【SpringCloud技术专题】「Hystrix」(9)熔断器的原理和实现机制
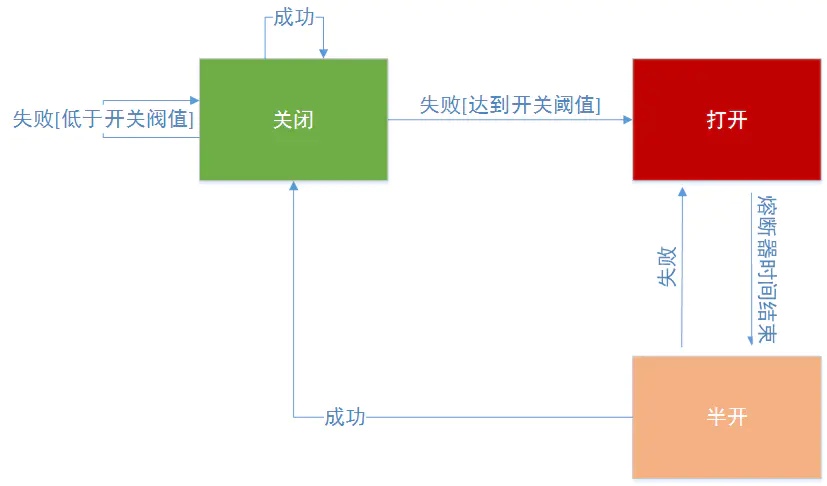
熔断器(Circuit Breaker)介绍 熔断器,现实生活中有一个很好的类比,就是家庭电路中都会安装一个保险盒,当电流过大的时候保险盒里面的保险丝会自动断掉,来保护家里的各种电器及电路。 Hystrix中的熔断器(Circuit Breaker)也是起到这样的作用,Hystrix在运行过程中会向每个commandKey对应的熔断器报告成功、失败、超时和拒绝的状态,熔断器维护计算统计的数据,根据这些统计的信息来确定熔断器是否打开。 如果打开,后续的请求都会被截断。然后会隔一段时间默认是5s,尝试半开,放入一部分流量请求进来,相当于对依赖服务进行一次健康检查,如果恢复,熔断器关闭,随后完全恢复调用。 如下图: 说明,上面说的commandKey,就是在初始化的时候设置的andCommandKey(HystrixCommandKey.Factory.asKey("testCommandKey")) 再来看下熔断器在整个Hystrix流程图中的位置,从步骤4开始,如下图: Hystrix会检查Circuit Breaker的状态。如果Circuit Breaker的状态为开启状态,Hystrix将不会执行对应指令,而是直接进入失败处理状态(图中8 Fallback)。 如果Circuit Breaker的状态为关闭状态,Hystrix会继续进行线程池、任务队列、信号量的检查(图中5) 如何使用熔断器(Circuit Breaker) 由于Hystrix是一个容错框架,因此我们在使用的时候,要达到熔断的目的只需配置一些参数就可以了。但我们要达到真正的效果,就必须要了解这些参数。Circuit Breaker一共包括如下6个参数。 circuitBreaker.enabled:是否启用熔断器,默认是TRUE。 circuitBreaker.forceOpen:熔断器强制打开,始终保持打开状态。默认值FLASE。 circuitBreaker.forceClosed:熔断器强制关闭,始终保持关闭状态。默认值FLASE。 circuitBreaker.errorThresholdPercentage:设定错误百分比,默认值50%,例如一段时间(10s)内有100个请求,其中有55个超时或者异常返回了,那么这段时间内的错误百分比是55%,大于了默认值50%,这种情况下触发熔断器-打开。 circuitBreaker.requestVolumeThreshold:默认值20。意思是至少有20个请求才进行errorThresholdPercentage错误百分比计算。比如一段时间(10s)内有19个请求全部失败了。错误百分比是100%,但熔断器不会打开,因为requestVolumeThreshold的值是20. 这个参数非常重要,熔断器是否打开首先要满足这个条件,源代码如下 // check if we are past the statisticalWindowVolumeThreshold if (health.getTotalRequests() < properties.circuitBreakerRequestVolumeThreshold().get()) { // we are not past the minimum volume threshold for the statisticalWindow so we'll return false immediately and not calculate anything return false; } if (health.getErrorPercentage() < properties.circuitBreakerErrorThresholdPercentage().get()) { return false; } circuitBreaker.sleepWindowInMilliseconds 半开试探休眠时间,默认值5000ms。当熔断器开启一段时间之后比如5000ms,会尝试放过去一部分流量进行试探,确定依赖服务是否恢复。 package myHystrix.threadpool; import com.netflix.hystrix.*; import org.junit.Test; import java.util.Random; /** * Created by wangxindong on 2017/8/15. */ public class GetOrderCircuitBreakerCommand extends HystrixCommand<String> { public GetOrderCircuitBreakerCommand(String name){ super(Setter.withGroupKey(HystrixCommandGroupKey.Factory.asKey("ThreadPoolTestGroup")) .andCommandKey(HystrixCommandKey.Factory.asKey("testCommandKey")) .andThreadPoolKey(HystrixThreadPoolKey.Factory.asKey(name)) .andCommandPropertiesDefaults( HystrixCommandProperties.Setter() .withCircuitBreakerEnabled(true)//默认是true,本例中为了展现该参数 .withCircuitBreakerForceOpen(false)//默认是false,本例中为了展现该参数 .withCircuitBreakerForceClosed(false)//默认是false,本例中为了展现该参数 .withCircuitBreakerErrorThresholdPercentage(5)//(1)错误百分比超过5% .withCircuitBreakerRequestVolumeThreshold(10)//(2)10s以内调用次数10次,同时满足(1)(2)熔断器打开 .withCircuitBreakerSleepWindowInMilliseconds(5000)//隔5s之后,熔断器会尝试半开(关闭),重新放进来请求 // .withExecutionTimeoutInMilliseconds(1000) ) .andThreadPoolPropertiesDefaults( HystrixThreadPoolProperties.Setter() .withMaxQueueSize(10) //配置队列大小 .withCoreSize(2) // 配置线程池里的线程数 ) ); } @Override protected String run() throws Exception { Random rand = new Random(); //模拟错误百分比(方式比较粗鲁但可以证明问题) if(1==rand.nextInt(2)){ // System.out.println("make exception"); throw new Exception("make exception"); } return "running: "; } @Override protected String getFallback() { // System.out.println("FAILBACK"); return "fallback: "; } public static class UnitTest{ @Test public void testCircuitBreaker() throws Exception{ for(int i=0;i<25;i++){ Thread.sleep(500); HystrixCommand<String> command = new GetOrderCircuitBreakerCommand("testCircuitBreaker"); String result = command.execute(); //本例子中从第11次,熔断器开始打开 System.out.println("call times:"+(i+1)+" result:"+result +" isCircuitBreakerOpen: "+command.isCircuitBreakerOpen()); //本例子中5s以后,熔断器尝试关闭,放开新的请求进来 } } } } 测试结果: call times:1 result:fallback: isCircuitBreakerOpen: false call times:2 result:running: isCircuitBreakerOpen: false call times:3 result:running: isCircuitBreakerOpen: false call times:4 result:fallback: isCircuitBreakerOpen: false call times:5 result:running: isCircuitBreakerOpen: false call times:6 result:fallback: isCircuitBreakerOpen: false call times:7 result:fallback: isCircuitBreakerOpen: false call times:8 result:fallback: isCircuitBreakerOpen: false call times:9 result:fallback: isCircuitBreakerOpen: false call times:10 result:fallback: isCircuitBreakerOpen: false 熔断器打开 call times:11 result:fallback: isCircuitBreakerOpen: true call times:12 result:fallback: isCircuitBreakerOpen: true call times:13 result:fallback: isCircuitBreakerOpen: true call times:14 result:fallback: isCircuitBreakerOpen: true call times:15 result:fallback: isCircuitBreakerOpen: true call times:16 result:fallback: isCircuitBreakerOpen: true call times:17 result:fallback: isCircuitBreakerOpen: true call times:18 result:fallback: isCircuitBreakerOpen: true call times:19 result:fallback: isCircuitBreakerOpen: true call times:20 result:fallback: isCircuitBreakerOpen: true 5s后熔断器关闭 call times:21 result:running: isCircuitBreakerOpen: false call times:22 result:running: isCircuitBreakerOpen: false call times:23 result:fallback: isCircuitBreakerOpen: false call times:24 result:running: isCircuitBreakerOpen: false call times:25 result:running: isCircuitBreakerOpen: false 熔断器(Circuit Breaker)源代码HystrixCircuitBreaker.java分析 Factory 是一个工厂类,提供HystrixCircuitBreaker实例 public static class Factory { //用一个ConcurrentHashMap来保存HystrixCircuitBreaker对象 private static ConcurrentHashMap<String, HystrixCircuitBreaker> circuitBreakersByCommand = new ConcurrentHashMap<String, HystrixCircuitBreaker>(); //Hystrix首先会检查ConcurrentHashMap中有没有对应的缓存的断路器,如果有的话直接返回。如果没有的话就会新创建一个HystrixCircuitBreaker实例,将其添加到缓存中并且返回 public static HystrixCircuitBreaker getInstance(HystrixCommandKey key, HystrixCommandGroupKey group, HystrixCommandProperties properties, HystrixCommandMetrics metrics) { HystrixCircuitBreaker previouslyCached = circuitBreakersByCommand.get(key.name()); if (previouslyCached != null) { return previouslyCached; } HystrixCircuitBreaker cbForCommand = circuitBreakersByCommand.putIfAbsent(key.name(), new HystrixCircuitBreakerImpl(key, group, properties, metrics)); if (cbForCommand == null) { return circuitBreakersByCommand.get(key.name()); } else { return cbForCommand; } } public static HystrixCircuitBreaker getInstance(HystrixCommandKey key) { return circuitBreakersByCommand.get(key.name()); } static void reset() { circuitBreakersByCommand.clear(); } } // HystrixCircuitBreakerImpl是HystrixCircuitBreaker的实现,allowRequest()、isOpen()、markSuccess()都会在HystrixCircuitBreakerImpl有默认的实现。 static class HystrixCircuitBreakerImpl implements HystrixCircuitBreaker { private final HystrixCommandProperties properties; private final HystrixCommandMetrics metrics; /* 变量circuitOpen来代表断路器的状态,默认是关闭 */ private AtomicBoolean circuitOpen = new AtomicBoolean(false); /* 变量circuitOpenedOrLastTestedTime记录着断路恢复计时器的初始时间,用于Open状态向Close状态的转换 */ private AtomicLong circuitOpenedOrLastTestedTime = new AtomicLong(); protected HystrixCircuitBreakerImpl(HystrixCommandKey key, HystrixCommandGroupKey commandGroup, HystrixCommandProperties properties, HystrixCommandMetrics metrics) { this.properties = properties; this.metrics = metrics; } /*用于关闭熔断器并重置统计数据*/ public void markSuccess() { if (circuitOpen.get()) { if (circuitOpen.compareAndSet(true, false)) { //win the thread race to reset metrics //Unsubscribe from the current stream to reset the health counts stream. This only affects the health counts view, //and all other metric consumers are unaffected by the reset metrics.resetStream(); } } } @Override public boolean allowRequest() { //是否设置强制开启 if (properties.circuitBreakerForceOpen().get()) { return false; } if (properties.circuitBreakerForceClosed().get()) {//是否设置强制关闭 isOpen(); // properties have asked us to ignore errors so we will ignore the results of isOpen and just allow all traffic through return true; } return !isOpen() || allowSingleTest(); } public boolean allowSingleTest() { long timeCircuitOpenedOrWasLastTested = circuitOpenedOrLastTestedTime.get(); //获取熔断恢复计时器记录的初始时间circuitOpenedOrLastTestedTime,然后判断以下两个条件是否同时满足: // 1) 熔断器的状态为开启状态(circuitOpen.get() == true) // 2) 当前时间与计时器初始时间之差大于计时器阈值circuitBreakerSleepWindowInMilliseconds(默认为 5 秒) //如果同时满足的话,表示可以从Open状态向Close状态转换。Hystrix会通过CAS操作将circuitOpenedOrLastTestedTime设为当前时间,并返回true。如果不同时满足,返回false,代表熔断器关闭或者计时器时间未到。 if (circuitOpen.get() && System.currentTimeMillis() > timeCircuitOpenedOrWasLastTested + properties.circuitBreakerSleepWindowInMilliseconds().get()) { // We push the 'circuitOpenedTime' ahead by 'sleepWindow' since we have allowed one request to try. // If it succeeds the circuit will be closed, otherwise another singleTest will be allowed at the end of the 'sleepWindow'. if (circuitOpenedOrLastTestedTime.compareAndSet(timeCircuitOpenedOrWasLastTested, System.currentTimeMillis())) { // if this returns true that means we set the time so we'll return true to allow the singleTest // if it returned false it means another thread raced us and allowed the singleTest before we did return true; } } return false; } @Override public boolean isOpen() { if (circuitOpen.get()) {//获取断路器的状态 // if we're open we immediately return true and don't bother attempting to 'close' ourself as that is left to allowSingleTest and a subsequent successful test to close return true; } // Metrics数据中获取HealthCounts对象 HealthCounts health = metrics.getHealthCounts(); // 检查对应的请求总数(totalCount)是否小于属性中的请求容量阈值circuitBreakerRequestVolumeThreshold,默认20,如果是的话表示熔断器可以保持关闭状态,返回false if (health.getTotalRequests() < properties.circuitBreakerRequestVolumeThreshold().get()) { return false; } //不满足请求总数条件,就再检查错误比率(errorPercentage)是否小于属性中的错误百分比阈值(circuitBreakerErrorThresholdPercentage,默认 50),如果是的话表示断路器可以保持关闭状态,返回 false if (health.getErrorPercentage() < properties.circuitBreakerErrorThresholdPercentage().get()) { return false; } else { // 如果超过阈值,Hystrix会判定服务的某些地方出现了问题,因此通过CAS操作将断路器设为开启状态,并记录此时的系统时间作为定时器初始时间,最后返回 true if (circuitOpen.compareAndSet(false, true)) { circuitOpenedOrLastTestedTime.set(System.currentTimeMillis()); return true; } else { return true; } } } } 总结 每个熔断器默认维护10个bucket,每秒一个bucket,每个blucket记录成功,失败,超时,拒绝的状态,默认错误超过50%且10秒内超过20个请求进行中断拦截。下图显示HystrixCommand或HystrixObservableCommand如何与HystrixCircuitBreaker及其逻辑和决策流程进行交互,包括计数器在断路器中的行为。