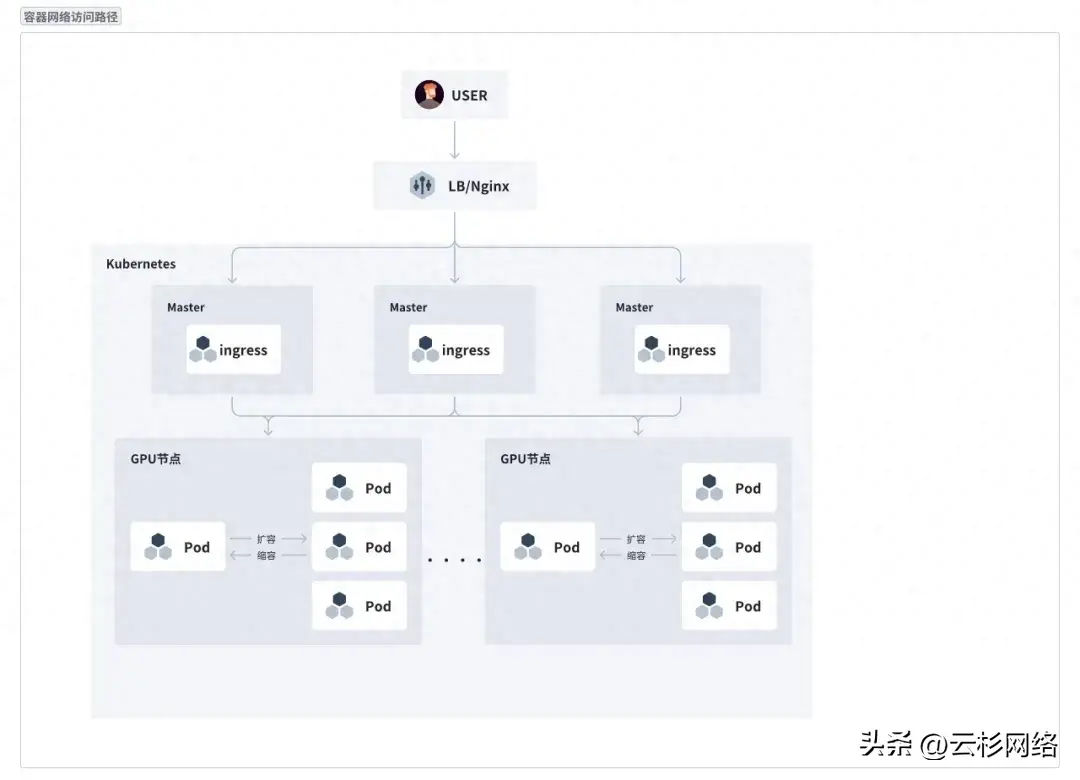
产品经理教你玩转阿里云负载均衡SLB系列(一):快速入门--什么是负载均衡
负载均衡是一种技术,从字面意义上理解,就是让负载(变得)均衡,负载是什么呢?可以理解为工作量、工作强度。用日常生活中的例子来打比方,一群建筑工人,盖一幢楼房,有搬砖的,有和水泥的,有砌墙的,有刷油漆的,同时每个工人的劳动能力还各有差别,如果让这些工作自组织的干起活来,可能有的人忙到累死,而有的人闲的无聊 ,因此不论大小工地上,都会存在监工、项目经理、包工头等这样的角色,他们会统观全局,识别每个工人的工作强度,合理分配任务,保证建筑活动的正常开展,很大程度上起到了的负载均衡的作用, 这就是负载均衡在生活中的例子。 接下来我们来看看云计算中所说的负载均衡是什么。 阿里云负载均(Server Load Balancer)是对多台云服务器进行流量分发的负载均衡服务。负载均衡可以通过流量分发扩展应用系统对外的服务能力,通过消除单点故障提升应用系