使用Flask写简单的API
所有API都一样,不限于编程语言,API的难点在于路由(URL)的设计,能否精准的找到资源,而不是在于如何用技术实现。
在上一篇Python Flask学习知识点(一)文章中,记录了如何在试图函数中返回数据。上篇文章说到Flask返回的本质是字符串,通过content-type来控制返回的字符串转换为需要值,那么我们在写API的时候,API一般返回的都是JSON格式的数据,所以在视图函数中要指定content-type为JSON。
@app.route()
def search():
result = {"key1": "a", "key2": "b"}
return json.dumps(result), 200, {"content-type": "application/json"}
解释上图代码片段:
我们一般通过视图函数中做处理后拿到数据类型为python内置数据类型dict,而Flask要求,返回的结果必须是字符串,所以我们用json.dumps(result)做处理后再返回。
后边指定返回状态码200,和,返回的content-type为JSON。
以上就是一个简单的API写法。
jsonify()方法
Flask提供我们另外一个方法,便于简化,jsonify().
改写上部代码:
from flask import jsonify
@app.route()
def search():
result = {"key1": "a", "key2": "b"}
return jsonify(result)
可以看到使用内置方法jsonify()要比原先的写法更为简洁。
将视图函数拆分为单独文件
在某些业务场景下,业务功能很多,如果把所有的视图函数全部放到单个文件中,代码多不容易维护,其次就是从业务模型角度来讲,不同的业务模型应该分配不同文件当中,比如用户模型和购物车模型,显然不应该混合在同一文件,业务模型应该分门别类。不推荐把所有视图函数放到一个文件中。
再一点就是,更加不应该将视图函数放在启动入口文件当中,如下:
import json
from flask import Flask
app = Flask(__name__)
# 把自定义的config.py配置文件合并到flask配置文件中
app.config.from_object("config")
@app.route("/hello/")
def hello():
return "hello"
if __name__ == "__main__":
app.run(host="0.0.0.0", debug=app.config['DEBUG'], port=81)
所以,重新建立项目目录,原先项目目录如下图:
原先是一个配置文件,一个入口启动文件,
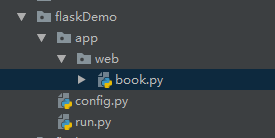
现在新建一个名为app的文件夹,在app文件夹下新建一个名为web的文件夹,然后把视图函数移到web文件夹下的book.py中,如图:
book.py中的内容:
from flask import jsonify
from run import app
__author__ = 'Allen'
@app.route('/hello')
def search():
result = {"key1": "a"}
return jsonify(result)
run.py中的内容:
from flask import Flask
app = Flask(__name__)
app.config.from_object('config')
from app.web import book
if __name__ == "__main__":
app.run(host="0.0.0.0", debug=app.config['DEBUG'], port=81)
注意:由于在book.py中没有app这个变量,所以从run.py中导入app变量,看似没有问题,实则问题很大!
会有什么问题?
这时我们运行run.py启动flask, 在浏览器中输入127.0.0.1:81/hello会得到404错误,
404就是提示我们没有找到/hello视图函数。
深入了解flask路由
上边看到,我们拆分完视图函数后,运行报错,
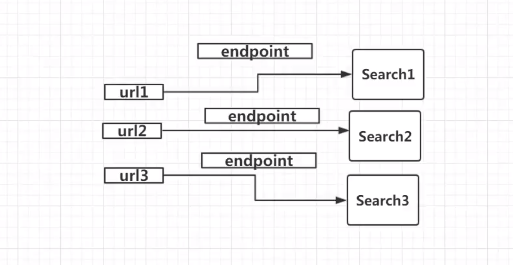
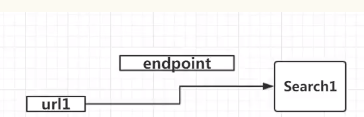
在Flask中,每一个URL对应一个视图函数,中间还有一个叫做endpoint的东西,每一个URL有一个endpoint和一个视图函数,如果通过URL正向寻找视图函数时,endpoint显得多余,
但是通过视图函数反向寻找URL函数时,endpoint是有用的。如下图:
在上一篇Python Flask学习知识点(一)文章中,说明了Flask路由注册的两种方式,其中
app.add_url_rule("/hello/", view_func=hello)
这个add_url_rule方法中其实还有一个参数endpoint
app.add_url_rule("/hello/", view_func=hello, endpoint=)
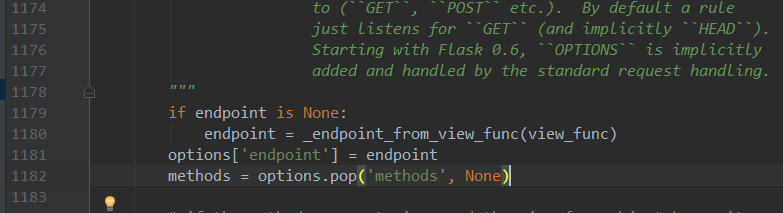
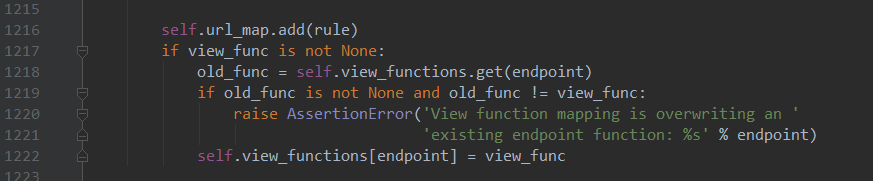
因为Flask内部有判断,如果我们不传这个参数,Flask会做处理,把视图函数的名字作为endpoint默认值传入,具体查看源码:
继续看源码,url_map中添加了我们定义的路由规则rule, view_functions中把endpoint作为key,视图函数作为value做存储,下图:
结论:如果路由要注册成功,url_map对象中,rule(/hello)指向endpoint, view_functions字典中endpoint作为key,视图函数作为value
一个成功的路由注册,需要用endpoint作为桥梁来连接上URL和视图函数。
循环引入
上边提到,只有成功的注册路由才可以访问,但是已经成功的注册后还是无法访问,这个问题是因为这里其实出现了循环引用。
在上边run.py文件中我们导入了这样一行代码:
from app.web import book
而在book.py中,我们导入了这样一行代码:
from run import app
以上两行导入代码会造成循环引用。
在运行run.py时代码执行到from app.web import book行时,会进入到book.py中,然后紧接着会执行到book.py中的这一行:from run import app,然后又会进入到run.py中,大家可以断点调试下看效果。
此时,由于之前引用过一次from app.web import book,所以不会再引用,接着,因为run文件中的app是被book.py导入的,所以if name 不等于 "main",代码会回到book.py中继续执行完,再跳回run.py中,成功启动run.py。
建议大家反复调试理解。
在上边过程中,其实app= Flask(name) ,app对象初始化了两次,我们用来注册视图函数的app和我们最终启动的app是两个不同的对象,由于循环导入,导致出现两个不同app对象。
验证一下:
在run.py中打印app对象地址
from flask import Flask
app = Flask(__name__)
print(id(app))
app.config.from_object('config')
from app.web import book
if __name__ == "__main__":
print(id(app))
app.run(host="0.0.0.0", debug=app.config['DEBUG'], port=81)
通过debug调试,可以看到两个内存地址不同,故为两个不同的app对象。
欲知后事如何,请听下回分解,记得点个赞~ 感谢。