SQL Serever学习9——基础查询语句
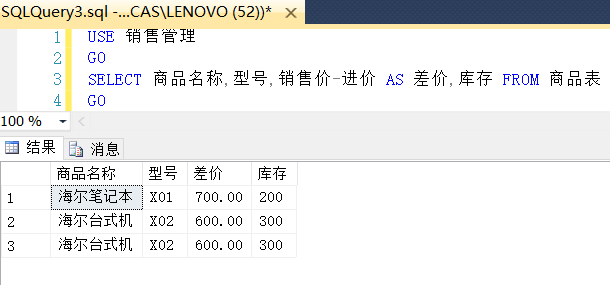
SQL语言概述 SQL是结构化查询语言(Structure Query Language),1974年提出,1979年被IBM实现,SQL语言已经成为关系型数据库的标准语言。 包括: DDL数据定义语言 语句有CREATE ,ALTER ,DROP,操作表,视图,触发器,存储过程 DML数据操作语言 语句有SELECT ,INSERT , UPDATE , DELETE,用于检索和操作数据 DCL数据控制语言 语句有GRANT , DENY , REVOKE,只有sysadmin,数据库创建者,拥有者,安全管理员有权利执行,用来设置或更改数据库用户或角色权限 流程控制 常用语句有BEGIN...END , IF...ELSE , WHILE , BREAK , GOTO , WAITFOR , RETURN等语 逻辑运算符 AND OR NOT ALL,所有表达式为true才为true ANY,表达式中一个为true则为true BETWEEN ,在某个范围内则为true EXISTS IN ,操作数为表达式列表中的一个则为true。 语句基本格式 SELECT * FROM 表名 WHERE 条件 GROUP BY 字段 HAVING 表达式 ORDER BY 字段 ASC| DESC 说明:GROUP BY子句后可以使用HAVING 短语,用来分组后筛选,HAVING 必须跟随ORDER BY子句使用。 默认情况,查询结构表的标题可以是表的字段名,也可以无标题,还可以使用AS 对字段标题进行修改 USE 销售管理 GO SELECT 商品名称,型号,销售价-进价 AS 差价,库存 FROM 商品表 GO 使用查询生成新表,或者临时表 USE 销售管理 GO SELECT 商品名称,型号,销售价-进价 AS 差价,库存 INTO 商品表附表 FROM 商品表 GO 结果 临时表的使用 临时表在本次服务器连接过程中有效,一旦服务器断开连接,临时表失效,并被删除。 USE 销售管理 GO SELECT 商品名称,型号,销售价-进价 AS 差价,库存 INTO #临时商品表 FROM 商品表 GO 快速生成数据表结构(空白哦) 因为WHERE 1=2不成立,所以就不会检索出符合条件的数据,生成的是一个没有数据的空白表 USE 销售管理 GO SELECT 商品名称,型号,销售价-进价 AS 差价,库存 INTO #商品表副本 FROM 商品表 WHERE 1=2 GO SELECT * FROM #商品表副本 SQL汇总查询 聚合函数 常用的聚合函数有6个: COUNT(*),统计所有记录个数 COUNT[ DISTINCT] 字段,统计字段中值的个数 SUM 字段,对指定字段(数值型)求和 AVG 字段,对指定字段(数值型)求平均值 MAX 字段,求一个字段最大值 MIN 字段,求一个字段最小值 分组查询语句 有时候统计每种商品销售总金额,需要对销售表中销售金额进行汇总,然后再进行操作,这就是分组查询。 GROUP BY子句实现, GROUP BY 字段 HAVING 分组后的筛选条件表达式 注意:BY 字段 按指定字段进行分组,字段值相同的记录放在一组,每一组汇总只有一条数据。 HAVING 的筛选是对经过分组后结果进行筛选,而不是对原始表筛选。 SELECT 子句后的字段列表,必须是聚合函数 ,或者是GROUP BY 子句中的字段。 demo.sql USE 销售管理 GO SELECT 品牌,COUNT(品牌) AS 数量 FROM 商品表 GROUP BY 品牌 --HAVING 品牌='A牌' 结果 注意这里的HAVING子句和WHERE的区别: HAVING可以有聚集函数,而WHERE子句不可以 HAVING作用于分组后的结果集,WHERE 子句作用于基本表 下面来一个小demo,用来查找某个属性的值出现最多的那个记录 原表 现在查找哪个品牌数量最多,并找出这个品牌的记录 demo USE 销售管理 GO --申明变量用来存储数量最多的品牌 DECLARE @ELE VARCHAR(20) SELECT @ELE=A.品牌 FROM (SELECT TOP 1 品牌,COUNT(品牌) AS 数量 FROM 商品表 GROUP BY 品牌 ORDER BY 数量 DESC) A --print @ele SELECT * FROM 商品表 WHERE 品牌=@ELE 结果集 汇总合计函数ROLLUP(在sqlserver2008叫做COMPUTE) 使用这个函数,需要最分组函数的最后添加with rollup,然后会在最后多一行。 分组 USE 销售管理 GO SELECT 品牌,COUNT(品牌) AS 数量 FROM 商品表 GROUP BY 品牌 使用ROLLUP汇总 USE 销售管理 GO SELECT 品牌,COUNT(品牌) AS 数量 FROM 商品表 GROUP BY 品牌 WITH ROLLUP 连接查询 就是多个表单的关联查询 INNER JOIN,内连接 LEFT JOIN,左连接,结果包含满足条件的行和左侧表的全部行,使用NULL值代替无法匹配的值 RIGHT JOIN,右连接 FULL JOIN,全连接,结果包含满足条件的行和2侧表的全部行 CROSS JOIN,交叉连接,结果包含2个表的所有行的组合,2个表的笛卡尔操作,用的不多 内连接范例 使用sqlserver语法 USE 销售管理 GO SELECT A.商品名称,A.品牌,A.销售价,B.类型名称 FROM 商品表 A,商品类型表 B WHERE A.类型=B.类型编号 使用ANSI语法 USE 销售管理 GO SELECT A.商品名称,A.品牌,A.销售价,B.类型名称 FROM 商品表 A INNER JOIN 商品类型表 B ON A.类型=B.类型编号 注意:<表名> A的意思是将某个表在这一次查询红命名为A,这样在整个查询中都可以使用A代替该表,简化操作。 子查询 子查询出现的形式: 多数情况出现在WHERE 子语句中 出现在外部查询的SELECT 子语句中 出现在外部查询的FROM 子句中,即把查询结果集看做另外一张表 使用比较运算符的子查询 /*查询一级买家信息*/ SELECT * FROM 买家表 WHERE 级别= (SELECT 级别编号 FROM 买家级别表 WHERE 级别名称='一级') 使用ALL ANY运算符的子查询 当子查询返回的是单列多值,使用ALL ANY和比较运算符构成特殊查询 >ANY,表示大于子查询结果的某个值,就是大于查询结果最小值 =ANY,等于查询结果的某个值,相当于IN <ANY,小于查询结果的最大值 >ALL,大于查询结果最大值 !=ALL,相当于NOT IN 比如查询那些台式电脑比笔记本电脑的进价还要贵 /*查询那些台式电脑比笔记本电脑的进价还要贵*/ SELECT * FROM 商品表 WHERE 商品名称='台式机' AND 进价>ANY (SELECT 进价 FROM 商品表 WHERE 商品名称='笔记本') 使用IN运算符的子查询 比如查询进价大于5000的商品销售情况 /*查询进价大于5000的商品销售情况*/ SELECT 商品编号,买家编号 FROM 销售表 WHERE 商品编号 IN (SELECT 商品编号 FROM 商品表 WHERE 进价>5000) 使用EXISTS运算符的子查询 用来判断子查询是否有结果返回,NOT EXISTS的作用刚好相反 比如查询至少有一次实际销售价比进价还低的商品信息 /*查询至少有一次实际销售价比进价还低的商品信息*/ SELECT * FROM 商品表 A WHERE EXISTS (SELECT * FROM 销售表 B WHERE A.商品编号=B.商品编号 AND B.实际销售价格<A.进价) 由于不需要子查询返回具体值,所以这种子查询的通常返回的列为*的格式 有个查询很难理解,记录如下 查询销售表每种商品(由商品编号区分)销售价格最贵的销售情况 分析:首先将商品种类分组 SELECT 商品编号,MAX(实际销售价格) FROM 销售表 GROUP BY 商品编号 这里还不能输出要求的信息,所以还要使用自连接(自己与自己的一个副本连接) 原表 经过筛选 /*查询销售表每种商品(由商品编号区分)销售价格最贵的销售情况*/ SELECT * FROM 商品表 A WHERE 销售价= (SELECT MAX(销售价) FROM 商品表 B WHERE A.品牌=B.品牌) ORDER BY 商品编号 数据库中数据的管理 插入数据INSERT 使用INSERT语句插入数据进数据表,有2种方式:插入单行数据(使用VALUES),插入多行数据(使用SELECT) 插入单行数据 /*插入单行数据*/ INSERT INTO 买家表(买家编号,买家名称,买家电话,级别) VALUES('M05','薛松','5362313','J02'); 当插入数据的数量和顺序和表中字段一一对应,可以省略字段名列表 /*插入单行数据*/ INSERT INTO 买家表 VALUES('M06','宋松','5362220','J02'); 插入多行数据 新建一张表,名为“高价销售表类”,结构与销售表相同,将销售表的实际销售价格>3000的记录插入该表。 /*插入多行数据*/ --建立一张空表 SELECT * INTO 高价销售表 FROM 销售表 WHERE 1=2 GO --插入多行数据 INSERT INTO 高价销售表(商品编号,买家编号,实际销售价格,销售日期,销售数量) SELECT 商品编号,买家编号,实际销售价格,销售日期,销售数量 FROM 销售表 WHERE 实际销售价格>3000 GO 为了建立一张空白表,查询条件WHERE 1=2永远不成立,这个是一个常用的方法。 将所有一级买家的信息存入新表“高级买家” /*插入多行数据*/ --创建新表 SELECT * INTO 高级买家 FROM 买家表 WHERE 1=2 GO --添加数据 INSERT INTO 高级买家 SELECT 买家表.* FROM 买家表,买家级别表 WHERE 买家表.级别=买家级别表.级别编号 AND 级别名称='一级' GO 由于查询过程使用了2个表了,所以SELECT 语句要声明,只要买家表的列 修改数据UPDATE 普通修改 因为与A品牌的合作有了新政策,所有A品牌商品进货价下调5% /*普通修改数据*/ UPDATE 商品表 SET 销售价=销售价*0.95 WHERE 品牌='A牌' 带子查询的修改 为了增加耗材商品的销售份额,公司决定将所有耗材商品销售价格下调5% /*子查询修改数据*/ UPDATE 商品表 SET 销售价=销售价*0.95 WHERE 商品表.类型= (SELECT 类型编号 FROM 商品类型表 WHERE 类型名称='耗材') 删除数据DELETE 删除普通数据 删除销售表4所有B牌的商品购买信息 /*删除数据*/ SELECT * INTO 销售表4 FROM 销售表 GO DELETE FROM 销售表4 WHERE 品牌='B牌' 删除子查询 删除销售表4中所有买家名称为“个人”的买家购买信息 /*删除数据*/ SELECT * INTO 销售表4 FROM 销售表 GO DELETE FROM 销售表4 WHERE 买家编号= (SELECT 买家编号 FROM 买家表 WHERE 买家名称='个人') 清空数据表 /*删除数据*/ SELECT * INTO 销售表4 FROM 销售表 GO TRUNCATE TABLE 销售表4 注意:TRUNCATE TABLE 和不带条件的DELETE最终效果都是清空表中所有数据,但是在执行上TRUNCATE TABLE 更高,速度更快,因为他不记录事务日志,会释放数据,索引占据的空间,删除的数据不可恢复。