适配、访问日志、服务容器、Reference Config缓存、分布式事务 1.4 支持的协议 dubbo rmi http webservice thrift memcached redis 2 环境准备 Java7、Java8 ZooKeeper Maven Tomcat7 Eclipse 3 架构图 节点角色说明及对应demo模块: Provider: 暴露服务的服务提供方。对应dubbo-demo-provider。 Consumer: 调用远程服务的服务消费方。对应dubbo-demo-consumer Registry: 服务注册与发现的注册中心。这个demo使用ZooKeeper,关于ZooKeeper的搭建可参考这篇文章。 Monitor: 统计服务的调用次调和调用时间的监控中心。需要搭建dubbo-admin,对应的war包可从这里下载,也可自行编译运行。 Container: 服务运行容器。使用Tomcat跟Jetty。 我的demo代码:https://github.com/JasperZXY/dubbo-demo 4 开始搭建项目 4.1 说明 下面的代码是在Java8下运行通过的。 4.2 创建maven项目 名称为dubbo-demo,加入需要的jar,这里把各个项目需要的jar包都放入了父pom中,实际项目最好做好分类,如下 <properties> <project.build.sourceEncoding>UTF-8</project.build.sourceEncoding> <junit.version>4.12</junit.version> <spring.version>4.3.8.RELEASE</spring.version> <dubbo.version>2.5.3</dubbo.version> <zookeeper.version>3.4.10</zookeeper.version> <zkclient.version>0.10</zkclient.version> <jackson.version>2.7.4</jackson.version></properties><dependencies> <dependency> <groupId>junit</groupId> <artifactId>junit</artifactId> <version>${junit.version}</version> <scope>test</scope> </dependency> <dependency> <groupId>org.springframework</groupId> <artifactId>spring-webmvc</artifactId> <version>${spring.version}</version> </dependency> <!--SpringMVC集成slf4j-logback--> <dependency> <groupId>ch.qos.logback</groupId> <artifactId>logback-classic</artifactId> <version>1.1.3</version> </dependency> <dependency> <groupId>org.logback-extensions</groupId> <artifactId>logback-ext-spring</artifactId> <version>0.1.2</version> </dependency> <dependency> <groupId>org.slf4j</groupId> <artifactId>jcl-over-slf4j</artifactId> <version>1.7.12</version> </dependency> <dependency> <groupId>com.alibaba</groupId> <artifactId>dubbo</artifactId> <version>${dubbo.version}</version> <exclusions> <exclusion> <!--排除传递spring依赖,防止冲突--> <artifactId>spring</artifactId> <groupId>org.springframework</groupId> </exclusion> </exclusions> </dependency> <!--导入zookeeper依赖--> <dependency> <groupId>org.apache.zookeeper</groupId> <artifactId>zookeeper</artifactId> <version>${zookeeper.version}</version> </dependency> <dependency> <groupId>com.github.sgroschupf</groupId> <artifactId>zkclient</artifactId> <version>0.1</version> </dependency> <dependency> <groupId>org.jboss.netty</groupId> <artifactId>netty</artifactId> <version>3.2.10.Final</version> </dependency> <dependency> <groupId>com.101tec</groupId> <artifactId>zkclient</artifactId> <version>${zkclient.version}</version> </dependency> <!--jackson--> <dependency> <groupId>com.fasterxml.jackson.core</groupId> <artifactId>jackson-databind</artifactId> <version>${jackson.version}</version> </dependency> <dependency> <groupId>com.fasterxml.jackson.core</groupId> <artifactId>jackson-core</artifactId> <version>${jackson.version}</version> </dependency> <dependency> <groupId>com.fasterxml.jackson.core</groupId> <artifactId>jackson-annotations</artifactId> <version>${jackson.version}</version> </dependency></dependencies> 4.3 dubbo-demo-api 这个模块用于定义接口以及交互的实体对象,创建一个User跟UserService publicclassUserimplementsjava.io.Serializable{privatestaticfinallongserialVersionUID=-2218791253527448503L;privateLongid;privateStringusername;privateStringpassword;privateIntegerage;//这里省略了getset方法 @Override publicStringtoString(){return"User[id="+id+",username="+username+",password="+password+",age="+age+"]"; } } publicinterfaceUserService{publicList<User>queryAll(); } 4.4 dubbo-demo-provider 这个模块用于提供服务,是使用main方法直接运行的。 1、需要添加dubbo-demo-api这个依赖,pom.xml如下 <dependency> <groupId>zxy.demo</groupId> <artifactId>dubbo-demo-api</artifactId> <version>${project.parent.version}</version></dependency> 2、UserService的实现 publicclassUserServiceImplimplementsUserService{/***这里通过模拟查询数据库返回用户信息*/ @Override publicList<User>queryAll(){ List<User>list=newArrayList<User>();for(inti=0;i<3;i++){ Randomrandom=newRandom(); Useruser=newUser(); user.setAge(random.nextInt(10)+18); user.setId(Long.valueOf(i+1)); user.setPassword("123456"); user.setUsername("name_"+i); list.add(user); }returnlist; } } 3、Spring配置 <beansxmlns="http://www.springframework.org/schema/beans"xmlns:context="http://www.springframework.org/schema/context"xmlns:p="http://www.springframework.org/schema/p"xmlns:aop="http://www.springframework.org/schema/aop"xmlns:tx="http://www.springframework.org/schema/tx"xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"xmlns:dubbo="http://code.alibabatech.com/schema/dubbo"xsi:schemaLocation="http://www.springframework.org/schema/beanshttp://www.springframework.org/schema/beans/spring-beans-4.0.xsdhttp://www.springframework.org/schema/contexthttp://www.springframework.org/schema/context/spring-context-4.0.xsdhttp://www.springframework.org/schema/aophttp://www.springframework.org/schema/aop/spring-aop-4.0.xsdhttp://www.springframework.org/schema/txhttp://www.springframework.org/schema/tx/spring-tx-4.0.xsdhttp://code.alibabatech.com/schema/dubbohttp://code.alibabatech.com/schema/dubbo/dubbo.xsd"> <!--提供方应用信息,用于计算依赖关系--> <dubbo:applicationname="dubbo-demo-provider"/> <!--这里使用的注册中心是zookeeper--> <dubbo:registryaddress="zookeeper://127.0.0.1:2181"client="zkclient"/> <!--用dubbo协议在20880端口暴露服务--> <dubbo:protocolname="dubbo"port="20880"/> <!--将该接口暴露到dubbo中--> <dubbo:serviceinterface="zxy.demo.dubbo.api.service.UserService"ref="userServiceImpl"/> <!--将具体的实现类加入到Spring容器中--> <beanid="userServiceImpl"class="zxy.demo.dubbo.provider.service.UserServiceImpl"/></beans> 注:如果<dubbo:标签有报错的,可下载一个dubbo.xsd文件(可从我的git上找到),在Eclipse上windows->preferrence->XML->XML Catalog->add->catalog entry->file system,选择刚刚下载的文件路径,修改key值(dubbo.xsd),保存。在xml文件右键validate即可解决。 4、编写启动方法 ublicclassApplication{@SuppressWarnings("resource")publicstaticvoidmain(String[]args)throwsException{ (newClassPathXmlApplicationContext(newString[]{"spring/provider.xml"})).start();//保持main方法不退出 CountDownLatchlatch=newCountDownLatch(1); latch.await(); } } 4.5 dubbo-demo-consumer 这个模块用于调用dubbo-demo-provider提供的服务,使用SpringMVC进行运行。 1、需要添加dubbo-demo-api这个依赖,pom.xml如下 <dependency> <groupId>zxy.demo</groupId> <artifactId>dubbo-demo-api</artifactId> <version>${project.parent.version}</version></dependency> 2、Spring的配置 appContext.xml,主配置文件 <context:component-scanbase-package="zxy.demo.dubbo.consumer"></context:component-scan><importresource="classpath*:spring/dubbo-*.xml"/><importresource="classpath*:spring/springmvc-servlet.xml"/> springmvc-servlet.xml <!--添加注解驱动--><mvc:annotation-driven/><!--返回json支持--><beanid="jsonConverter"class="org.springframework.http.converter.json.MappingJackson2HttpMessageConverter"> <propertyname="supportedMediaTypes"> <list> <value>text/html;charset=UTF-8</value> </list> </property></bean> dubbo-consumer.xml <!--提供方应用信息,用于计算依赖关系--><dubbo:applicationname="dubbo-demo-consumer"/><!--这里使用的注册中心是zookeeper--><dubbo:registryaddress="zookeeper://127.0.0.1:2181"client="zkclient"/><!--从注册中心中查找服务--><dubbo:referenceid="userService"interface="zxy.demo.dubbo.api.service.UserService"/> 3、web.xml <?xmlversion="1.0"encoding="UTF-8"?><web-appversion="3.0"xmlns="http://java.sun.com/xml/ns/javaee"xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"xsi:schemaLocation="http://java.sun.com/xml/ns/javaeehttp://java.sun.com/xml/ns/javaee/web-app_3_0.xsd"> <context-param> <param-name>contextConfigLocation</param-name> <param-value>classpath:spring/appContext.xml</param-value> </context-param> <listener> <listener-class>org.springframework.web.context.ContextLoaderListener</listener-class> </listener> <listener> <listener-class>ch.qos.logback.ext.spring.web.LogbackConfigListener</listener-class> </listener> <servlet> <servlet-name>springmvc</servlet-name> <servlet-class>org.springframework.web.servlet.DispatcherServlet</servlet-class> <init-param> <param-name>contextConfigLocation</param-name> <param-value></param-value> </init-param> <load-on-startup>1</load-on-startup> </servlet> <servlet-mapping> <servlet-name>springmvc</servlet-name> <url-pattern>/</url-pattern> </servlet-mapping> </web-app> 4、controller 调用远程服务并返回前端数据。 @Controller@RequestMapping("/user")publicclassUserController{@Autowired privateUserServiceuserService; @RequestMapping("/list")@ResponseBody publicObjectlistAll(){returnuserService.queryAll(); } } 4.6 运行 先启动ZooKeeper 启动dubbo-demo-provider 启动dubbo-demo-consumer,mvn jetty:run -Djetty.port=8083 访问http://127.0.0.1:8083/user/list获取数据 5 监控 自行编译运行dubbo-admin或从我的git上下载dubbo-admin-2.5.3.war,放入tomcat中运行。默认用的注册中心是zookeeper://127.0.0.1:2181,可修改,在WEB-INF/dubbo.properties中进行修改。 启动后访问http://127.0.0.1:8080/dubbo-admin-2.5.3,如果war包是改名为ROOT.war后运行的,则访问http://127.0.0.1:8080/,输入账号密码(root/root)。 注意,由于现在很多机器都安装了高版本的Java8,运行这个dubbo-admin将导致出错,报错信息为“Bean property 'URIType' is not writable or has an invalid setter method”,详见官方的issues。我自己的解决方法是下载一个低版本的Java,修改tomcat对应的Java版本,找到setclasspath.bat中的set _RUNJAVA,set _RUNJDB这两行,修改如下: set_RUNJAVA="C:\ProgramFiles\Java\jdk1.7.0_80\bin\java.exe"set_RUNJDB="C:\ProgramFiles\Java\jdk1.7.0_80\bin\jdb.exe" 本文转自帅气的头头博客51CTO博客,原文链接http://blog.51cto.com/12902932/1925692如需转载请自行联系原作者 sshpp