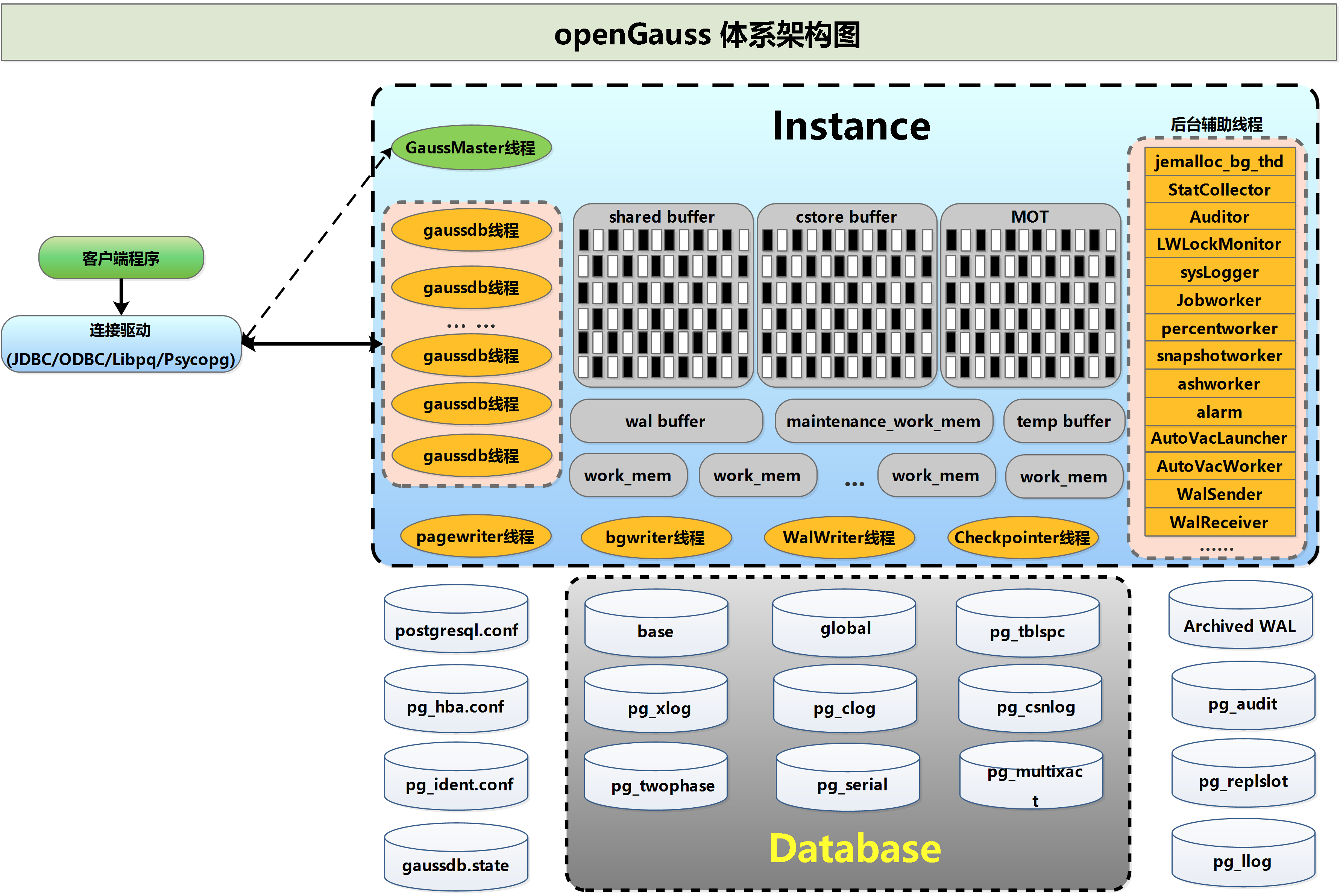
【参赛作品9】openGauss在docker上的安装,连接以及java连接
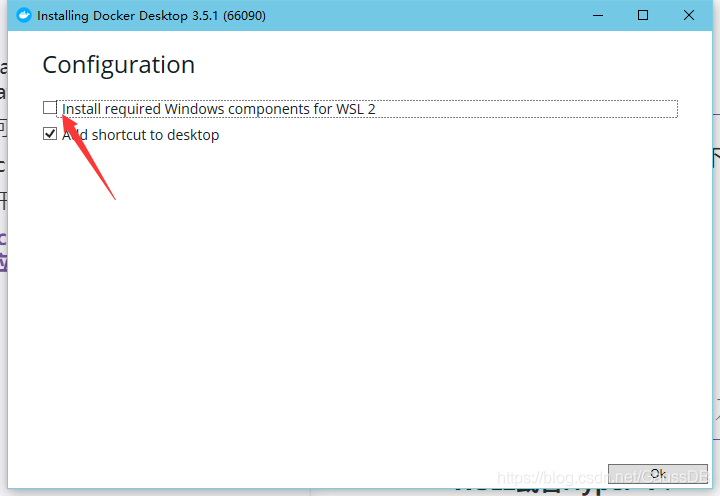
一、openguass的安装 1. 如何快速简洁地安装openguass 安装opengauss的方式在我已知范围内有两种,一种是在虚拟机上安装centos(其实我感觉是个linux就行,但是我也没试过)然后在使用openguass的镜像进行手动安装。第二种是直接在docker上拉取镜像即可。从上面的描述中,第一种方法看上去很复杂实际上也很复杂,所以我都是使用第二种方法的。 你要问这两种安装方式有什么不同吗?在我使用的范围内我感觉是没有什么不同的,主要是安装简单和方便 那我们来看看怎么安装吧 2. docker下载 点击这个链接就可以开始下载docker了:docker下载 在安装之前需要确保系统开启了虚拟服务,不过默认好像都是开启的 3.开始安装docker 开始安装,如果你是win10专业版的话红色箭头的地方就不用√了,如果不是一定要√,点击OK就可以开始安装了,安装结束后会进行一次重启 安装完成,然后开始启动docker: 进入到docker当中我们会看到这样一个界面(我可能是之前安装过了,很顺利,如果有遇到问题的小伙伴,可以看看解决方案) 专业版的小伙伴们注意一下啊,进入这个界面之后点击设置按钮, 然后查看这个是否被打开,如果被打开了,记得一定要关掉,不然你的内存就会被占用得特别多,如果是家庭版就没得选择这个必须开 ! 在设置界面中点击1的位置,然后将下面这段代码复制到2的框中(这是一个换源过程,能够帮你在装Openguass的时候下载快一些) { "registry-mirrors": [ "http://docker.mirrors.ustc.edu.cn", "http://hub-mirror.c.163.com", "http://registry.docker-cn.com" ], "insecure-registries": [ "docker.mirrors.ustc.edu.cn", "registry.docker-cn.com" ] } 点击Apply&Restart按钮,等待docker重启即可 4. docker安装可能存在的问题以及对应的解决方案 WSL2或者Hyper-V: 可能存在说咱们他不开docker需要安装wsl2。 首先要确定的是,我们的windows10版本是不是专业版,如果是专业版,无论他说使用wsl2有更好的体验,不要管他,使用hyper-v,直接选hyper-v,其他都不要管。 如果是家庭版,那就只能装wsl2了,他会给出一个连接,安装对应的补丁,然后直接装就行了 这两个都是是虚拟机的启动器,wsl2相当于启动了一个子linux系统,会特别吃内存2~4G左右,因此如果是专业版享受hyper-v或者内存够大的话,那就可以别看下面的部分了 因为wls2吃内存很大所以需要对其限制内存,但是如果限制得太小的话他就无法启动docker了,经过我在多次不同电脑上安装的经验,大概给wsl2限制在1.5G左右,就能正常启动。当然我也试过限制在500M,1G的内存,这些对于一部分电脑是有用的,但是对于大部分的电脑现在在1.5G左右是比较合适的,大家可以在看完下面限制内存的方法后自己调一下,到底要限制多大才能正常启动。 WSL2内存限制: 先打开控制台输入:wsl --shutdown确保wsl2服务关闭,不管有没有启动这个服务都先关了 首先按下Windows + R键,输入 %UserProfile%,然后回车。会弹出一个文件夹,在文件夹下创建.wslconfig文件,然后使用记事本打开 在文件中输入如下内容 [wsl2] memory=1500MB swap=2G processors=1 其中对应的内容信息是: memory=1500MB # 限制最大使用内存 swap=2G # 限制最大使用虚拟内存 processors=1 # 限制最大使用cpu个数 虚拟内存好像影响不大,不过觉得不合适的话也是可以改的,在memory上就要进行改动了,具体设置多少需要自己进行试验 5. 拉取openguass镜像 重启结束后,点击键盘上的开始按钮,输入powershell,回车,输入指令,下面指定了对应的版本,1.0.1也算是一个稳定版本,因为如果使用最新版本他可能比较不稳定会出现su: Authentication failure 的情况,这个目前的解决方案就是不是用latest标签的最新版本而是使用1.0.1的版本。 docker pull enmotech/opengauss:1.0.1 等待openguass镜像下载 opengauss的安装,需要使用Openguass的镜像,在镜像中内置了超级用户omm以及测试用户guassdb,因此在安装时,需要给他们设置密码, openGauss的密码有复杂度要求,需要:密码长度8个字符及以上,必须同时包含英文字母大小写,数字,以及特殊符号 比如密码2222@aaaA 在安装是默认端口号为5432,但是如果想要在外部链接的话需要修改端口号, 执行下面的语句,在中文的地方改成对应的内容即可,我这里修改的端口号改为了15432 docker run --name opengauss --privileged=true -d -e GS_PASSWORD=(这里是你的密码) -p 15432(端口号):5432 enmotech/opengauss:1.0.1 安装完成: 回到docker主界面,我们会看到有一个Openguass的选项,如下图: ! 当1处的位置为灰色说明当前openguass服务尚未启动,点击2处的按钮可以开始启动 当1处图标变绿说明服务启动成功,点击2处的按钮进入控制台模式 其实只要看到上图的界面我们就算安装成功了,不过保险起见,我们可以使用su - omm指令进入超级用户的模式,然后使用指令gsql打开openguass看看能不能正常使用(这个控制台是一个微型的linux控制台,输入密码的时候看不到输入情况,所以放心输入,输入正确了回车就行) 安装成功,如果忘记里密码可以点这里绿色图标旁边的文字,然后点击INSPECT openguass的密码就保存再这里,同时还有一些必要的信息 当我们不需要使用openguass数据库的时候可以点击这个按钮将其关闭,当需要使用时向之前说的那样开启就可以了,记住只有docker里的这个图标变绿了才能使用可视化工具连接openguass数据库 6. 确认opengauss可用 二、opengauss数据库的可视化链接 可视化工具其实是可以随便选的,比如jetbrains的datagrip还有Navicat等等 不过后面要演示java链接数据库,因此我决定使用jetbrains的idea作为数据库的可视化工具 疑问:啊?idea不是用来写java的么?还能用来数据库可视化? 答:可以的,如果是idea旗舰版在里面是有一个类似于datagrip的插件的 疑问:那idea旗舰版怎么得 答:可以通过学校邮箱在jetabrains官网上注册一个账号并使用学校邮箱申请一年使用期,只要你还在学校一天,你就能一直续下去,获取流程会在这里说明一下(当然,如果使用navicat的话可以跳过获取正版jetbrains的说明部分,直接看连接部分) 1. 获取旗舰版的idea 首先进入jetbrains的官网,并进行账号注册 注册好帐号后,进行登录,回到主页,主页的右上角可以切换成中文,如图进行点击学习工具->学生和教师 点击立即申请 按照对应的条件填写如下表格 然后申请免费产品,申请后会给你的学校邮箱发一个邮件,进入邮件点击他提供的连接,你的帐号就能获得一年的许可证,这时候你在官网下载正版的专业版,下载安装好后,他要你激活软件的时候,选择登录自己的帐号,就可以使用专业版了。 不过,记得把之前装过的盗版全部清理干净不然会激活失败的。 2. 使用idea的数据库可视化工具插件连接数据库 回归正题,怎么用idea进行数据库连接呢?其实和大部分的可视化工具是一样的 首先打开我们opengauss的虚拟机或着docker 我们先创建一个java项目,然后看到他的右边有一个database 点击一下,因为我之前连过一个了,可能会不太一样点开后按照顺序点击 界面如下,在箭头所指的地方有一个要下载的插件,但是我下过了,所以没有了,记得点击下载。 按照顺序依次填入: 自己openguass的ip地址,这个如果是跟着我上面的步骤安装就是用localhost或者127.0.0.1就可以了 自己openguass的端口号,这个如果是跟着我上面的步骤安装就是15432 填gaussdb不管你创建的时候起的什么名字都填gaussdb(gaussdb是docker安装时的内置测试用户,权限很高) 填自己设置的密码(就是自己设置的密码了,如果你连密码都跟我一样就是2222@aaaA) 点击测试一下连接 如果成功了会有这样的结果 ! 点击应用,和ok就可以连接了,逐级点开选项就可以看到,自己的表格模式信息了,右键我图中的test 三、java链接openguass数据库 右键数据库图标的test,new->Query Console就可以进入sql语句的编写界面了。 然后是用java连接数据库,首先要下载一个jar包,如果是jdk8以上的版本,可以点击这个连接下载https://jdbc.postgresql.org/download/postgresql-42.2.20.jar 不是的话需要到postgresql的官网寻找合适的jar 下载好后放到我们能找到的位置 然后右键我们的工程文件名 点击Open Module Setting->dependencies 点击+号,点击jar or derectiories,找到之前下载的jar包,添加进去,然后打个勾,就可以了 最后长这样就行,记住一定要是自己的工程目录下,点错了就没有用的。 代码的话,随便建个java文件,写个主类,然后写下面的代码就行,都有注释的,使用idea的时候如果下面代码有报错,就点击alt + 回车他会自动帮你补错 Connection c = null; Statement stmt = null; try { // 获取数据库源,固定写法 Class.forName("org.postgresql.Driver"); // 这个是连接,该一下中文的部分,就是之前你用database连数据库的那些参数 c = DriverManager .getConnection("jdbc:postgresql://你的IP地址:你的端口号/要连接的数据库", "gaussdb", "高斯数据库的密码"); // 连接成功 System.out.println("Opened database successfully"); // 这里创建一个类似于可视化工具中的console的那个脚本文件 stmt = c.createStatement(); // 这里写sql语句,做创建表的演示 String sql = "CREATE TABLE COMPANY1 " + "(ID INT PRIMARY KEY NOT NULL," + " NAME TEXT NOT NULL, " + " AGE INT NOT NULL, " + " ADDRESS CHAR(50), " + " SALARY REAL)"; // String sql = "DROP TABLE COMPANY"; stmt.executeUpdate(sql); // 关闭脚本文件 stmt.close(); // 结束连接 c.close(); } catch ( Exception e ) { System.err.println( e.getClass().getName()+": "+ e.getMessage() ); System.exit(0); } System.out.println("Table created successfully"); } 展示一下运行结果: 这是运行前数据库的内容,我们执行上面的代码后会创建一个表company1的表 结果如下: 写sql语句的地方是可以换成任何一个sql语句的 四、最后说一个小问题 重新装了个数据库现在没法展示了,但是我记得问题,就是当前sql语句中所有的表都报错,他最有可能的是没有选对模式 点击database旁边的xxx.,点击对应的数据然后选择自己的表所在的模式, 选择好后,点OK就可以了。 Gauss松鼠会是汇集数据库爱好者和关注者的大本营, 大家共同学习、探索、分享数据库前沿知识和技术, 互助解决问题,共建数据库技术交流圈。 openGauss官网