在Java中使用redisTemplate操作缓存
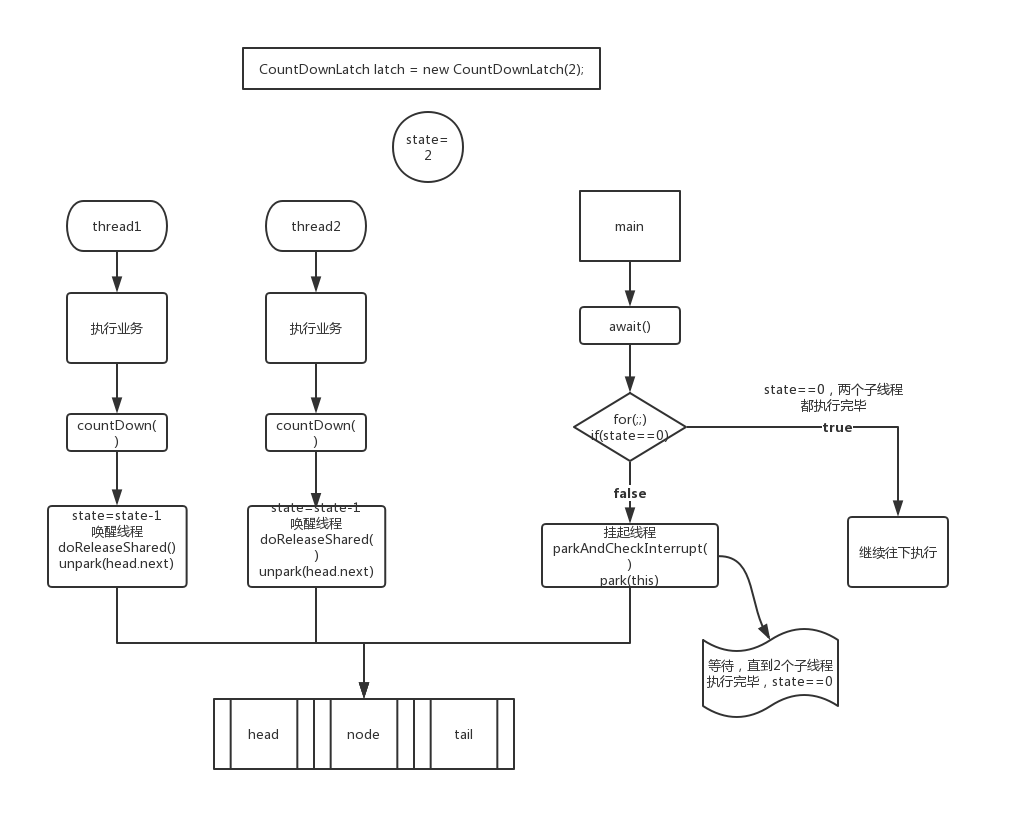
背景 在最近的项目中,有一个需求是对一个很大的数据库进行查询,数据量大概在几千万条。但同时对查询速度的要求也比较高。 这个数据库之前在没有使用Presto的情况下,使用的是Hive,使用Hive进行一个简单的查询,速度可能在几分钟。当然几分钟也并不完全是跑SQL的时间,这里面包含发请求,查询数据并且返回数据的时间的总和。但是即使这样,这样的速度明显不能满足交互式的查询需求。 我们的下一个解决方案就是Presto,在使用了Presto之后,查询速度降到了秒级。但是对于一个前端查询界面的交互式查询来说,十几秒仍然是一个不能接受的时间。 虽然Presto相比Hive已经快了很多(FaceBook官方宣称的是10倍),但是对分页的支持不是很友好。我在使用的时候是自己在后端实现的分页。 在这种情况下应用缓存实属无奈之举。讲道理,优化应从底层开始,自底而上。上层优化的方式和效率感觉都很有局限。 为什么要使用缓存 前端查询中,单次查询的匹配数据量有可能会达到上百甚至上千条,在前端中肯定是需要分页展示的。就算每次查询10条数据,整个查询也要耗时6-8s的时间。想象一下,每翻一页等10s的场景。 所以,此时使用redis缓存。减少请求数据库的次数。将匹配的数据一并存入数据库。这样只有在第一次查询时耗费长一点,一旦查询完成,用户点击下一页就是毫秒级别的操作了。 使用redisTemplate Spring封装了一个比较强大的模板,也就是redisTemplate,方便在开发的时候操作Redis缓存。在Redis中可以存储String、List、Set、Hash、Zset。下面将针对List和Hash分别介绍。 List Redis中的List为简单的字符串列表,常见的有下面几种操作。 hasKey 判断一个键是否存在,只需要调用hasKey就可以了。假设这个Key是test,具体用法如下。 if (redisTemplate.hasKey("test")) { System.out.println("存在"); } else { System.out.println("不存在"); } range 该函数用于从redis缓存中获取指定区间的数据。具体用法如下。 if (redisTemplate.hasKey("test")) { // 该键的值为 [4, 3, 2, 1] System.out.println(redisTemplate.opsForList().range("test", 0, 0)); // [4] System.out.println(redisTemplate.opsForList().range("test", 0, 1)); // [4, 3] System.out.println(redisTemplate.opsForList().range("test", 0, 2)); // [4, 3, 2] System.out.println(redisTemplate.opsForList().range("test", 0, 3)); // [4, 3, 2, 1] System.out.println(redisTemplate.opsForList().range("test", 0, 4)); // [4, 3, 2, 1] System.out.println(redisTemplate.opsForList().range("test", 0, 5)); // [4, 3, 2, 1] System.out.println(redisTemplate.opsForList().range("test", 0, -1)); // [4, 3, 2, 1] 如果结束位是-1, 则表示取所有的值 } delete 删除某个键。 List<String> test = new ArrayList<>(); test.add("1"); test.add("2"); test.add("3"); test.add("4"); redisTemplate.opsForList().rightPushAll("test", test); System.out.println(redisTemplate.opsForList().range("test", 0, -1)); // [1, 2, 3, 4] redisTemplate.delete("test"); System.out.println(redisTemplate.opsForList().range("test", 0, -1)); // [] size 获取该键的集合长度。 List<String> test = new ArrayList<>(); test.add("1"); test.add("2"); test.add("3"); test.add("4"); redisTemplate.opsForList().rightPushAll("test", test); System.out.println(redisTemplate.opsForList().size("test")); // 4 leftPush 我们把存放这个值的地方想象成如图所示的容器。 并且取数据总是从左边取,但是存数据可以从左也可以从右。左就是leftPush,右就是rightPush。leftPush如下图所示。 用法如下。 for (int i = 0; i < 4; i++) { Integer value = i + 1; redisTemplate.opsForList().leftPush("test", value.toString()); System.out.println(redisTemplate.opsForList().range("test", 0, -1)); } 控制台输出的结果如下。 [1] [2, 1] [3, 2, 1] [4, 3, 2, 1] leftPushAll 基本和leftPush一样,只不过是一次性的将List入栈。 List<String> test = new ArrayList<>(); test.add("1"); test.add("2"); test.add("3"); test.add("4"); redisTemplate.opsForList().leftPushAll("test", test); System.out.println(redisTemplate.opsForList().range("test", 0, -1)); // [4, 3, 2, 1] 当然你也可以这样 redisTemplate.opsForList().leftPushAll("test", t"1", "2", "3", "4"); System.out.println(redisTemplate.opsForList().range("test", 0, -1)); // [4, 3, 2, 1] leftPushIfPresent 跟leftPush是同样的操作,唯一的不同是,当且仅当key存在时,才会更新key的值。如果key不存在则不会对数据进行任何操作。 redisTemplate.delete("test"); redisTemplate.opsForList().leftPushIfPresent("test", "1"); redisTemplate.opsForList().leftPushIfPresent("test", "2"); System.out.println(redisTemplate.opsForList().range("test", 0, -1)); // [] leftPop 该函数用于移除上面我们抽象的容器中的最左边的一个元素。 List<String> test = new ArrayList<>(); test.add("1"); test.add("2"); test.add("3"); test.add("4"); redisTemplate.opsForList().rightPushAll("test", test); redisTemplate.opsForList().leftPop("test"); // [2, 3, 4] redisTemplate.opsForList().leftPop("test"); // [3, 4] redisTemplate.opsForList().leftPop("test"); // [4] redisTemplate.opsForList().leftPop("test"); // [] redisTemplate.opsForList().leftPop("test"); // [] 值得注意的是,当返回为空后,在redis中这个key也不复存在了。如果此时再调用leftPushIfPresent,是无法再添加数据的。有代码有真相。 List<String> test = new ArrayList<>(); test.add("1"); test.add("2"); test.add("3"); test.add("4"); redisTemplate.opsForList().rightPushAll("test", test); redisTemplate.opsForList().leftPop("test"); // [2, 3, 4] redisTemplate.opsForList().leftPop("test"); // [3, 4] redisTemplate.opsForList().leftPop("test"); // [4] redisTemplate.opsForList().leftPop("test"); // [] redisTemplate.opsForList().leftPop("test"); // [] redisTemplate.opsForList().leftPushIfPresent("test", "1"); // [] redisTemplate.opsForList().leftPushIfPresent("test", "1"); // [] rightPush rightPush如下图所示。 用法如下。 for (int i = 0; i < 4; i++) { Integer value = i + 1; redisTemplate.opsForList().leftPush("test", value.toString()); System.out.println(redisTemplate.opsForList().range("test", 0, -1)); } 控制台输出的结果如下。 [1] [1, 2] [1, 2, 3] [1, 2, 3, 4] rightPushAll 同rightPush,一次性将List存入。 List<String> test = new ArrayList<>(); test.add("1"); test.add("2"); test.add("3"); test.add("4"); redisTemplate.opsForList().rightPushAll("test", test); System.out.println(redisTemplate.opsForList().range("test", 0, -1)); // [1, 2, 3, 4] 当然你也可以这样。 redisTemplate.opsForList().rightPushAll("test", "1", "2", "3", "4"); System.out.println(redisTemplate.opsForList().range("test", 0, -1)); // [1, 2, 3, 4] rightPushIfPresent 跟rightPush是同样的操作,唯一的不同是,当且仅当key存在时,才会更新key的值。如果key不存在则不会对数据进行任何操作。 redisTemplate.delete("test"); redisTemplate.opsForList().rightPushIfPresent("test", "1"); redisTemplate.opsForList().rightPushIfPresent("test", "2"); System.out.println(redisTemplate.opsForList().range("test", 0, -1)); // [] rightPop 该函数用于移除上面我们抽象的容器中的最右边的一个元素。 List<String> test = new ArrayList<>(); test.add("1"); test.add("2"); test.add("3"); test.add("4"); redisTemplate.opsForList().rightPushAll("test", test); redisTemplate.opsForList().rightPop("test"); // [1, 2, 3] redisTemplate.opsForList().rightPop("test"); // [1, 2] redisTemplate.opsForList().rightPop("test"); // [1] redisTemplate.opsForList().rightPop("test"); // [] redisTemplate.opsForList().rightPop("test"); // [] 与leftPop一样,返回空之后,再调用rightPushIfPresent,是无法再添加数据的。 index 获取list中指定位置的元素。 if (redisTemplate.hasKey("test")) { // 该键的值为 [1, 2, 3, 4] System.out.println(redisTemplate.opsForList().index("test", -1)); // 4 System.out.println(redisTemplate.opsForList().index("test", 0)); // 1 System.out.println(redisTemplate.opsForList().index("test", 1)); // 2 System.out.println(redisTemplate.opsForList().index("test", 2)); // 3 System.out.println(redisTemplate.opsForList().index("test", 3)); // 4 System.out.println(redisTemplate.opsForList().index("test", 4)); // null System.out.println(redisTemplate.opsForList().index("test", 5)); // null } 值得注意的有两点。一个是如果下标是-1的话,则会返回List最后一个元素,另一个如果数组下标越界,则会返回null。 trim 用于截取指定区间的元素,可能你会理解成与range是一样的作用。看了下面的代码之后应该就会立刻理解。 List<String> test = new ArrayList<>(); test.add("1"); test.add("2"); test.add("3"); test.add("4"); redisTemplate.opsForList().rightPushAll("test", test); // [1, 2, 3, 4] redisTemplate.opsForList().trim("test", 0, 2); // [1, 2, 3] 其实作用完全不一样。range是获取指定区间内的数据,而trim是留下指定区间的数据,删除不在区间的所有数据。trim是void,不会返回任何数据。 remove 用于移除键中指定的元素。接受3个参数,分别是缓存的键名,计数事件,要移除的值。计数事件可以传入的有三个值,分别是-1、0、1。 -1代表从存储容器的最右边开始,删除一个与要移除的值匹配的数据;0代表删除所有与传入值匹配的数据;1代表从存储容器的最左边开始,删除一个与要移除的值匹配的数据。 List<String> test = new ArrayList<>(); test.add("1"); test.add("2"); test.add("3"); test.add("4"); test.add("4"); test.add("3"); test.add("2"); test.add("1"); redisTemplate.opsForList().rightPushAll("test", test); // [1, 2, 3, 4, 4, 3, 2, 1] // 当计数事件是-1、传入值是1时 redisTemplate.opsForList().remove("test", -1, "1"); // [1, 2, 3, 4, 4, 3, 2] // 当计数事件是1,传入值是1时 redisTemplate.opsForList().remove("test", 1, "1"); // [2, 3, 4, 4, 3, 2] // 当计数事件是0,传入值是4时 redisTemplate.opsForList().remove("test", 0, "4"); // [2, 3, 3, 2] rightPopAndLeftPush 该函数用于操作两个键之间的数据,接受两个参数,分别是源key、目标key。该函数会将源key进行rightPop,再将返回的值,作为输入参数,在目标key上进行leftPush。具体代码如下。 List<String> test = new ArrayList<>(); test.add("1"); test.add("2"); test.add("3"); test.add("4"); List<String> test2 = new ArrayList<>(); test2.add("1"); test2.add("2"); test2.add("3"); redisTemplate.opsForList().rightPushAll("test", test); // [1, 2, 3, 4] redisTemplate.opsForList().rightPushAll("test2", test2); // [1, 2, 3] redisTemplate.opsForList().rightPopAndLeftPush("test", "test2"); System.out.println(redisTemplate.opsForList().range("test", 0, -1)); // [1, 2, 3] System.out.println(redisTemplate.opsForList().range("test2", 0, -1)); // [4, 1, 2, 3] Hash 存储类型为hash其实很好理解。在上述的List中,一个redis的Key可以理解为一个List,而在Hash中,一个redis的Key可以理解为一个HashMap。 put 用于写入数据。 List<String> list = new ArrayList<>(); list.add("1"); list.add("2"); list.add("3"); list.add("4"); redisTemplate.opsForHash().put("test", "map", list.toString()); // [1, 2, 3, 4] redisTemplate.opsForHash().put("test", "isAdmin", true); // true putALl 用于一次性向一个Hash键中添加多个key。 List<String> list = new ArrayList<>(); list.add("1"); list.add("2"); list.add("3"); list.add("4"); List<String> list2 = new ArrayList<>(); list2.add("5"); list2.add("6"); list2.add("7"); list2.add("8"); Map<String, String> valueMap = new HashMap<>(); valueMap.put("map1", list.toString()); valueMap.put("map2", list2.toString()); redisTemplate.opsForHash().putAll("test", valueMap); // {map2=[5, 6, 7, 8], map1=[1, 2, 3, 4]} putIfAbsent 用于向一个Hash键中写入数据。当key在Hash键中已经存在时,则不会写入任何数据,只有在Hash键中不存在这个key时,才会写入数据。 同时,如果连这个Hash键都不存在,redisTemplate会新建一个Hash键,再写入key。 List<String> list = new ArrayList<>(); list.add("1"); list.add("2"); list.add("3"); list.add("4"); redisTemplate.opsForHash().putIfAbsent("test", "map", list.toString()); System.out.println(redisTemplate.opsForHash().entries("test")); // {map=[1, 2, 3, 4]} get 用于获取数据。 List<String> list = new ArrayList<>(); list.add("1"); list.add("2"); list.add("3"); list.add("4"); redisTemplate.opsForHash().put("test", "map", list.toString()); redisTemplate.opsForHash().put("test", "isAdmin", true); System.out.println(redisTemplate.opsForHash().get("test", "map")); // [1, 2, 3, 4] System.out.println(redisTemplate.opsForHash().get("test", "isAdmin")); // true Boolean bool = (Boolean) redisTemplate.opsForHash().get("test", "isAdmin"); System.out.println(bool); // true String str = redisTemplate.opsForHash().get("test", "map").toString(); List<String> array = JSONArray.parseArray(str, String.class); System.out.println(array.size()); // 4 值得注意的是,使用get函数获取的数据都是Object类型。 所以需要使用类型与上述例子中的布尔类型的话,则需要强制转换一次。List类型则可以使用fastjson这种工具来进行转换。转换的例子已列举在上述代码中。 delete 用于删除一个Hash键中的key。可以理解为删除一个map中的某个key。 List<String> list = new ArrayList<>(); list.add("1"); list.add("2"); list.add("3"); list.add("4"); List<String> list2 = new ArrayList<>(); list2.add("5"); list2.add("6"); list2.add("7"); list2.add("8"); Map<String, String> valueMap = new HashMap<>(); valueMap.put("map1", list.toString()); valueMap.put("map2", list2.toString()); redisTemplate.opsForHash().putAll("test", valueMap); // {map2=[5, 6, 7, 8], map1=[1, 2, 3, 4]} redisTemplate.opsForHash().delete("test", "map1"); // {map2=[5, 6, 7, 8]} values 用于获取一个Hash类型的键的所有值。 List<String> list = new ArrayList<>(); list.add("1"); list.add("2"); list.add("3"); list.add("4"); redisTemplate.opsForHash().put("test", "map", list.toString()); redisTemplate.opsForHash().put("test", "isAdmin", true); System.out.println(redisTemplate.opsForHash().values("test")); // [[1, 2, 3, 4], true] entries 用于以Map的格式获取一个Hash键的所有值。 List<String> list = new ArrayList<>(); list.add("1"); list.add("2"); list.add("3"); list.add("4"); redisTemplate.opsForHash().put("test", "map", list.toString()); redisTemplate.opsForHash().put("test", "isAdmin", true); Map<String, String> map = redisTemplate.opsForHash().entries("test"); System.out.println(map.get("map")); // [1, 2, 3, 4] System.out.println(map.get("map") instanceof String); // true System.out.println(redisTemplate.opsForHash().entries("test")); // {a=[1, 2, 3, 4], isAdmin=true} hasKey 用于获取一个Hash键中是否含有某个键。 List<String> list = new ArrayList<>(); list.add("1"); list.add("2"); list.add("3"); list.add("4"); redisTemplate.opsForHash().put("test", "map", list.toString()); redisTemplate.opsForHash().put("test", "isAdmin", true); System.out.println(redisTemplate.opsForHash().hasKey("test", "map")); // true System.out.println(redisTemplate.opsForHash().hasKey("test", "b")); // false System.out.println(redisTemplate.opsForHash().hasKey("test", "isAdmin")); // true keys 用于获取一个Hash键中所有的键。 List<String> list = new ArrayList<>(); list.add("1"); list.add("2"); list.add("3"); list.add("4"); redisTemplate.opsForHash().put("test", "map", list.toString()); redisTemplate.opsForHash().put("test", "isAdmin", true); System.out.println(redisTemplate.opsForHash().keys("test")); // [a, isAdmin] size 用于获取一个Hash键中包含的键的数量。 List<String> list = new ArrayList<>(); list.add("1"); list.add("2"); list.add("3"); list.add("4"); redisTemplate.opsForHash().put("test", "map", list.toString()); redisTemplate.opsForHash().put("test", "isAdmin", true); System.out.println(redisTemplate.opsForHash().size("test")); // 2 increment 用于让一个Hash键中的某个key,根据传入的值进行累加。传入的数值只能是double或者long,不接受浮点型 redisTemplate.opsForHash().increment("test", "a", 3); redisTemplate.opsForHash().increment("test", "a", -3); redisTemplate.opsForHash().increment("test", "a", 1); redisTemplate.opsForHash().increment("test", "a", 0); System.out.println(redisTemplate.opsForHash().entries("test")); // {a=1} multiGet 用于批量的获取一个Hash键中多个key的值。 List<String> list = new ArrayList<>(); list.add("1"); list.add("2"); list.add("3"); list.add("4"); List<String> list2 = new ArrayList<>(); list2.add("5"); list2.add("6"); list2.add("7"); list2.add("8"); redisTemplate.opsForHash().put("test", "map1", list.toString()); // [1, 2, 3, 4] redisTemplate.opsForHash().put("test", "map2", list2.toString()); // [5, 6, 7, 8] List<String> keys = new ArrayList<>(); keys.add("map1"); keys.add("map2"); System.out.println(redisTemplate.opsForHash().multiGet("test", keys)); // [[1, 2, 3, 4], [5, 6, 7, 8]] System.out.println(redisTemplate.opsForHash().multiGet("test", keys) instanceof List); // true scan 获取所以匹配条件的Hash键中key的值。我查过一些资料,大部分写的是无法模糊匹配,我自己尝试了一下,其实是可以的。如下,使用scan模糊匹配hash键的key中,带SCAN的key。 List<String> list = new ArrayList<>(); list.add("1"); list.add("2"); list.add("3"); list.add("4"); List<String> list2 = new ArrayList<>(); list2.add("5"); list2.add("6"); list2.add("7"); list2.add("8"); List<String> list3 = new ArrayList<>(); list3.add("9"); list3.add("10"); list3.add("11"); list3.add("12"); Map<String, String> valueMap = new HashMap<>(); valueMap.put("map1", list.toString()); valueMap.put("SCAN_map2", list2.toString()); valueMap.put("map3", list3.toString()); redisTemplate.opsForHash().putAll("test", valueMap); // {SCAN_map2=[5, 6, 7, 8], map3=[9, 10, 11, 12], map1=[1, 2, 3, 4]} Cursor<Map.Entry<String, String>> cursor = redisTemplate.opsForHash().scan("test", ScanOptions.scanOptions().match("*SCAN*").build()); if (cursor.hasNext()) { while (cursor.hasNext()) { Map.Entry<String, String> entry = cursor.next(); System.out.println(entry.getValue()); // [5, 6, 7, 8] } } 引入redisTemplate 如果大家看懂了怎么用,就可以将redisTemplate引入项目中了。 引入pom依赖 <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-data-redis</artifactId> <version>2.0.5.RELEASE</version> </dependency> 新建配置文件 然后需要新建一个RedisConfig配置文件。 package com.detectivehlh; import com.fasterxml.jackson.annotation.JsonAutoDetect; import com.fasterxml.jackson.annotation.PropertyAccessor; import com.fasterxml.jackson.databind.ObjectMapper; import org.springframework.context.annotation.Bean; import org.springframework.context.annotation.Configuration; import org.springframework.data.redis.connection.RedisConnectionFactory; import org.springframework.data.redis.core.RedisTemplate; import org.springframework.data.redis.core.StringRedisTemplate; import org.springframework.data.redis.serializer.Jackson2JsonRedisSerializer; /** * RedisConfig * * @author Lunhao Hu * @date 2019-01-17 15:12 **/ @Configuration public class RedisConfig { @Bean public RedisTemplate<String, String> redisTemplate(RedisConnectionFactory factory) { ObjectMapper om = new ObjectMapper(); om.setVisibility(PropertyAccessor.ALL, JsonAutoDetect.Visibility.ANY); om.enableDefaultTyping(ObjectMapper.DefaultTyping.NON_FINAL); //redis序列化 Jackson2JsonRedisSerializer jackson2JsonRedisSerializer = new Jackson2JsonRedisSerializer(Object.class); jackson2JsonRedisSerializer.setObjectMapper(om); StringRedisTemplate template = new StringRedisTemplate(factory); template.setValueSerializer(jackson2JsonRedisSerializer); template.setHashKeySerializer(jackson2JsonRedisSerializer); template.setHashValueSerializer(jackson2JsonRedisSerializer); template.setValueSerializer(jackson2JsonRedisSerializer); template.afterPropertiesSet(); return template; } } 注入 将redisTemplate注入到需要使用的地方。 @Autowired private RedisTemplate redisTemplate; 写在后面 Github