Android基础回顾(二)| 关于Activity
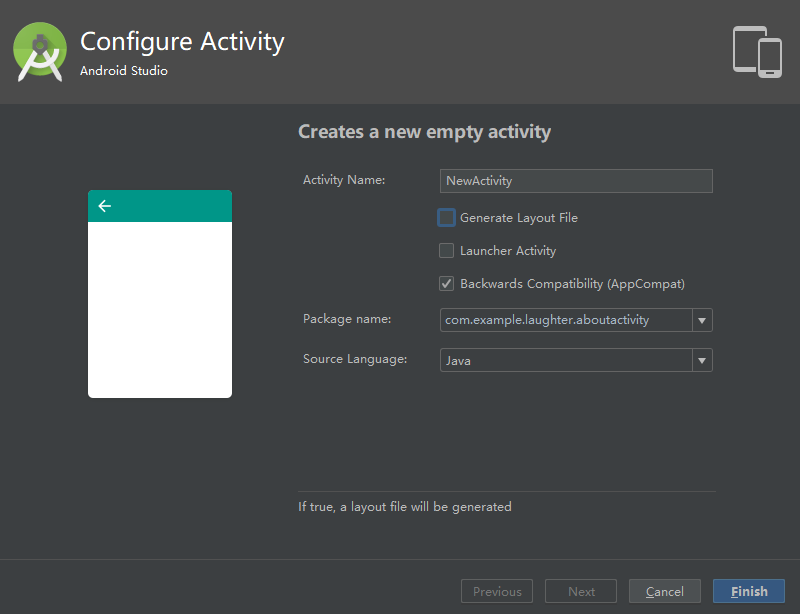
参考书籍:《第一行代码》 第二版 郭霖 开发工具:AndroidStudio 3.2 Stable Channel 如有错漏,请批评指出! Activity 定义:Activity是Android的四大组件之一,它是一种可以包含用户界面的组件,主要用于和用户进行交互。 手动创建一个Activity的三个步骤 step 1:创建Activity 在项目目录的 app\src\main\java\包名 右键->New->Activity->Empty Activity 创建Activity 先取消Generate Layout File选项的勾选,输入Activity Name ,然后点击 Finish 按钮。这样就完成了第一步。 补充说明: 勾选Generate Layout File表示自动为这个Activity创建一个对应的布局文件(默认勾选)。 勾选Launcher Activity表示自动将这个Activity设置为当前项目的主Activity(每个项目只能有一个主Activity,主Activity即启动app时显示的第一个Activity)。 勾选Backwards Compatibility(AppCompat)表示会为项目启用向下兼容的模式(默认勾选)。 Step 2:创建和加载布局文件 在项目目录的 app\src\main\res\layout 右键->New->XML->Layout XML File 创建布局文件 接下来输入Layout File Name,Root Tags 表示布局文件的根布局,这里默认LinearLayout(线性布局),后面会介绍关于布局的内容。 然后在NewActivity.java文件中为这个活动加载我们创建的布局(添加圈出的代码): 加载布局 其实就是将我们创建的Activity和布局文件关联起来,这样我们打开这个Activity 时显示的就是activity_new这个布局文件所编写的内容。 Step3:注册Activity 打开项目目录中 app\src\main\AndroidManifest.xml 文件,在这里为我们创建的Activity进行注册(实际上,在第一步我们创建这个Activity时就已经自动注册了)。 注册Activity 看起来这一步似乎是多余的,这是因为Android Studio自动帮我们注册了Activity。但是,如果我们的Activity不是通过上面的步骤创建的,而是从别的地方复制到项目中来的,那么我们就需要谨记要自己在AndroidManifest文件中为这个活动进行注册,否则就会出错。 这样,我们就完成了手动创建一个Activity的流程。实际上,在第一步我们只要勾选上Generate Layout File 选项,后面两步AndroidStudio都会自动为我们完成。 补充说明: 关于主Activity,在AndroidManifest.xml文件(上图)中我们可以看到,在MainActivity的标签下,有这样几行代码: <intent-filter> <action android:name="android.intent.action.MAIN" /> <category android:name="android.intent.category.LAUNCHER" /> </intent-filter> 实际上,在<activity>标签内部加入<intent-filter>标签,并添加上面的两句声明,就是将这个Activity指定为主Activity。我们可以在创建Activity时勾选上Launcher Activity,Android Studio就会自动为我们配置这个Activity为主Activity,当然,也可以自己在需要指定为主Activity对应的注册标签<activity>中添加上面的代码。 Toast的使用 Toast 是Android系统提供的一种非常好的提醒方式,在程序中可以使用它将一些短小的信息通知给用户,这些信息会在一段时间后自动消失,并且不会占用任何屏幕空间。 Toast的用法非常简单,通过静态方法makeText()创建出一个Toast对象,然后调用show()方法将Toast显示出来就可以了。 @Override public void onClick(View v) { switch (v.getId()){ case R.id.show_toast_button: Toast.makeText(SecondActivity.this, "You clicked button", Toast.LENGTH_SHORT).show(); break; default: break; } } 上面的代码表示通过点击我们指定的Button触发Toast弹出,我们可以看到makeText()方法有三个参数。 第一个参数是Context,即Toast要求的上下文,我们暂且只需要知道Context是一个抽象类,而Activity是它的子类,因此我们指定的SecondActivity.this就是一个Context对象。 第二个参数是我们要显示的提示信息。 第三个参数是Toast显示的时长,有两个内置常量Toast.LENGTH_SHORT和Toast.LENGTH_LONG可以选择。 效果图如下: 效果图.gif Menu的使用 由于手机屏幕空间十分有限,因此Android提供了Menu,用于展示菜单的同时,也不占用过多屏幕空间。 使用方法: step1:创建菜单布局 首先在res目录下新建一个menu文件夹,用于存放Menu布局文件,右键res->New->Directory,输入文件夹名menu;然后右键menu->New-Menu resource file,输入文件名,点击OK完成。 创建Menu布局文件 接下来根据需要创建菜单项,这里我们创建三个菜单项,代码如下: <?xml version="1.0" encoding="utf-8"?> <menu xmlns:android="http://schemas.android.com/apk/res/android"> <item android:id="@+id/add_item" android:title="@string/add"/> <item android:id="@+id/del_item" android:title="@string/del"/> <item android:id="@+id/modify_item" android:title="@string/modify"/> </menu> <item>标签就是用来创建具体的某个菜单项; android:id标签是用来给这个菜单项指定一个唯一的标识符; android:title标签是给这个菜单项指定一个名称。 step2:为当前活动创建菜单——重写onCreateOptionsMenu()方法 由于我们要给SecondActivity添加Menu,因此我们在SecondActivity.java文件中重写onCreateOptionsMenu()方法。 @Override public boolean onCreateOptionsMenu(Menu menu) { getMenuInflater().inflate(R.menu.second, menu); return true; } 通过getMenuInflater()方法获取到MenuInflater对象,再调用它的inflate()方法,给当前Activity创建菜单。inflate()方法接收两个参数: 第一个参数 用来指定第一步创建的布局文件; 第二个参数用于指定我们的菜单项添加到那个Menu对象中,这里自然是onCreateOptionsMenu()方法传入的menu对象,表示当前Activity的Menu。 返回值为true表示允许菜单显示;否则菜单不显示。 step3:为菜单定义响应事件——重写onOptionsItemSelected()方法 在SecondActivity中重写onOptionsItemSelected()方法,通过item.getItenId()方法来判断我们点击的是哪个菜单项,并为其添加逻辑处理,这里我们弹出一个Toast。 @Override public boolean onOptionsItemSelected(MenuItem item) { switch (item.getItemId()){ case R.id.add_item: Toast.makeText(SecondActivity.this, "添加", Toast.LENGTH_SHORT).show(); break; case R.id.del_item: Toast.makeText(SecondActivity.this, "删除", Toast.LENGTH_SHORT).show(); break; case R.id.modify_item: Toast.makeText(SecondActivity.this, "修改", Toast.LENGTH_SHORT).show(); break; default: break; } return true; } 效果图如下: 效果图 使用Intent实现活动间跳转 显式Intent 显式Intent的使用十分简单,直接上代码: @Override public void onClick(View v) { Intent intent = null; switch (v.getId()){ default: break; case R.id.ll_button: intent = new Intent(MainActivity.this,FirstActivity.class); startActivity(intent); break; case R.id.l2_button: intent = new Intent(MainActivity.this,SecondActivity.class); startActivity(intent); break; } } 首先,我们直接new一个Intent对象,构造方法接收两个参数,第一个参数是上下文,因为当前Activity是MainActivity,所以我们传入MainActivity.this,第二个参数指定想要启动的目标活动,这里实际上有两个button,我们分别传入FirstActivity.class和SecondActivity.class,所以点击两个button时会分别跳转到FirstActivity和SecondActivity。下面看效果: 效果图.gif 隐式Intent 相比于显式Intent,隐式Intent则含蓄了很多,它并明确指出我们要启动那个Activity,而是通过指定一系列action和category等信息,然后由系统进行分析,继而启动合适的活动。 在这里我用两个Activity进行对比,通过下面的步骤对要启动的Activity进行配置,并实现隐式启动: step1:为Activity配置action和category 在AndroidManifest文件中,我们给ThirdActivity和NewActivity分别配置<action>标签和<category>标签: <activity android:name=".ThirdActivity" android:label="@string/thirdactivity"> <intent-filter> <action android:name="com.example.aboutactivity.MY_ACTION"/> <category android:name="android.intent.category.DEFAULT"/> </intent-filter> </activity> <activity android:name=".NewActivity" android:label="@string/new_activity"> <intent-filter> <action android:name="com.example.aboutactivity.MY_ACTION"/> <category android:name="android.intent.category.DEFAULT"/> <category android:name="android.intent.category.MY_CATEGORY"/> </intent-filter> </activity> 我们给ThirdActivity指定了一个<action>标签和一个<category>标签,给NewActivity指定了一个<action>标签和两个<category>标签,下面我们通过Intent其它的构造方法来隐式指定对应的标签。 step2:给Intent添加<action>和<category>标签 @Override public void onClick(View v) { Intent intent = null; switch (v.getId()){ case R.id.l3_button: intent = new Intent("com.example.aboutactivity.MY_ACTION"); startActivity(intent); break; case R.id.l4_button: intent = new Intent("com.example.aboutactivity.MY_ACTION"); intent.addCategory("android.intent.category.MY_CATEGORY"); startActivity(intent); break; default: break; } } 从上面的代码可以看出来,我们给第一个intent添加了“com.example.aboutactivity.MY_ACTION”这个action,给第二个intent添加了“com.example.aboutactivity.MY_ACTION”这个action和“android.intent.category.MY_CATEGORY”这个category,细心的话可能会注意到,两个intent添加的action是相同的,并且第一个intent没有添加category,这是因为“android.intent.category.DEFAULT”这个category是默认category,会自动添加。而且因为我们给第二个intent添加了额外的category标签,因此两个Activity的action和category可以区分开来,这一点是为了说明,我们需要给不同的Activity指定可以区分的<action>标签和<category>标签,否则系统识别不出我们要启动的Activity。下面看效果吧! 隐式Intent.gif 从上面的效果图我们可以看出,由于两个Activity都具有相同的<action>和默认的<category>所以当我们点击ThirdActivity这个button时,系统询问我们要启动哪个Activity,我想这个现象在我们使用手机的时候也遇到过,而由于NewActivity具有自己独有的<category>标签“android.intent.category.MY_CATEGORY”,因此我们点击NewActivity这个bitton时,系统准确的启动了NewActivity,这就是隐式Intent的奇妙之处了! Activity之间的数据传递 向下一个Activity传递数据 前面我们知道Intent可以用来启动Activity,其实通过Intent我们还可以向下一个Activity传递数据,Intent提供了一系列putExtra()方法的重载,我们可以把想要传递的数据暂存在Intent中,启动另一个Activity后,我们只需要再将数据取出来,就可以了。接下来我们结合Toast以及前面创建好的MainActivity和SecondActivity来做一个演示。 step1:在第一个Activity中将数据暂存到Intent中 首先我们就在MainActivity中将数据暂存到Intent中,代码如下: @Override public void onClick(View v) { Intent intent = null; switch (v.getId()){ case R.id.l2_button: intent = new Intent(MainActivity.this,SecondActivity.class); intent.putExtra("Integer",1024); intent.putExtra("String","Hello World!"); startActivity(intent); break; default: break; } } 数据以键值对的形式暂存在Intent中,除了基本数据类型,还可以传递数组、字符串以及实现了serializable和Parcelable接口的对象。 step2:在启动的Activity中将数据取出 要取出数据,我们首先要通过getIntent()方法获取到用于启动SecondActivity的Intent对象,然后调用对应数据类型的get方法将数据取出。代码如下: @Override public void onClick(View v) { switch (v.getId()){ case R.id.show_toast_button: Intent intent = getIntent(); int num = 0; String str = null; if(intent != null){ num = intent.getIntExtra("Integer", 0); str = intent.getStringExtra("String"); } Toast.makeText(SecondActivity.this, str+"\t"+num , Toast.LENGTH_SHORT).show(); break; default: break; } } 我们在SecondActivity里面通过一个button触发Toast将传递过来的数据展示出来,下面看效果: 向下一个Activity传递数据.gif 返回数据给上一个活动 向下一个Activity传递数据十分简单,接下来说一说如何返回数据给上一个Activity。我们可以模拟这样一个场景:在前面我们通过MainActivity启动了SecondActivity,并同时向其传递了一些数据,那么假设我们在SecondActivity中收到数据时,要返回一个接收到数据的确认消息给MainActivity该怎么实现呢?Activity中有一个startActivityForResult()方法,显然这就是我们所需要的。 step1:通过startActivityFprResult()方法启动Activity 我们来修改MainActivity中的代码: @Override public void onClick(View v) { Intent intent = null; switch (v.getId()){ case R.id.l2_button: intent = new Intent(MainActivity.this,SecondActivity.class); intent.putExtra("Integer",1024); intent.putExtra("String","Hello World!"); startActivityForResult(intent,1024); break; default: break; } } startActivityForResult()方法接收两个参数,第一个是intent,第二个是请求码,用于在后面判断数据的来源。我们先往下看。 step2:在启动的Activity中添加返回数据的逻辑 我们首先在SecondActivity中添加一个button,然后为其添加点击事件。在这里我们要构建一个Intent用于传递数据,将要传递的数据存放到Intent中,然后调用setResult()方法。代码如下: @Override public void onClick(View v) { switch (v.getId()){ case R.id.data_back_button: Intent intent = new Intent(); intent.putExtra("Confirm","收到数据"); setResult(RESULT_OK, intent); finish(); break; default: break; } } 上面的逻辑就是将要返回的数据存放在Intent中,然后调用setResult()方法将数据返回给上一个Activity,setResult()方法接收两个参数,第一个参数用于向上一个Activity返回处理结果,一般只用RESULT_OK和RESULT_CANCELED这两个值。然后调用finish()方法将当前Activity结束,返回上一个Activity。当然,触发条件是点击刚才定义的Button。 step3:获取返回的数据 既然数据已经返回到MainActivity了,并且我们现在也回到MainActivity里面了,那么我们怎么知道返回的数据呢?因为我们是通过startActivityForResult()方法启动的SecondActivity,所以当我们再次回到MainActivity时,会回调onActivityResult()方法。也就是说,通过重写onActivityResult()方法,我们可以对返回的数据进行处理。下面看代码: @Override protected void onActivityResult(int requestCode, int resultCode, @Nullable Intent data) { switch (requestCode){ case 1024: if (resultCode == RESULT_OK && data != null ){ String str = data.getStringExtra("Confirm"); Toast.makeText(MainActivity.this, str, Toast.LENGTH_SHORT).show(); } break; default: break; } } onActivityResult()方法的三个参数分别是我们前面传入的请求码、返回数据时传入的处理结果和携带返回数据的Intent对象。可以看到,前面我们提到的请求码和结果码都派了用场,下面看效果: 向上一个Activity返回数据.gif Activity实际场景应用 判断当前是在哪个Activity 当我们在看别人的项目时,经常会遇上这么一个问题:这个app这么多页面,究竟每一个对应哪个Activity呢?其实想要解决这个问题并不难,下面我们来学习一个小技巧。 step1:创建一个BaseActivity类 为什么是BaseActivity类呢?因为这个BaseActivity并不是一个要显示出来的Activity,它只是作为我们Activity的基类,提供一些方法,从而实现我们的目的,并且让它继承自AppCompatActivity。右键包名->New->JavaClass 创建BaseActivity 然后重写onCreate()方法,这里为了演示效果,我们用Toast弹出当前Activity实例的类名。(在实际项目中我们用Log.d()打印出来就行了)代码如下: @Override protected void onCreate(@Nullable Bundle savedInstanceState) { super.onCreate(savedInstanceState); Toast.makeText(BaseActivity.this, getClass().getSimpleName(), Toast.LENGTH_SHORT).show(); } step2:让项目中所有的Activity都继承自BaseActivity 由于我们的BaseActivity是继承自AppCompatActivity的,因此这个修改不会带来什么影响。我们直接看运行效果吧! 知晓当前Activity.gif 随时退出应用 当我们在写一个由很多Activity组成的项目时,很可能要面临一个问题,从ActivityA打开ActivityB,然后从ActivityB打开ActivityC,这时如果我们按Back键,会依次回退到ActivityB->ActivityA->主界面,按Home键也只是返回桌面,并没有关闭应用。但是如果我们在ActivityC需要直接关闭掉这个应用呢?其实也不难,我们只需要创建一个ActivityCollector类作为Activity管理器,这个问题就迎刃而解啦! step1:创建ActivityCollector类,并添加相关方法实现 public class ActivityCollector { private static List<Activity> activities = new ArrayList<>(); public static void addActivity(Activity activity){ activities.add(activity); } public static void removeActivity(Activity activity){ activities.remove(activity); } public static void finishAllActivity(){ for (Activity activity : activities){ if (!activity.isFinishing()){ activity.finish(); } } activities.clear(); } } step2:重写BaseActivity中的相关方法 既然创建了ActivityCollector类,那么我们每创建一个Activity,就要添加到我们的Activity管理器中,每销毁一个Activity,也要从Activity管理器中将之移除。下面是代码: public class BaseActivity extends AppCompatActivity { @Override protected void onCreate(@Nullable Bundle savedInstanceState) { super.onCreate(savedInstanceState); Toast.makeText(BaseActivity.this, getClass().getSimpleName(), Toast.LENGTH_SHORT).show(); ActivityCollector.addActivity(this); } @Override protected void onDestroy() { super.onDestroy(); ActivityCollector.removeActivity(this); } } step3:在需要直接退出程序的Activity中添加相关逻辑 例如,我们要在某个Activity中通过点击某个button来关闭应用,那么我们只需要在这个Button的点击事件中调用ActivityCollector.finishAllActivity()就可以啦!关于这个就不写相关示例和演示了,自己动手,印象更深刻! 关于Activity的生命周期和启动模式我单独写了两篇博客:Android笔记(一) | Activity的生命周期Android笔记(二) | Activity的启动模式