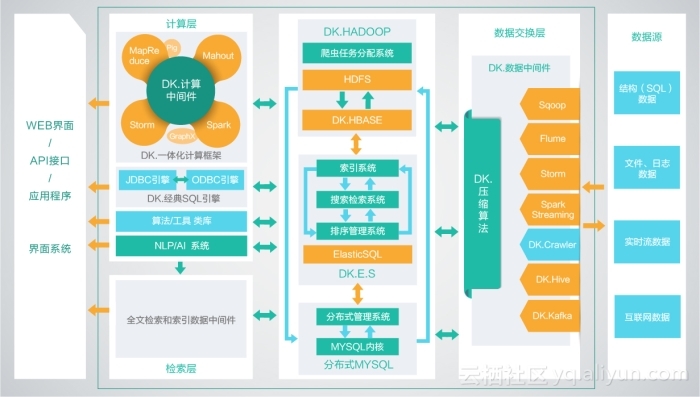

hive核心基本概念
版权声明:本文为博主原创文章,未经博主允许不得转载。 https://blog.csdn.net/xmt1139057136/article/details/82785696 1.什么是hive 基于 Hadoop 的一个数据仓库工具: hive本身不提供数据存储功能,使用HDFS做数据存储, hive也不分布式计算框架,hive的核心工作就是把sql语句翻译成MR程序 hive也不提供资源调度系统,也是默认由Hadoop当中YARN集群来调度 可以将结构化的数据映射为一张数据库表,并提供 HQL(Hive SQL)查询功能 2.hive和Hadoop关系 Hive利用HDFS存储数据,利用MapReduce查询数据 3.hive和传统数据库的区别 总结:hive具有sql数据库的外表,但应用场景完全不同,hive只适合用来做批量数据统计分析 4.hive数据的存储 1、Hive中所有的数据都存储在 HDFS 中,没有专门的数据存储格式(可支持Text,SequenceFile,ParquetFile,RCFILE等) 2、只需要在创建表的时候告诉 Hive 数据中的列分隔符和行分隔...