因为工作原因,最近一段时间都在做项目的数据建设工作,涉及到使用Pyspider进行数据的爬取及入库,所以此处系统的整理一下;
pyspider简介
一个国人编写的强大的网络爬虫系统并带有强大的WebUI。 采用Python语言编写,分布式架构,支持多种数据库后端,强大的WebUI支持脚本编辑器,任务监视器,项目管理器以及结果查看器。 不过目前对代理支持的话,不太好,只能支持单代理,本身不支持多代理,有两种解决方法:
PySpider特性
- 用Python编写脚本,支持Python 2. {6,7},3。{3,4,5,6}等
- 功能强大的WebUI,包括脚本编辑器,任务监视器,项目管理器和结果查看器
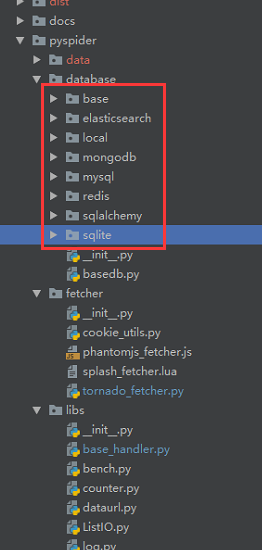
- 支持多种数据库存储(MySQL,MongoDB,Redis,SQLite,Elasticsearch,PostgreSQL,SQLAlchemy)
- 支持多种消息队列(RabbitMQ,Beanstalk,Redis,Kombu)
- 支持爬虫任务优先级设置,超时重爬等
- 支持分布式部署
- 支持抓取Javascript页面
PySpider组件及架构
PySpider核心组件有以下几个:
Scheduler(调度器):
- 从task_queue中接收任务
- 确定任务是新任务还是重爬任务
- 进行优先级排序,
- 处理定期任务,重试丢失或失败的任务
Fetcher(提取器):
- 负责获取网页内容
- 支持url或JavaScript的页面(通过phantomjs)
![通过PhantomJs获取内容]()
Processor(处理器):
组件之间架构图如下:
![]()
每个组件相互独立,通过消息队列连接,从单进程到多机分布式灵活拓展
存储
Pyspider支持多种存储,默认使用的sqlite,具体支持如下图源码中所列
![]()
默认情况下,运行的时候,运行目录的下会生成一个data文件夹,里面会存储几个db文件:
- project.db (存储爬虫项目信息,一般指的一个单独的爬虫脚本)
- result.db (存储任务执行结果信息)
- task.db (存储爬虫任务信息,也就是on_start后生成的爬虫任务信息)
PySpider使用
安装Pyspider
安装的话,比较简单,只有两步:
- pip install pyspider
- 运行命令pyspider,访问http://localhost:5000/
首页介绍
![]()
操作按钮
- Recent Active Tasks (查看最近活动的任务,会跳转到一个页面有列表显示)
- Create (创建一个新的爬虫任务)
项目列表
- group:分组,点击进行修改,用于区分任务类型,可以通过点击表头进行排序,要是能做成文件夹就更好了
- project name:项目名称,创建爬虫项目时填写
- status (任务状态,有以下几种状态)
- TODO:当一个脚本刚刚被创建时的状态
- STOP:你可以设置项目状态为STOP让项目停止运行
- CHECKING:当一个运行中的项目被编辑时项目状态会被自动设置成此状态并停止运行.
- DEBUG/RUNNING:这两状态都会运行爬虫,但是他们之间是有区别的.一般来说调试阶段用DEBUG状态,线上用RUNNING状态.
- rate/burst:rate:每秒执行多少个请求,burst:任务并发数,可以点击进行修改
- avg time:任务平均时间
- progress:记录任务状态,按时间区分,会标示任务的创建数,成功数,失败数等值
- actions:对爬虫项目的一些操作
- Run:立即执行任务,需要status为running或debug状态;如果在配置的调度执行时间内已经执行过,再点run是无效的,需要删除task.db里的数据才行(我都是直接把文件都干掉了。。)
- Active Tasks:查看当前爬虫项目的活动任务
- Results:查看活动任务结果
编辑页面介绍
![]()
-
左侧页面栏为调试信息可视化,相关区域及按钮介绍一下:
- 上面绿色区域,为调试信息显示,显示当前任务的相关信息;
- Run:调试按钮,点击即可运行当前任务
- "<",">"箭头为上一步下一步,用于调试过程中切换到上一步骤
- web:将当前拉取到的页面内容以web形式展示(不过显示范围很窄。。)
- html:显示当前页面的html源码
- follow:子任务,该任务下的子任务,点击链接上的按钮,即可进行下一步调试
- messages,enable css selector helper 这两个还不知道有啥用
-
右侧主要就是用于编写爬虫脚本了,新建默认脚本如下: ![]()
-
核心代码都在BaseHandler中,Handler类继承BaseHandler,该类在base_handler.py文件中
-
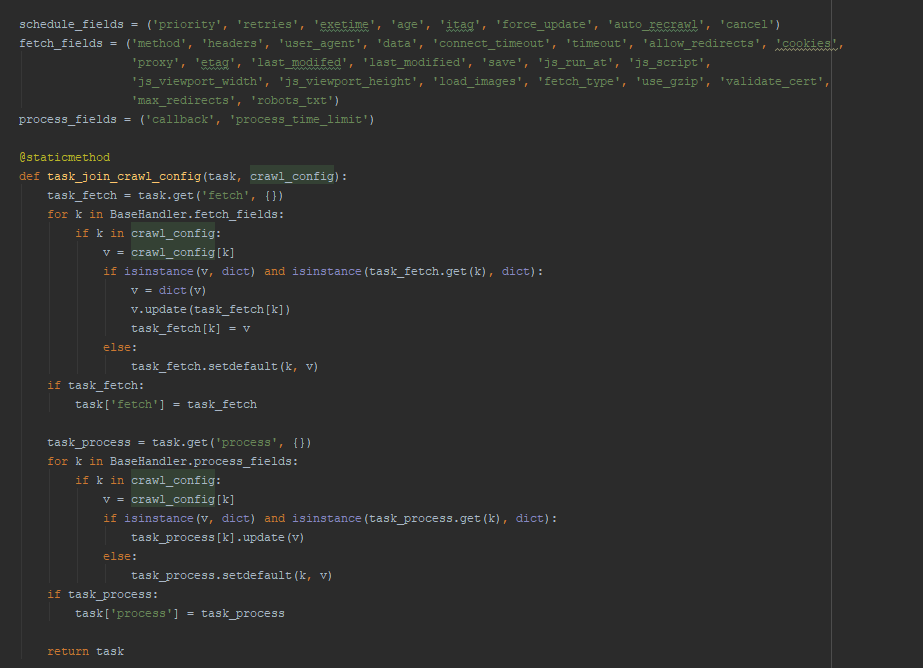
crawl_config :为全局配置对象,通过源码我们可以看到,可以支持很多配置,但是需要注意,配置是有作用区域的
![crawl_config配置属性]()
-
on_start 入口方法:一般为主页面的方法,这名字不能改,因为源码里启动的话入口方法就是on_start,其余index_page,跟detail_page没有说强制性的,可根据自己需求起名字,就不说了; ![]()
-
@every 注解:用于定时调度,有两个参数:minutes,seconds;分别也是代表指的多少分钟执行一次,多少秒执行一次,代码也在base_handler.py中
-
@config 注解:用于核心方法self.crawl的配置,在通过配置的,会作为self.crawl的默认配置;
-
crawl 核心方法:这个方法就是告诉Pyspider抓取哪个页面,我目前为止也没都用全,完整的API点击这里,有很详细的解释
-
Response 返回对象:通过默认的示例代码中可以看到,通过crawl爬取返回的对象就是这个类型,可以通过response.doc方法,将返回值转换成PyQuery对象,剩下来的就根据需求去解析元素,提取你需要的东西了;完整API点击这里
总结:
因为第一次接触爬虫,对别的爬虫技术也不太了解,不好做对比,就PySpider来说,用久了还是方便的,特别是页面调试,不过刚开始用的话,对Response对象不熟悉,会比较麻烦一点,毕竟没有PyCharm通过断点查看对象属性来的方便; 因为整体来讲,比较简单,这里就不上传示例代码了,看编辑页面介绍截图的代码,就是之前爬保监会网站的代码,可以借鉴一下,比较简单。 另吐槽一下开源中国 对MarkDown的支持,在编辑预览中看到的,跟发布出来看到的格式不一样。。难受