基于Rancher 2.2.5的高可用分布式集群环境搭建(一)
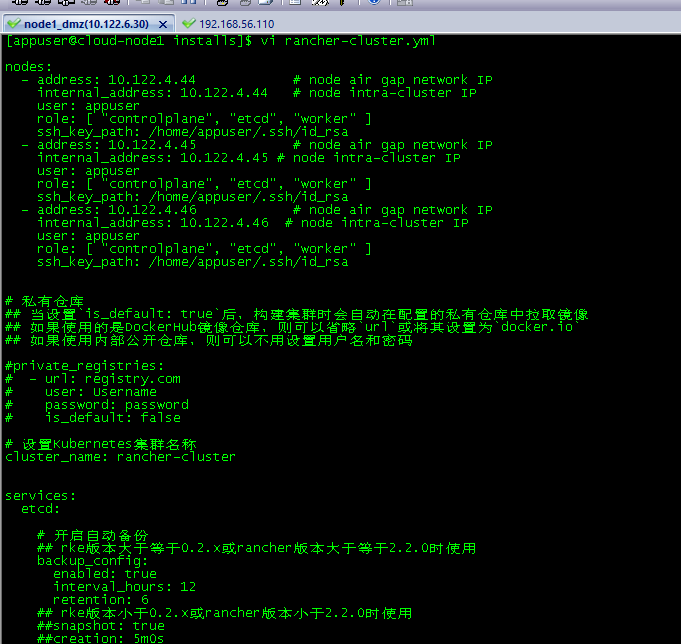
说明:本文主要目的是记录在搭建内部学习的整个过程,仅供参考。 机器配置及说明机器简单以cloud-node(n)的方式命名,因为该集群环境中会部署rancher,k8s,harbor,helm,heketi,glusterfs等; 并不承担单一角色; 本次安装均用appuser用户进行、该用户拥有sudoer权限。 操作系统: Red Hat Enterprise Linux Server release 7.6 CPU:2C 内存:8G 存储:60G Docker: 18.06.3-ce 机器IP 机器名 角色 附加存储 说明 10.122.6.30 cloud-node1 load balancer(nginx) 无 此机器部署在DMZ区,用于更新系统 10.122.4.44 cloud-node2 rancher,control panel,etcd 无 IDC区,由cloud-node1复制 10.122.4.45 cloud-node3 rancher,control panel,etcd 无 IDC区,由cloud-node1复制 10.122.4.46 cloud-node4 rancher,control panel,etcd 无 IDC区,由cloud-node1复制 10.122.4.47 cloud-node5 woker 无 IDC区,由cloud-node1复制 10.122.4.48 cloud-node6 woker 500G IDC区,由cloud-node1复制 10.122.4.49 cloud-node7 woker 500G IDC区,由cloud-node1复制 10.122.4.50 cloud-node8 woker 500G IDC区,由cloud-node1复制 Rancher 集群的安装 环境配置 基础环境配置 节点机器配置见上 主机名配置 sudo hostnamectl --static set-hostname cloud-node1 配置cloud-node1至其他节点的免密登陆(在节点cloud-node1) ssh-keygen -t rsa #一路enter,采用默认值 ssh-copy-id -i ~/.ssh/id_rsa.pub appuser@cloud-node2 #yes,输入密码; 其他节点同 Host配置 sudo vi /etc/hosts 10.122.6.30 cloud-node1 10.122.4.44 cloud-node2 10.122.4.45 cloud-node3 10.122.4.46 cloud-node4 10.122.4.47 cloud-node5 10.122.4.48 cloud-node6 10.122.4.49 cloud-node7 10.122.4.50 cloud-node8 关闭selinux【克隆前已完成】sudo sed -i 's/SELINUX=enforcing/SELINUX=disabled/g' /etc/selinux/config 关闭防火墙【克隆前已完成】sudo systemctl stop firewalld.service && systemctl disable firewalld.service 配置主机时间、时区、系统语言【由于是克隆的,本步骤跳过】 Kernel性能调优【克隆前已完成】 sudo cat >> /etc/sysctl.conf<<EOF net.ipv4.ip_forward=1 net.bridge.bridge-nf-call-iptables=1 net.ipv4.neigh.default.gc_thresh1=4096 net.ipv4.neigh.default.gc_thresh2=6144 net.ipv4.neigh.default.gc_thresh3=8192 EOF 数值根据实际环境自行配置,最后执行sudo sysctl -p保存配置。 加载内核 sudo cat >modules.sh <<EOF modprobe br_netfilter modprobe ip6_udp_tunnel modprobe ip_set modprobe ip_set_hash_ip modprobe ip_set_hash_net modprobe iptable_filter modprobe iptable_nat modprobe iptable_mangle modprobe iptable_raw modprobe nf_conntrack_netlink modprobe nf_conntrack modprobe nf_conntrack_ipv4 modprobe nf_defrag_ipv4 modprobe nf_nat modprobe nf_nat_ipv4 modprobe nf_nat_masquerade_ipv4 modprobe nfnetlink modprobe udp_tunnel #modprobe VETH #modprobe VXLAN modprobe x_tables modprobe xt_addrtype modprobe xt_conntrack modprobe xt_comment modprobe xt_mark modprobe xt_multiport modprobe xt_nat modprobe xt_recent modprobe xt_set modprobe xt_statistic modprobe xt_tcpudp EOF sudo sh modules.sh Java && Docker 安装【克隆前已完成】 tar -zxvf jdk-8u221-linux-x64.tar.gz cd jdk1.8.0_221/ sudo mv jdk1.8.0_221/ /opt/ sudo alternatives --install /usr/bin/java java /opt/jdk1.8.0_221/bin/java 3 sudo alternatives --config java (3) java -version sudo yum-config-manager --add-repo http://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.repo sudo yum install -y docker-ce-18.06.3.ce-3.el7 usermod -aG docker appuser #将appuser添加到组docker systemctl start docker & systemctl enable docker HA 离线安装离线HA安装 负载均衡器配置 在cloud-node1节点上运行 vi nginx.conf worker_processes 4; worker_rlimit_nofile 40000; events { worker_connections 8192; } stream { upstream rancher_servers_http { least_conn; server 10.122.4.44:80 max_fails=3 fail_timeout=5s; server 10.122.4.45:80 max_fails=3 fail_timeout=5s; server 10.122.4.46:80 max_fails=3 fail_timeout=5s; } server { listen 80; proxy_pass rancher_servers_http; } upstream rancher_servers_https { least_conn; server 10.122.4.44:443 max_fails=3 fail_timeout=5s; server 10.122.4.45:443 max_fails=3 fail_timeout=5s; server 10.122.4.46:443 max_fails=3 fail_timeout=5s; } server { listen 443; proxy_pass rancher_servers_https; } } 在自己的虚拟机中下载好nginx:1.14的image,导出后上传到cloud-node1并导入 在虚拟中下载`docker pull nginx:1.14 ` 下载后导出 docker save -o nginx_1.14 nginx:1.14 将文件上传至cloud-node1中,并执行 docker load --input nginx_1.14 docker run -d --restart=unless-stopped -p 80:80 -p 443:443 -v /home/appuser/installs/nginx.conf:/etc/nginx/nginx.conf nginx:1.14 安装准备 RKE安装 创建目录 mkdir -p /opt/rancher/cli && cd /opt/rancher/cli。 下载并发传v0.2.7-rke_linux-amd64至该目录下 mv v0.2.7-rke_linux-amd64 rke chmod +x rke sudo mv rke /opt/rancher/cli echo "export PATH=/opt/rancher/cli:\$PATH" >> /etc/profile source /etc/profile rke --version 创建RKE配置文件vi rancher-cluster.yml 创建K8S集群rke up --config ./rancher-cluster.yml 因ssh免密配置使用的域名,而rancher-cluster.yml使用的是ip无法通过。 故重新执行:ssh-copy-id -i ~/.ssh/id_rsa.pub appuser@10.122.44 #其他机器同