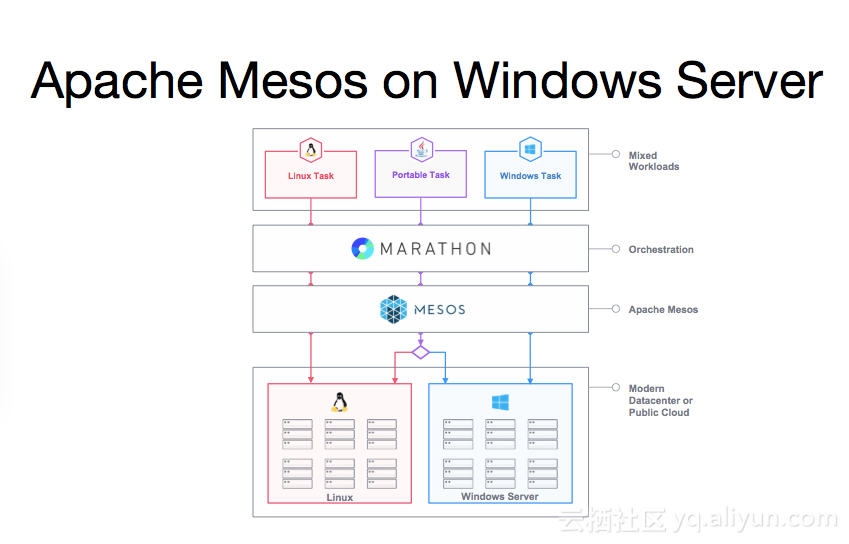
集群管理器 Mesos 能在 Windows 上运行了!
Mesosphere 和微软合作,把 Mesos 移植到 Windows,Mesos 能在 Windows Server 上运行了! Mesosphere,一家致力于构建一个基于 Mesos 项目的容器集中化“数据中心的操作系统”的公司,在 MesosCon 上公开了在 Windows Server 2016 预览版本上运行 Mesos 的第一个 demo。 微软在昨天刚刚发布了支持 Docker 容器的 Windows Server 技术预览版,开发人员都希望这些特性能很快在生产环境使用。 Mesosphere 联合创始人 Ben Hindman 说,团队跟微软在进行密切的合作,基于 Apache Mesos 项目源代码的情况下进行密切的配合。同时提到,已经有大量的 Mesosphere 企业用户提出 Windows Server 支持的需求,也已经准备好使用容器,然后使用到生产环境上。 现实中许多企业在数据中心是同时使用 Linux 和 Windows 负载。所以,使用 Mesos(Mesosphere)的用户会希望能使用一个既能在 Linux 机器又能在 Windows Servers 上运行的容器管理工具来执行任务。 微软已经在最新的 Windows Servers 预览版上提供 Mesos 移植到 Windows Server 的插件,都放到 Docker APIs 中。有了这个,开发者很快就可以使用 Windows Server 容器和更多安全的 Hyper-V 容器。 Microsoft Azure CTO Mark Russinovich 说,微软参与这个项目是因为公司希望能让用户访问其他容器编排技术,这也是 Windows 用户的需求。公司已经在 Azure 云上演示运行 Mesos,但这是一个基于 Linux 的 demo。 Mesos 移植到 Windows 这个项目的所有代码会在这一两周内发布到 GitHub repository。 值得关注的是,最近一些报道说微软正在考虑是否要收购 Mesosphere。这两家公司现在合作非常友好,微软也很清晰的引入了容器概念,不管是云平台还是服务器平台。 在过去几年里,微软也提出想参与开源社区的意愿,Google 也是,如果 Mesosphere 参与进来,无疑会有一场竞价战争。 文章转载自 开源中国社区 [http://www.oschina.net]