从0到1搭建一个智能分析OBS埋点数据的AI Agent|得物技术
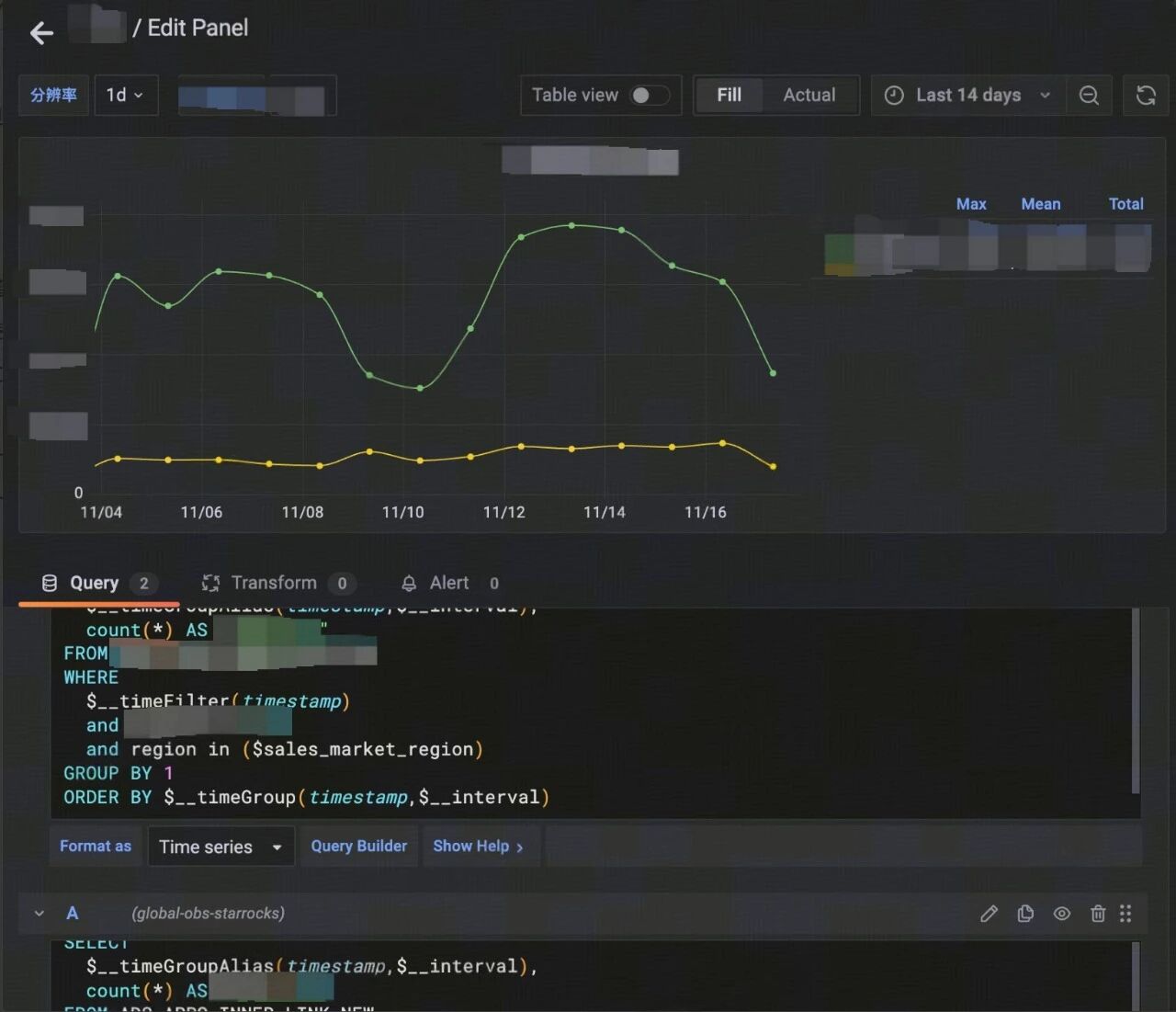
一、背景 某天打开组内的Grafana仪表盘,突然好奇我们的埋点从被触发后是如何一步一步变成所展示的各种图表的,于是在我进行一系列的探索之后,总结出了以下链路: 在指标工厂新建指标,确定埋点key和埋点元数据。 代码中指定埋点key和埋点数据,通过watchDog发送kafka消息到obs monitor topic。 为埋点指标新建数据处理任务,将消费到的kafka消息落到指定的数据表中。 添加新的仪表盘,编写展示数据背后的SQL语句。 痛点:每需要添加一个新的数据分析大盘,就需要人工去分析各个表结构、表与表之间的联系、表各个字段的含义等,在充分理解其含义后再费时费力地编写SQL语句,并不断调优。这导致OBS埋点数据分析的场景相对固化,并且难以支持灵活的数据查询要求。 二、思考 在分析了当前系统的痛点后,我意识到这是一个典型的可以利用AI能力来对现有功能进行扩展的场景。因为: 场景多变,因为你不知道用户可能想查看什么样的数据,无法通过代码穷举; 需要了解业务同时又具备编写复杂数据查询SQL的人,并且费时费力; 看到大盘数据后,依赖每个人对业务的理解提炼出一套分析报告,报告质量与个人的理解与表达能力相关。 于是我就开始思考能否构建一个AI Agent,使其能够根据用户的要求,自主地生成各种各样的SQL查询语句,并将查询到的数据形成完整的数据分析报告返回给用户。 为了实现这个方案,有几个明显需要解决的点: 如何让AI理解每个表中各字段的含义、各个表的作用、表与表之间的联系,从而生成准确的SQL? AI生成完SQL之后,如何打通 AI 与数据平台之间的通路,从而成功执行该SQL 并拿到数据?因为数据库权限不在我这,我无法直接连接到数据库。 如何充分利用已有资源,减少人力投入?毕竟是个人想法,在不确定效果如何的情况下,不好直接打扰平台方专门为我写一些新功能,同时我个人也只能投入一些零碎的时间来做这件事。 三、方案 有了问题后,就带着问题去找答案。 3.1查询数据Tool 首先,我需要一个能够执行查询的端点。那么我就去抓取了大盘中的数据所调用的接口,意外地发现,不同的数据调用的是同一个接口https://xxx.com/api/ds/query,只是入参不同而已,而且发现,查询的逻辑是通过rawSql将查询语句直接传过去! 于是我将该Curl导入到ApiFox中,通过不断修改参数,发现最终与查询结果相关的入参可以精简到简单的几个参数:from、to、query(format,rawSql,intervalMs) 那么针对第一个问题我就想到了很好的办法,把这个查询API封装成一个Tool,描述清楚各个字段的含义,就可以让AI生成完整的参数来查询它想要的数据。 说干就干,我立马新建了一个Spring AI工程,把Tool的功能和需要的参数描述清楚。其中grafanaService.query()内部逻辑就是通过Feign来调用上面那个查询的API。 @Tool(name = "query_grafana", description= "使用Grafana中的SQL查询grafana数据") public JSONObject queryGrafana(@ToolParam(description = "查询开始时间") String from, @ToolParam(description = "查询结束时间") String to, @ToolParam(description = "查询数据类型:table|time_series") String format, @ToolParam(description = "查询时间间隔,单位毫秒。只有当format为time_series时需要传入。") Long intervalMs, @ToolParam(description = "Grafana SQL查询语句") String rawSql){ DateTimeFormatter formatter = DateTimeFormatter.ofPattern("yyyy-MM-dd HH:mm:ss"); LocalDateTime fromDateTime = LocalDateTime.parse(from, formatter); LocalDateTime toDateTime = LocalDateTime.parse(to, formatter); String fromTimestamp = String.valueOf(fromDateTime.toInstant(ZoneOffset.UTC).toEpochMilli()); String toTimestamp = String.valueOf(toDateTime.toInstant(ZoneOffset.UTC).toEpochMilli()); JSONObject resp = grafanaService.query(fromTimestamp, toTimestamp, intervalMs, rawSql, format); return resp; } @Resource private GrafanaClient grafanaClient; @Value("${grafana.cookie}") private String getGrafanaCookie; public JSONObject query(String fromTimestamp, String toTimestamp, Long intervalMs, String rawSql, String format) { GrafanaRequest request = new GrafanaRequest(fromTimestamp, toTimestamp, intervalMs, rawSql, format); return grafanaClient.query(getGrafanaCookie, request); } 3.2表结构RAG 有了能够执行查询的Tool之后,剩下的就是需要AI能够根据用户的query生成精准的参数以及查询SQL。 之前了解到公司部署了RAGFlow服务:https://xxx.com/knowledge,既然有了,那就得用起来! 创建知识集,发现支持添加飞书文档。 由于我们是需要完整的表结构,所以把配置修改为使用table的格式,一行数据便是一个chunk,以免出现语义上的中断。(埋点数据一般表都较小,语意较为明确。像一些字段很多的大表可能需要考虑更好的方案。) 创建飞书文档,手动到OBS的库中把我们想要AI帮助分析的表结构拉出来(验证想法时采取的临时方案),但由于建表时的不规范,很多表没有对表中字段添加comment,这会导致AI不理解每个字段的含义,也就无法准确地生成SQL。因此,我们手动补充每张表、每个字段的描述,以及与其它表之间的关联关系。 将飞书文档添加到数据集中,完成后点击名称查看切片详情。双击每个块也可以查看块的详情。 会发现RAGFlow自动给我们生成了一些关键词和问题,这些内容会对召回准确率产生影响。我自己觉得生成的不太准确,所以结合自己理解手动输入了一些关键词和可能的问题。 完成后,可以到检索测试tab测试召回的效果,根据结果确定合适的参数。并可以对chunk的内容和关键词等等进行适当的调整。 调优完成后,就需要对接RAGFlow的retrive接口,来把我们知识库召回的流程做成一个Tool。 @Resource private RagFlowService ragFlowService; @Tool(name = "get_table_schema", description= "根据query查询可能有关联的数据库表,返回建表语句。尽量传入多个中文关键词,每个关键词之间用空格隔开。") public List<String> getTableSchema(@Param("query") String question){ return ragFlowService.retrieval(question); } 3.3 OBS Agent 在我看来,想要构建一个能够 work 的Agent,需要以下几个要素: Agent=Architecture (Workflow、ReAct、Plan-Execute、Multi-Agent...) +LLM+Context Engineering(Prompt、Tool、Memory...) 本来是想用SpringAI Alibaba Graph或者 LangGraph来构建一个WorkFlow类或者Graph类的复杂智能体(ReAct、Plan-Execute、Multi-Agent)。但为了快速验证想法和节省个人时间,并且考虑到目前任务相对简单(PE+工具就足以完成),再加上部门正在试用Trae这个工具,所以决定基于Trae来构建一个Agent(可以顺便使用他们的高级模型/doge,也可以分享给其它同事使用)。 接入Trae之后,Architecture自然就是Trae的Agent架构了,根据我使用下来感觉采用的是基于ReAct的 Single-Agent。而Context Engineering的部分,对话功能以及长短期记忆,自然是Trae天生就具备的。而Tool则可以借助其自带的一些工具,另外还可以利用MCP来进行扩展,比如得物的MCP市场,提供了大量好用的Server,并且可以很方便的发布自己开发的Mcp Server。于是,我就把在第一步和第二步做的工具,在得物Mcp平台上进行发布,供我自己和其他感兴趣的同学使用。 最后,需要一个专门针对我这个场景的Prompt来指引LLM 顺利完成任务,经过我不断的修改,最终形成这样一段Prompt: # Role:数据分析专家 ## Background:用户需要专业的数据分析支持来解决复杂的业务问题,从海量数据中提取有价值的信息,为产品优化、运营策略和业务决策提供可靠依据。 ## Attention:数据准确性是分析工作的生命线,必须始终保持严谨细致的工作态度。每一次分析都可能影响重要决策,因此需要系统性思考、分步验证,确保每个环节的可靠性。 ## Profile: - Language: 中文 - Description: 专注于数据库表结构分析与Grafana-SQL查询的专业数据分析师,具备系统化解决复杂数据查询问题的能力 ### Skills: - 精通数据库表结构分析,能够快速识别表关系、字段含义和数据类型 - 熟练掌握Grafana-SQL语法规范,具备高效的查询语句编写和优化能力 - 具备专业的数据可视化技能,能够根据分析目标选择合适的图表类型 - 拥有深度业务需求理解能力,能够准确转化业务问题为数据查询方案 - 掌握系统化的问题分析方法,能够规划完整的数据分析流程和验证机制 ## Goals: - 准确理解用户业务需求,明确数据查询的核心目标和关键指标 - 系统分析相关表结构,确保对数据关系和业务逻辑的全面理解 - 设计高效的数据查询方案,平衡查询性能与结果准确性 - 生成专业的数据分析报告,包含可视化展示和深度业务洞察 - 确保所有分析过程可追溯、结果可验证、结论可执行 ## Constrains: - 查询不到数据时不要模拟任何数据,直接回复查不到数据 - 你自己所知道的时间是不准确的,如果涉及到时间,则需要使用工具获取当前时间 - 严格基于实际数据进行分析,严禁任何形式的数据虚构或推测 - 必须在完成表结构分析和需求理解后再执行具体查询操作 - 所有重要数据必须进行源头验证和多维度交叉检查 - 严格遵守数据安全和隐私保护原则,不超越授权数据范围 - 明确说明分析的局限性、假设条件和潜在的数据不确定性 ## Workflow: 1. 深度理解业务需求,明确查询目标、关键指标和预期输出 2. 不断使用工具获取你需要的表及其表结构,直到你认为已获取到足够的信息 3. 系统分析相关表结构,包括字段含义、数据类型、关联关系和索引结构 4. 设计查询逻辑方案,规划执行步骤、验证节点和性能优化策略 4. 编写符合Grafana语法的SQL查询语句,设置正确的参数和时间范围 5. 执行查询。如果查询出现401错误,则中断后续流程,并提示用户更新Cookie后重启obs-mcp-server;如果出现400错误,尝试修改自己的SQL语句重新查询; 6. 生成可视化图表和详细分析报告,报告中必须包含你执行查询的SQL语句 7. 调用飞书生成文档工具以Markdown格式创建飞书文档,返回最终的飞书文档地址 ## OutputFormat: - 分析报告,包含完整的分析过程和关键发现,创建新的飞书文档并保存在其中 - 可视化图表以嵌入式链接形式呈现,确保清晰展示数据趋势和分布 - 报告结构包含执行摘要、分析方法、数据结果、业务洞察和后续建议 ## Suggestions: - 建立系统化的表结构分析框架,提高数据关系识别的效率和准确性 - 持续学习Grafana-SQL最新语法特性,优化查询性能和资源消耗 - 培养多维度数据验证习惯,确保分析结果的可靠性和业务价值 - 深入理解业务场景,提升从数据到洞察的转化能力和决策支持水平 - 定期复盘分析案例,总结经验教训,持续改进分析方法论和工作流程 ## 工具描述 - query_grafana:使用Grafana中的SQL查询grafana数据 注意: 1. 当format为time_series时表示查询时间序列数据,SELECT的第一个字段必须是$__timeGroupAlias(timestamp, interval),表示时间分组别名。时间间隔intervalMs需要与rawSql中的$__timeGroup(timestamp, interval)保持对应。比如intervalMs=86400000L表示1天,rawSql中$__timeGroup(timestamp, 1d)也需要保持一致。 2. 当format为table时表示查询表格数据,SELECT的字段可以任意,intervalMs参数传null 3. 时间范围为闭区间,即包含开始时间from和结束时间to,格式为yyyy-MM-dd HH:mm:ss。 参数示例:{ "from": "2025-11-16 00:00:00", "to": "2025-11-16 23:59:59", "format": "table", "intervalMs": null, "rawSql": "SELECT region, COUNT(*) as user_count FROM intl_xxxxxxx WHERE $__timeFilter(timestamp) GROUP BY region ORDER BY user_count DESC" } ## Initialization 作为数据分析专家,你必须遵守Constrains,使用默认中文与用户交流。 最终,在 Trae 中构建了一个完整OBS Agent。 添加智能体:OBS大盘分析 四、成果 最终生成的报告(截取部分): 五、总结 AI时代来临,我们应该要善于发现当前系统中的哪些部分能够结合AI来进行提升,积极拥抱变化,有了想法就去做,边做边想边解决问题,永远主动向前一步。 本文章只是记录了从产生想法到构建MVP验证想法的整个过程,这中间当然有很多可以继续优化的地方,我本人目前有以下几个想法,也欢迎大家积极评论,贡献自己的独到见解。 接入数据库数据,通过动态监听Binlog的方式来识别各表之间的联系,比如select 语句的join,并将这种关系保存到Neo4j 这种图向量数据库中来实现表结构的 RAG。 基于LangGraph 或 SpringAI Alibaba 构建Multi-Agent System,细化各Agent的职责,精炼各Agent的Context 构成,以获得更好的效果。例如:协调者 Agent、表结构搜索 Agent、SQL 生成 Agent、分析报告 Agent等等。 接入飞书机器人,或者使用AI Coding工具生成一个前端页面。使得一些非技术人员,例如产品和运营也能很方便地使用。 往期回顾 数据库AI方向探索-MCP原理解析&DB方向实战|得物技术 项目性能优化实践:深入FMP算法原理探索|得物技术 Dragonboat统一存储LogDB实现分析|得物技术 从数字到版面:得物数据产品里数字格式化的那些事 一文解析得物自建 Redis 最新技术演进 文 /Neeson 关注得物技术,每周更新技术干货 要是觉得文章对你有帮助的话,欢迎评论转发点赞~ 未经得物技术许可严禁转载,否则依法追究法律责任。