java8学习:CompetableFuture组合式异步编程
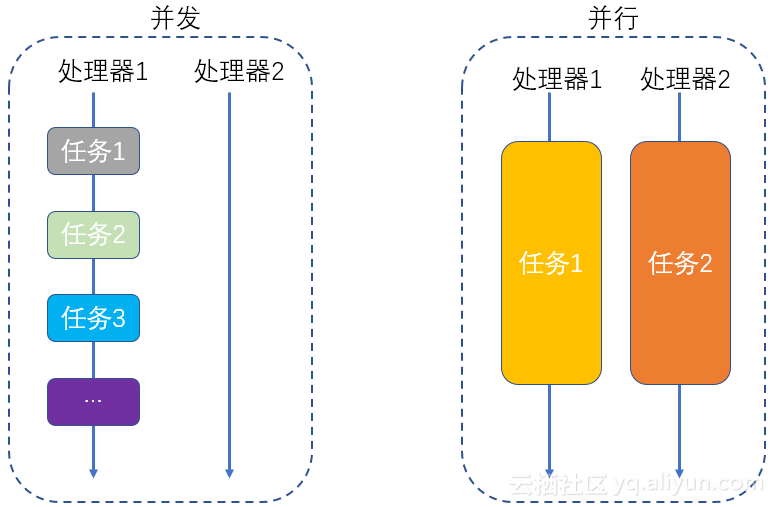
内容来自《 java8实战 》,本篇文章内容均为非盈利,旨为方便自己查询、总结备份、开源分享。如有侵权请告知,马上删除。书籍购买地址:java8实战 如果你的意图是实现并发,而非并行,或者你的主要目标是在同一个CPU上执行集合松耦合的任务,充分利用CPU的核,让其足够忙碌,从而最大化程序的吞吐量,那么你其实真正想做的是避免因为等待远程服务的返回等一些操作而阻塞线程的执行,浪费宝贵的计算资源,因为这种等待的时间可能很长,通过本文就会了解,Future接口,尤其是他的实现:CompletableFuture,是这种情况的处理利器 Future接口 在java5被引入,他是代表一种异步计算,返回一个执行运算结果的引用,当运算结束后,这个引用被返回给调用方.在Future中触发那些潜在耗时的操作把调用线程解放出来,让它能继续执行其他右脚趾的工作,不需要等待耗时操作完成,就比如你去干洗店把衣服交给它,然后你去做其他事情就好,衣服洗好了,自然就会有人给你打电话通知拿衣服了 一个简单的Future以异步的方式执行一个耗时的操作的代码实例 //通过此对象,可以向线程池提交任务 ExecutorService service = Executors.newCachedThreadPool(); //提交任务 Future<Double> task = service.submit(new Callable<Double>() { @Override public Double call() throws Exception { return 7D; } }); try { //获取异步操作的结果,如果被堵塞,那么最多等待一秒之后退出 Double aDouble = task.get(10, TimeUnit.SECONDS); } catch (InterruptedException e) { //当前线程在等待过程中被中断 e.printStackTrace(); } catch (ExecutionException e) { //计算抛出一个异常 e.printStackTrace(); } catch (TimeoutException e) { //超时异常 e.printStackTrace(); } Future的局限性 通过上面的例子,我们知道了Future接口提供了方法来检测一步计算是否已经结束(isDone),等待异步操作结束,以及获取计算的结果,但是这些特性还不足以写出简洁的并发代码,比如我们很难描述两个Future结果之间的依赖性:比如"当A计算完成后,请将A计算的结果通知给B任务,等待两个任务都完成后,请将计算结果与另一个操作结过合并",但是Future代码写起来就又是一回事了,所以我们需要更具描述力的特性,比如 两个计算结果合并为一个 等待所有Future任务完成 仅等待最快的Future任务完成 应对Future完成事件 在我们了解过lambda之后,其实上面的需求我们可以联想到lambda中的解决方法,比如上面的应对Futrue完成时间:如果新的Future实现采用lambda模式编程的话,那么肯定是一个Supplier之类的一个函数式接口,以便将我们的实现进行行为参数化处理,java8中也是这样做的,接下来要说的新的Future实现遵循了类似的模式,使用lambda思想和流水线的思想(Stream). 使用CompletableFuture构建异步应用 首先我们要了解一下相关的概念:同步API和异步API 同步API:你调用了某个方法,调用方在被调用方运行的过程中会进入等待,被调用方运行结束后返回,调用方取得被调用方的返回值并继续运行,即使调用方和被调用方处于不同的线程中运行,调用方还是等待被调用方运行结束结果返回后才能继续往下执行,所以此时同步API是在等待的 异步API:与上面正好相反:即异步API直接返回,或者至少在被调用方结束计算完成之前,把它剩余的计算任务交给另一个线程去做,该线程和调用方是异步的:这就是非阻塞式调用的由来.执行剩余计算任务的线程会将它的计算结果返回给调用方,返回的方式是通过回调函数或者由调用方再次执行一个"等待,直到计算完成"的方法调用 下面我们将要做一个"最佳价格查询器"的应用:他会查询多个在线的商店,依据给定的产品或者服务找出最低价格 实现开始 //这个方法是每个在线商店都需要有的方法:根据商品返回价格 //待实现部分可能会引发延迟较高的操作,比如数据库的查询等 public double getPrice(String product){ //待实现 } 为了演示延迟操作,我们直接线程睡眠一秒好了,如下 public static void delay(){ try { Thread.sleep(1000); } catch (InterruptedException e) { e.printStackTrace(); } } 将上面的getPrice方式实现完整 public double getPrice(String product){ return calculatePrice(product); } private double calculatePrice(String product){ delay(); return Math.random(); } 上面的代码如果调用的话,明显是一个同步操作,你会进入方法并等待一秒,你才会得到你想要的结果,对于这个方法,体验是很差的,所以我们将同步方法转换为异步方法 //将getPrice方法修改 public Future<Double> getPriceAsync(String product){ //创建此对象,此对象包含计算的结果 CompletableFuture<Double> future = new CompletableFuture<>(); //在另一个线程中以异步方式进行计算 new Thread(() -> { double v = calculatePrice(product); //需要长时间计算的任务结束并得到结果时,设置为Future的返回值 future.complete(v); }).start(); //无须等待还没有结束的计算,直接返回future对象 return future; } 返回值Future代表一个异步计算的结果,即Future是一个暂时不知道值的处理器,在这个值处理完成后,可以调用get方法取得. 如上的future.complete(v);,可以使用此方法,结束CompletableFuture的运行,并设置变量的值 使用如上异步API @Test public void test() throws InterruptedException, ExecutionException, TimeoutException { Shop shop = new Shop(); //获取指定商品的价格 Future<Double> produceNameTask = shop.getPriceAsync("produceName"); //其他任何操作,比如异步耗时操作也可以 //如果任务结束了,那么就返回,否则就进入阻塞 Double aDouble = produceNameTask.get(10, TimeUnit.SECONDS); System.out.println("aDouble = " + aDouble); } 如上所提的任何操作,如果是异步的,那么也都是直接返回,然后继续执行上面的代码,当到get的时候,如果任务完成,就返回值,否则get就进入阻塞,但是不超过指定时间 如果在价格计算的过程中产生了错误,那么用于提示错误的异常会被限制到试图计算商品价格的当前线程的范围内,最终会杀死该线程,而这会导致等待get方法返回结果的客户端永久的被阻塞,即get不知道他的异步调用发生错误了,错误被封在了异步调用中,而get还在傻傻等待造成永久的阻塞,当然可以使用get的有时间限制的方法,如果超时就会发生超时异常,但是这样你就不会有机会发现计算价格方法内部发生了什么问题,为了让客户端知道为什么报错,我们需要使用CompletableFuture的completeExceptionally方法将内部错误抛出,如下 错误处理 我们可以制造一个除零错误.如下 public Future<Double> getPriceAsync(String product){ CompletableFuture<Double> future = new CompletableFuture<>(); new Thread(() -> { double v = calculatePrice(product); //如果正常结束,那么就设置值并返回 int i = 1 / 0 ; //异常发生 future.complete(v); }).start(); return future; } 然后我们继续执行上面的test测试方法,执行结果如下,并且程序终止 Exception in thread "Thread-0" java.lang.ArithmeticException: / by zero at com.qidai.demotest.Shop.lambda$getPriceAsync$0(Shop.java:12) at java.lang.Thread.run(Thread.java:748) //这里会等待get方法设置的时长 java.util.concurrent.TimeoutException at java.util.concurrent.CompletableFuture.timedGet(CompletableFuture.java:1771) at java.util.concurrent.CompletableFuture.get(CompletableFuture.java:1915) at com.qidai.demotest.MyTest.test(MyTest.java:18) at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method) at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62) ... 修改shop的getPriceAsync()方法的实现 public Future<Double> getPriceAsync(String product){ CompletableFuture<Double> future = new CompletableFuture<>(); new Thread(() -> { try { double v = calculatePrice(product); //如果正常结束,那么就设置值并返回 int i = 1 / 0 ; future.complete(v); }catch (Exception e){ future.completeExceptionally(e); //告诉Future发生异常了,直接返回 } }).start(); return future; } 控制台测试结果如下 java.util.concurrent.ExecutionException: java.lang.ArithmeticException: / by zero at java.util.concurrent.CompletableFuture.reportGet(CompletableFuture.java:357) at java.util.concurrent.CompletableFuture.get(CompletableFuture.java:1915) at com.qidai.demotest.MyTest.test(MyTest.java:18) at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method) at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62) at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43) at java.lang.reflect.Method.invoke(Method.java:498) ... 详细的堆栈信息,并且不会像上面一样get一直在堵塞,而是遇到错误立刻返回 Caused by: java.lang.ArithmeticException: / by zero at com.qidai.demotest.Shop.lambda$getPriceAsync$0(Shop.java:13) at java.lang.Thread.run(Thread.java:748) 使用工厂方法创建CompletableFuture对象 之前创建了CompletableFuture对象了,但是有简单的工厂方法可以直接创建此对象,如下使用supplyAsync创建对象 public Future<Double> getPriceAsync(String product){ return CompletableFuture.supplyAsync(() -> calculatePrice(product)); } 上面方法是对之前的方法的改造,方法实现更加简单,supplyAsync接收一个supplier参数,返回一个CompletableFuture对象,该对象完成异步执行后读取调用生产者方法的返回值,生产者方法会交由ForkJoinPool中的某个线程去执行,上面的方法与之前的方法实现完全等价,并且已经实现了错误管理 CompletableFuture正确姿势 下面我们将假设只提供了同步的API,以及一个商家列表,如下 public class Shop { private String name ; public Shop(String name) { this.name = name; } //同步 public Double getPrice(String product){ return calculatePrice(product); } private double calculatePrice(String product){ delay(); return Math.random(); } public static void delay(){ try { Thread.sleep(1000); } catch (InterruptedException e) { e.printStackTrace(); } } public String getName() { return name; } } //商家列表 List<Shop> shops = Arrays.asList(new Shop("A"),new Shop("B") ,new Shop("C"),new Shop("D") ,new Shop("E"),new Shop("F") ,new Shop("G"),new Shop("H")); 我们还需要一个方法:它接受产品名为参数,返回一个字符串列表,字符串为商品名+商品价格 public List<String> findPrice(String product){} //这个方法将在顺序查询,并行查询和异步查询中实现不同逻辑 顺序方式查询实现 public List<String> findPrice(String product){ return shops.stream().map(shop -> shop.getName() + shop.getPrice(product)) .collect(Collectors.toList()); } 顺序方式查询验证时间和结果 public void test(){ long l1 = System.nanoTime(); List<String> list = findPrice("huawei"); long l2 = System.nanoTime(); System.out.println("done = " + (l2 - l1)); } //以后的并行查询和异步查询都将才用这个方法验证时间和结果 顺序方式查询结果:done = 8063808400,不出意外是八秒多,因为每个方法都是顺序执行的,并且每个方法都睡眠了一秒钟,然后加上执行时间,八秒多很正常 下面我们将使用并行流来实现findPrice方法 public List<String> findPrice(String product){ return shops.parallelStream().map(shop -> shop.getName() + shop.getPrice(product)) .collect(Collectors.toList()); } //仅仅是将stream 换为 parallelStream 并行流查询结果:done = 1068473800,因为我的机子是八核的,并且并行流默认的线程数就是你机子的核数,所以八个shop是同时进行处理的,所以时间耗费是一秒多 使用CompletableFuture实现 public List<CompletableFuture<String>> findPrice(String product){ return shops.stream().map(shop -> CompletableFuture.supplyAsync( () -> shop.getName() + shop.getPrice(product))) .collect(Collectors.toList()); } 注意上面方法,你会得到一个List>,列表中的每个CompletableFuture对象在计算完成后都包含商店的String类型的名称,但是由于用CompletableFuture实现的findPrice需要返回一个List,你就必须要等到所有Future执行完,将其包含的值抽取出来才能够返回 为了实现上面说的等待效果,我们有一个方法可以实现:join,CompletableFuture中的join与Future中的get有相同的含义,并且也生命在Future接口中,唯一的不同就是join不会抛出异常,对List中的CompletableFuture执行join操作,一个接一个等待他们运行结束,如下 public List<String> findPrice(String product){ List<CompletableFuture<String>> collect = shops.stream() .map(shop -> CompletableFuture.supplyAsync(() -> shop.getName() + shop.getPrice(product))) .collect(Collectors.toList()); return collect.stream().map(CompletableFuture::join).collect(Collectors.toList()); } 上面操作使用了两个Stream,而不是在一个Stream进行两次map,这是因为考虑流操作之间的延迟特性,如果你在单一流水线中处理流,发出不同商家的请求就只能同步,顺序执行的方式才会成功,因此每个创建CompletableFuture对象只能在前一个操作结束之后执行查询指定商家的动作,通知join方法返回计算结果,也就是说,在第一个map中得到了一个CompletableFuture对象,再次调用map进行join操作的话,那么流就只能在这等待CompletableFuture完成操作才会继续执行,自己测试的双map情况下执行时间为:8080624000 异步方式的执行时间为:done = 2060340600 到这我们还是有些失望的,因为异步方式是并行流执行时间的将近两倍了,那么我们应该怎么改进这个现象呢? 并行流非常快,单这只是对于之前的测试,如果我们增加一个shop,那么又会是什么结果呢? 顺序流:done = 9064012900,毫不意外就是九秒多 并行流:done = 2063944500,因为shop个数大于机器核数了,所以他会多出一个shop,它一直在等待某个shop执行完毕让出线程然后自己去执行,所以是两秒多 异步:done = 2070337400,与并行流,看起来差不多的时间,原因是跟并行流是一样的,因为他们默认都是以机器核数个数为默认线程池的大小的,机器核数可以通过Runtime.getRuntime().availableProcessors()得到,然而CompletableFuture具有一定的优势,因为它可以允许你对执行器Executor进行配置,尤其是线程池的大小,让它跟能适应需求 定制Executor 这里就设计到了线程的大小,因为从上面我们就能看出线程个数对程序的执行带来的影响 有一个可以参考的公式:线程数=处理器核数 * 期望CPU利用率 * 等待时间与计算时间的比率,我们上面的异步方式基本都是等待shop的计算方法返回结果,所以这里等待时间与计算时间的比率估算为100,如果利用率也为100,那么我的机器将要创建800个线程,但是对于上面的shop数量,这显然太多了,我们最后的就是跟shop数量一致,这样就可以一个线程分担一个shop的处理任务,在实际操作中,如果shop数量可能太多,就必须有一个线程个数的上限,以确保机器不会崩溃 定制执行器 Executor executor = Executors.newFixedThreadPool(Math.min(shops.size(), 100), new ThreadFactory() { @Override public Thread newThread(Runnable r) { Thread thread = new Thread(r); //使用守护线程---这种方式不会阻止程序的关停 thread.setDaemon(true); return thread; } }); 如上是一个由守护线程构成的线程池,当一个普通线程在执行时,java程序无法终止或者退出,所以最后剩下的那个线程会由于一直等待无法发生的时间而引发问题,但是切换为守护线程就以为这程序退出时他会被回收,这两种线程性能上没什么差异,现在创建好了线程池,可以在异步方法中使用了,比如 public List<String> findPrice(String product){ List<CompletableFuture<String>> collect = shops.stream() .map(shop -> CompletableFuture.supplyAsync(() -> shop.getName() + shop.getPrice(product),executor)) //注意参数变化 .collect(Collectors.toList()); return collect.stream().map(CompletableFuture::join).collect(Collectors.toList()); } 时间为:done = 1064816300 并行和异步的选择 上面我们看到并行的性能意思不错的,那么我们应该如何选择呢? 如果是计算密集型的操作,没有IO,那么就推荐并行Stream 如果涉及到IO或者网络连接等,那么就推荐CompletableFuture 异步程序的流水线操作 上面中我们是用的CompletableFuture都是单次操作,到这将开始接受多个异步操作结合在一起是如何使用的 现在假设shop支持了一个折扣服务,服务折扣分为五个折扣力度,并用枚举类型变量代表 public class Discount { public enum Code{ //无 银 金 铂金 钻石 NONE(0),SILVER(5),GOLD(10),PLATINUM(15),DIAMOND(20); //百分比 private final int percentage; Code(int percentage) { this.percentage = percentage; } } } 我们还假设所有的商店都以相同的格式返回数据,如:ShopName:price:Discount格式返回 //修改getPrice方法 public String getPrice(String product){ Random random = new Random(); Discount.Code code = Discount.Code.values()[random.nextInt(Discount.Code.values().length)]; return this.name + ":" + calculatePrice(product) + ":" + code; } 以上方法调用会返回类似字符串:A:0.3771404561328807:SILVER 我们还需要一个Quote类,该类可以将上面getPrice方法返回的String解析,并保存在类中,如下 public class Quote { private final String shopName; private final double price; private final Discount.Code discountCode; public Quote(String shopName, double price, Discount.Code discountCode) { this.shopName = shopName; this.price = price; this.discountCode = discountCode; } //解析shop.getPrice()方法返回的String public static Quote parse(String shopMes){ String[] split = shopMes.split(":"); String shopName = split[0]; double price = Double.parseDouble(split[0]); Discount.Code code = Discount.Code.valueOf(split[2]); return new Quote(shopName,price,code); } public String getShopName() { return shopName; } public double getPrice() { return price; } public Discount.Code getDiscountCode() { return discountCode; } } 同时我们还需要在之前的Discount类中加入两个方法,如下 public class Discount { public enum Code{ ...//上面有实现 } public static String applyDiscount(Quote quote){ //将商品的原始价格和折扣力度传入,返回一个新价格 return quote.getShopName()+" price = " + Discount.apply(quote.getPrice(),quote.getDiscountCode()); } private static String apply(double price, Code discountCode) { delay(); //模拟服务响应的延迟 //新价格 return (price * (100 - discountCode.percentage) / 100) + ""; } private static void delay(){ try { Thread.sleep(1000); } catch (InterruptedException e) { e.printStackTrace(); } } } 到这总算是把需要的代码写完了,然后下面我们来使用这个Discount 使用Discount 首先尝试以最直接的方式重新实现findPrice方法 public List<String> findPrice(String product){ return shops.stream().map(shop -> shop.getPrice(product)) //根据商品名得到商品信息:ShopName:price:Discount .map(Quote::parse) //根据商品信息,将信息封装到Quote返回 .map(Discount::applyDiscount) //将Quote传入,并根据原始价格和折扣力度获取最新价格,返回shopName+newPrice .collect(Collectors.toList()); //收集到List中 } 执行结果 18175537800 huawei = [A price = 0.45873472420610784, B price = 0.055878368162042856, C price = 0.27810347563879867, D price = 0.3630003460659669, E price = 0.7504524049696628, F price = 0.2958088360956538, G price = 0.19074919381044, H price = 0.5328477712597838, I price = 0.10705723386858104] 如上我们足足运行了18秒,我们现在能想到的优化措施就是使用并行流,采用之后的运行时长为:4077169100,但是我们根据之前的测试知道,这里在shop数量增多的时候并不适合采用并行,因为他底层的线程池是固定的,而是采用CompletableFuture更好 下面我们采用CompletableFuture实现异步操作 public List<String> findPrice(String product){ List<CompletableFuture<String>> priceFutures = shops.stream() //以异步方式取得每个shop中指定产品的原始价格 .map(shop -> CompletableFuture.supplyAsync(() -> shop.getPrice(product),executor)) //在quote对象存在的时候,对其返回的值进行转换 .map(future -> future.thenApply(Quote::parse)) //使用另一个异步任务构造期望的Future,申请折扣 .map(future -> future.thenCompose(quote -> CompletableFuture.supplyAsync(() -> Discount.applyDiscount(quote),executor))) .collect(Collectors.toList()); return priceFutures.stream() //等待所有Future结束,并收集到List中 .map(CompletableFuture::join).collect(Collectors.toList()); } 执行结果 2092351201 huawei = [A price = 0.32805686340328877, B price = 0.12371667853268178, C price = 0.019271284007279683, D price = 0.4014063161769382, E price = 0.457890861738724, F price = 0.12642987715813725, G price = 0.28084441232801843, H price = 0.07957054370541786, I price = 0.48027669847733084] 步骤解毒! 获取价格:使用supplyAsync方法就可以一步的对shop进行查询,第一个转换的结果是Stream>,一旦运行结束,每个CompletableFuture对象中都会包含对应的shop返回的字符串,执行器还是之前的执行器 解析报价:将shop返回的String进行解析,由于解析不需要远程操作,所以这里并没有采用异步的方式进行处理,并且值得注意的是,thenApply方法并不会阻塞代码的执行(thenApply是同步方法,还有一个thenApplyAsync异步方法),而是类似Stream中的中间操作一样,只有当CompletableFuture最终结束运行时,你希望传递lambda给thenApply方法,将Stream中的CompletableFuture转换为CompletableFuture 为计算折扣后的价钱构造Future:因为第三步map中设计到了一个远程操作,我们用睡眠来模拟的,调用supplyAsync代表一个异步操作,这时候我们已经调用了两次Future操作,我们希望可以将这俩次Future操作进行串接起来一起工作:从shop中获取价格,然后将它转换为quote,拿到返回的quote后,将其作为参数再传入Discount,取得最后的折扣价格,thenCompose方法就允许对两个异步操作进行流水线,第一个操作完成时,将其结果作为参数传递给第二个操作.即你可以创建两个CompletableFuture对象,对第一个CompletableFuture对象调用thenCompose,并向其传递一个函数.当第一个CompletableFuture执行完毕后,他的结果将作为该函数的的参数,这个函数的返回值是以第一个CompletableFuture的返回做输入计算出的第二个CompletableFuture对象. 之后就是等待CompletableFuture全部结束然后收集到List中返回即可 看到这我自己是有些蒙的,因为对于CompletableFuture的方法的使用不是很熟悉就更不用谈理解了,这时候我去了解了一下CompletableFuture的方法的使用,大家如果跟我一样,可以去看看<> 将两个不相干的CompletableFuture结合起来 如果你看过了我提到的CompletableFuture方法使用这篇api使用,那么这就很容易了 需求:将一个返回int的和一个返回String的CompletableFuture结果结合在一起 public void test() { CompletableFuture<String> stringCompletableFuture = CompletableFuture.supplyAsync(() -> 1) //返回int .thenCombine( CompletableFuture.supplyAsync(() -> "2"), //返回string (i, s) -> i + s //int和string的组合逻辑 ); String join = stringCompletableFuture.join(); System.out.println(join); //12 } 响应CompletableFuture的completion时间 我们之前的应用都是用延迟一秒来模拟网络延迟的,但是真实场景中,网络延迟不尽相同,可能会立刻返回,或者延迟到超时...,所以我们更改一下之前的模拟网络延迟的方法delay为randomDelay private static void randomDelay(){ try { Thread.sleep(300+ RANDOM.nextInt(2000)); } catch (InterruptedException e) { e.printStackTrace(); } } 他随机返回时间代表不同的网络延迟 之前的findPrice方法都是收集到List中,这样的弊端是必须等到所有的CompletableFuture执行完成后才能够返回,我们现在来优化他 现在我们知道了执行慢的主要原因在于收集到List中,因为他会join等待,所以我们希望findPrice方法直接接受Stream就好了,这样接收流,就不用收集到List中 public Stream<CompletableFuture<String>> findPrice(String product){ return shops.stream() //以异步方式取得每个shop中指定产品的原始价格 .map(shop -> CompletableFuture.supplyAsync(() -> shop.getPrice(product),executor)) //在quote对象存在的时候,对其返回的值进行转换 .map(future -> future.thenApply(Quote::parse)) //使用另一个异步任务构造期望的Future,申请折扣 .map(future -> future.thenCompose(quote -> CompletableFuture.supplyAsync(() -> Discount.applyDiscount(quote),executor))); } 上面的代码就实现了返回一个Stream供我们处理的功能,下面我们来使用这个方法 public void test(){ CompletableFuture[] huawei = findPrice("huawei").map(f -> f.thenAccept(System.out::println)) .toArray(size -> new CompletableFuture[size]); CompletableFuture.allOf(huawei).join(); long l2 = System.nanoTime(); } 如上findPrice方法传入需要查找的product,他会返回一个Stream<CompletableFuture<String>>,然后对流进行map操作,传入的是每一个CompletableFuture(String = producName+打折后的price),thenAccept之前已经说过,传入一个参数,无返回,但是map需要有返回值,其实thenAccept返回的是一个CompletableFuture<Void>类型,所以map就会返回一个Stream<CompletableFuture<Void>>,我们目前希望做的是等待他结束,返回商家信息,但是我们之前的randomDelay方法是随机时间睡眠的,所以难免会有一些慢的商家,不管慢不慢,我们都需要等到商家返回价格,这时候我们可以把Stream中的所有CompletableFuture放到一个数组中,等待所有的任务执行完成 allof方法接收一个由CompletableFuture组成的数组,数组中所有的CompletableFuture对象执行完之后,他会返回一个CompletableFuture<Void>对象,我们调用join方法,等待这个对象执行结束 输出结果 A price = 0.6960491237085883 C price = 0.11038794177308586 F price = 0.16672807719726013 D price = 0.004004621568001343 E price = 0.19972626299549148 B price = 0.9778330750902723 I price = 0.29346736062034645 H price = 0.37760535718363003 G price = 0.3492986178179131 观察输出过程,是一条条输出的,这也展示了网络延迟的效果 上面的allof是等待所有任务结束,而anyof是等待任一一个任务结束,如果我们访问两个地址,两个地址只不过是快慢的问题,而返回的结果都相同的时候,我们就可以使用anyof