iOS - XMPP Openfire 服务器的搭建
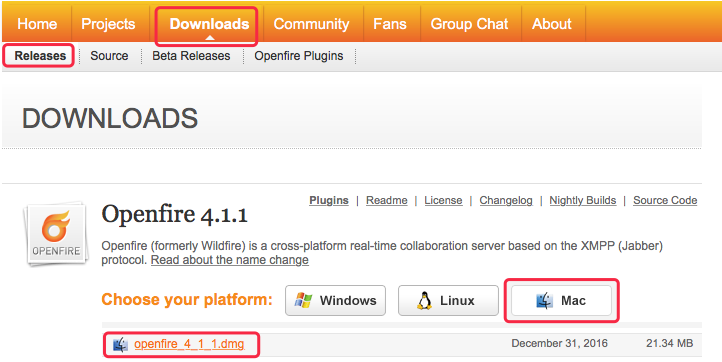
前言 提前下载好相关软件,且安装目录最好安装在全英文路径下。如果路径有中文名,那么可能会出现一些莫名其妙的问题。 提前准备好的软件: jdk-8u91-macosx-x64.dmg mysql-5.7.17-macos10.12-x86_64.dmg mysql-workbench-community-6.3.9-osx-x86_64.dmg openfire_4_1_1.dmg Openfire 官网 MySQL 官网 JDK 官网 在安装配置 Openfire 或其他 xmpp 服务器前,需要先安装 MySQL 数据库。 MySQL 安装具体讲解见 iOS - MySQL 的安装配置。 1、下载安装 Openfire 在 Openfire 官网下载最新的 Mac 版本 Openfire 安装包。 下载完后双击安装包,点击 pkg 文件,在安装引导下进行傻瓜式安装。安装完成后,进入系统偏好设置,点击 Openfire 图标。 进入 Openfire 偏好设置界面。点击 Start Openfire,让 OpenFire 服务开始启动(默认是启动的),启动完毕后,我们就可以点击 Administration 下的按钮,进入服务器后台,然后会要求输入管理员账号密码。 Openfire 服务启动不了问题解决 安装好之后,第一次是可以启动 openfire 服务器的,但是电脑重启后,就再也不能启动服务器了,每次一点击 “Start Openfire”,然后加载一下,状态还是 “Start Openfire” 没变化,有时甚至还会跳出错误提示框,提示 “Could not start the Openfire server”。 解决方案如下: 1)首先需要确认是否已经安装了 Java 的运行环境,以及 JAVA jdk 是否与当前 OS 系统版本,Openfire 版本成对应,如果不是,就请先安装相匹配对应的软件。 在终端中输入 java -version,就可以查看电脑有没有安装 JAVA 运行环境。 2)如果软件,环境对应的,最终的解决办法是 打开终端,输入以下命令: // 获取 Openfire 目录的访问权限 sudo chmod -R 777 /usr/local/openfire/bin // 以超级管理员的权限运行脚本 sudo su cd /usr/local/openfire/bin // 设置 Java 的环境变量 export JAVA_HOME=`/usr/libexec/java_home` // 输出检验环境变量的值 echo $JAVA_HOME 输入上面的命令后回车,就会出现后面的这些语句 /Library/Java/JavaVirtualMachines/jdk1.8.0_51.jdk/Contents/Home 接着在终端,输入以下命令: cd /usr/local/openfire/bin // 运行 Openfire shell 脚本 ./openfire.sh 输入上面的命令后回车,就会出现后面的这些语句 Openfire 4.1.2 [2016-2-21 2:47:51] 管理平台开始监听: http://jhq0228-macbookair.local:9090 https://jhq0228-macbookair.local:9091 Successfully loaded plugin 'admin'. 执行完这些命令之后,服务器就可以启动了,每次开机后,都启动不了的话,都试下这个方法。 2、配置 Openfire 在 Openfire 偏好设置界面中,点击 Open Admin Console,进入 web 配置页面,开始配置 Openfire 服务器。 2.1 选择语言 简体中文 2.2 服务器设置 域:如果只是本地机器上登录,可以设置为本地的域 127.0.0.1。需要远端登录的话,设置为相应的 IP 地址或域名即可。此处设置为 Mac 的机器名。 Server Host Name (FQDN):服务器名,不能为 IP 地址。 2.3 数据库设置 1、选择数据库 如果要设置外部数据库(推荐,比如:MySQL),选择标准数据库连接。 前期 MySQL 数据库准备工作 MySQL 安装具体讲解见 iOS - MySQL 的安装配置。 1)设置 /usr/local/openfire 文件夹的访问权限为可读写 方法1:在 finder 中前往文件夹 /usr/local/,右键 openfire 文件夹,显示简介,点击如图右下角中的锁图标解锁,并设置权限为可以读写。 方法2:打开终端,输入如下命令 $ sudo chmod 777 /usr/local/openfire 其中 777 表示授权可读写权限,000 表示无访问权限。 2)在终端中登陆 MySQL,输入以下命令,然后输入数据库的 root 密码登录 $ mysql -u root -p 回车后,终端输出 Welcome to the MySQL monitor. Commands end with ; or \g. Your MySQL connection id is 946 Server version: 5.7.17 MySQL Community Server (GPL) Copyright (c) 2000, 2016, Oracle and/or its affiliates. All rights reserved. Oracle is a registered trademark of Oracle Corporation and/or its affiliates. Other names may be trademarks of their respective owners. Type 'help;' or '\h' for help. Type '\c' to clear the current input statement. 3)在终端输入以下命令,创建数据库 openfire create database openfire; 回车后,终端输出 Query OK, 1 row affected (0.03 sec) 4)在终端输入以下命令,导入 openfire 资源文件夹 resources/database 下的数据表 use openfire; source /usr/local/openfire/resources/database/openfire_mysql.sql 在终端出现一排导入过程 5)在终端输入以下命令,刷新权限 flush privileges; 回车后,终端输出 Query OK, 0 rows affected (0.07 sec) 6)在终端输入以下命令,退出 MySQL exit 2、设置数据库连接 设置标准数据库连接 1)数据库驱动选项 选择 MySQL,前提是已安装 MySQL。 2)JDBC 驱动程序类 默认不变,默认为: com.mysql.jdbc.Driver 3)数据库 URL 形式如下: jdbc:mysql://你的主机名:端口号/数据库名称 jdbc:mysql://[host-name]:3306/[database-name]?rewriteBatchedStatements=true [host-name] :主机名 [database-name]:数据库名称 这里设置为: jdbc:mysql://localhost:3306/openfire 其中主机名 [host-name] 改为 localhost。 其中数据库名称 [database-name] 改为 openfire。 解决数据库字符编码问题,可以在后面加 ?useUnicode=true&characterEncoding=UTF-8&characterSetResults=UTF-8 最终的 url 形式是 jdbc:mysql://localhost:3306/openfire?useUnicode=true&characterEncoding=UTF-8&characterSetResults=UTF-8 注意:前提是已存在一个名为 openfire 的数据库,否则会报如下错误,连接配置不成功。openfire 数据库的创建具体见前面所讲的 “前期 MySQL 数据库准备工作”。 The Openfire database schema does not appear to be installed. Follow the installation guide to fix this error. 4)用户名和密码 这里的用户名密码,是访问 MySQL 数据库时使用的帐号:root,和安装 MySQL 设置的 root 密码。 2.4 特性设置 如果不打算使用 LDAP,则保持默认设置即可。 特性设置时出错问题解决 解决方法 在 OpenFire 偏好设置中重启 OpenFire,然后重新进入 OpenFire web 配置页面,重新开始配置 Openfire 服务器即可。 2.5 管理员账户设置 可以随便填写一个管理员邮箱,输入要设置的密码即可。管理员账号默认为 "admin",如果不设置密码,则默认密码为 "admin"。 自定义管理员账户名方法 在终端输入以下命令,输入数据库的 root 密码,登陆具体的数据库(openfire) mysql -u root -p openfire 删除表 “ofUser” 中的 admin 帐户 delete from ofUser where username = 'admin'; 创建自定义管理员(用户名:qianchia,密码:123456) insert into ofUser (username, plainPassword, encryptedPassword, name, email, creationDate, modificationDate) values('qianchia','123456','123456','Administrator','qianchia@icloud.com','0','0'); 查看用户 select * from ofUser; 如果可以往数据库里插入用户但是在用户摘要却没有数据,这是因为 openfire 的数据库驱动包太旧了,而安装的数据库太新了,把 openfire 里的驱动包换成新的就行了,路径:/usr/local/openfire/lib。 2.6 登陆管理控制台 完成安装后可以输入用户名和密码登陆管理控制台 默认的管理员帐号是 “admin”,默认管理员密码 “admin”,如果上面设置了新密码,则管理员密码是新密码。如果重设了用户名,必须重启 openfire 服务器。 无法登录管理控制平台问题解决 安装 Openfire 后 admin 无法登录管理控制平台。登录时提示:Login failed:make sure your username and password are correct and that you’re an admin or moderator。 解决方案如下: 1)使用 MySQL 查看工具进入数据库,进入表 “ofuser”,将该表清空,然后执行该 SQL INSERT INTO ofUser (username, plainPassword, name, email, creationDate, modificationDate) VALUES ('admin', 'admin', 'Administrator', 'admin@example.com', '0', '0'); 2)关闭 Openfire 服务,就是从其控制台 stop 然后再 start,再用用户名:admin,密码:admin 登录即可。 每次重启 Mac 电脑都需要重新配置 Openfire 问题解决 解决方法: 打开 /usr/local/openfire/conf/ 文件夹。 将 openfire.xml 和 security.xml 两个文件的权限设置为读与写。 重新完成 Openfire 配置。 3、卸载 Openfire 方法 1、卸载之前首先要停止 Openfire 服务。 系统偏好中点击 Openfire 图标,如下图 在 Openfire 偏好设置界面中,点击 Stop Openfire。 2、删除 Openfire 文件。 在终端里,输入以下三条命令执行即可。 sudo rm -rf /Library/PreferencePanes/Openfire.prefPane 以上执行后需要输入管理员密码。 sudo rm -rf /usr/local/openfire sudo rm /Library/LaunchDaemons/org.jivesoftware.openfire.plist 4、测试服务器 4.1 添加测试账户 服务器配置完成之后,我们可以创建几个用户,然后客户端可以使用这些用户信息登录,互相传输消息。 4.2 XMPP 客户端设置与使用 有许多通信聊天客户端可以支持 XMPP 协议,比如,Mac 电脑就自带了一个 “信息” app,“信息” app 就支持 jabber 通信协议(XMPP 的别名)。 打开 Mac 的 “信息” app,点击菜单 信息 -> 添加账户,选择其他 “信息” 账户... 选择 jabber 账户类型,填写相关信息 账户类型:Jabber 用户名:上边添加的测试账户名,格式必须为:名称@openfire服务器名称 密码:用户名对应的密码 服务器:openfire 服务器地址,可以使用自动查找服务器和端口 端口:openfire 服务器客户端端口 然后,提示验证证书,选择继续。 登录成功。 登录成功后在 openfire 服务器端可以看到用户的登录状态。