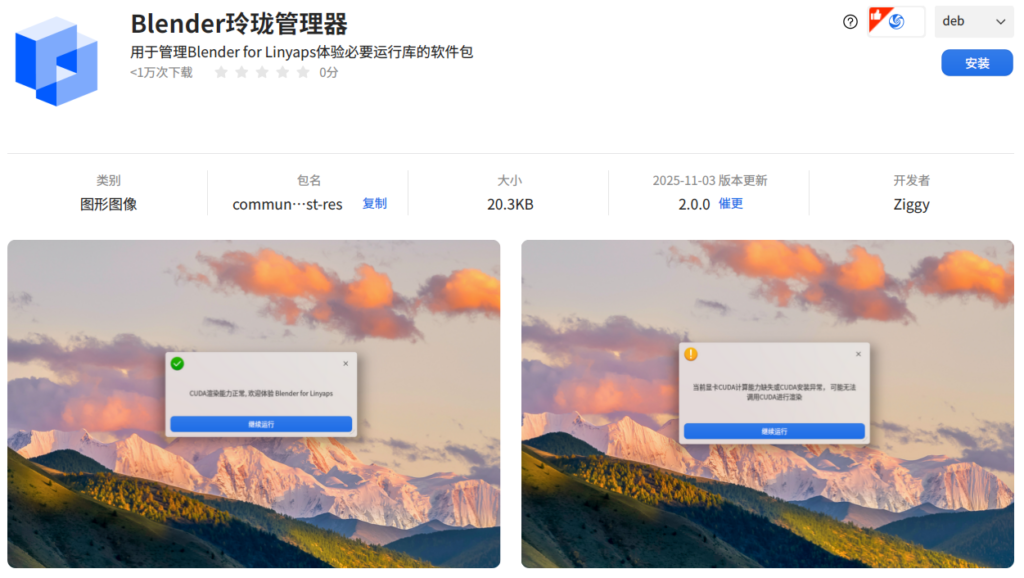
告别繁琐!Blender 玲珑管理器为 Linux 开启 CUDA 渲染超能力
谁没在 Linux 上折腾Blender CUDA 渲染的时候遇到过三大魔咒: 驱动冲突: NVIDIA 官方 .run 包与系统预装驱动冲突; 依赖地狱: 配置相互匹配的 CUDA/GCC 环境依赖,步骤复杂冗余,高风险; 门槛劝退: 纯命令行操作,新手零容错率。 好不容易到最后,可能还越调越崩...... 现在不用愁了!如意玲珑社区与 Blender 中国社区联手推出“Blender 玲珑管理器”项目,从 “配置” 这个最头疼的痛点切入,再解决命令行恐惧,给 Linux 3D 创作者一套真正能用的 “一站式加速方案”。 它具有能够让你从“折腾地狱”到“高效渲染”的 4 大核心机制: 驱动兼容保障 本方案彻底规避高风险的 NVIDIA 官方 CUDA .run 包安装方式,明确兼容 apt 仓库或系统预装的 NVIDIA 驱动,彻底规避驱动冲突风险。 依赖环境一站式部署 用户通过“Blender 玲珑管理器”一键安装,即可自动配齐 CUDA 与 GCC 等环境依赖,彻底消除运行库版本困扰与手动配置。 零命令行封装的图形化操作 全程通过 deepin 25 应用商店搜索并安装管理器,实现零命令行依赖。仅需点击确认,新手小白也能轻松上手,彻底消除对“命令行”操作的恐惧。 加速效果的机制性保障 只要 NVIDIA 显卡在官方 CUDA 支持列表中,高性能渲染加速效果就能得到充分、可靠的发挥。 接下来,我们就为大家分享详细的使用及配置过程。 一、前置准备 重要提示 此版本为⾮⽣产⼒发⾏版本,具有试验性质,请遵循⽂档进⾏操作; 初版试验项⽬仅⽀持deepin 25,其他发⾏版本敬请期待; 初版试验项⽬仅⽀持 NVIDIA 驱动版本570.124,其他驱动版本敬请期待; 确保当前系统⽤⼾⽬录即"$HOME"剩余空间不少于 16GB; 本版本仅⽤于⽅案探索,具体实现效果可能会在后续版本中有所优化、变动。 使用条件 请确保当前启⽤的 NVIDIA 显卡⽀持 CUDA,可通过以下链接查询兼容型号。 https://developer.nvidia.com/cuda-gpus https://developer.nvidia.com/cuda-legacy-gpus 请确保当前系统的 NVIDIA 显卡驱动是通过 apt 软件仓库安装或在安装系统时预装。 dpkg-l nvidia-driver 注意,若通过 .run 安装 NVIDIA 官⽅驱动,请勿使⽤本试验项⽬,否则可能导致显⽰驱动冲突。 二、使用方法 2.1 安装必要运行库 由于 CUDA 计算需要使⽤ GCC 作为编译器使⽤, 且 CUDA12.2 需要⾄少 GCC12 编译器⽀持,因此提供了独⽴安装包⽤于管理必要运⾏库。 打开 deepin 应用商店,搜索“Blender 玲珑管理器”并安装 在启动器/开始菜单找到并安装刚刚下载的Blender 玲珑管理器测试资源并根据提⽰操作,若有不⽀持的条件将会终⽌安装。 此阶段将会向系统添加开发仓库,⽤⼾需要同意后⽅可进⾏后续操作,关闭窗⼝将视为终⽌安装。 运⾏库安装器部署完成后,将会提⽰成功的结果。由于该运⾏库安装体积较大,在提⽰成功前请勿关闭计算机。 在完成上述 CUDA12.2、GCC12运⾏库安装器部署后,需要运⾏对应的安装器。 2.2 GCC12运⾏库安装 打开启动器/Launcher,找到如意玲珑GCC12.3.0安装器。此阶段将会向⽤⼾⽬录安装资源,⽤⼾需要同意后⽅可进⾏后续操作,关闭窗⼝将视为终⽌安装。资源部署完成后, 将会提⽰成功的结果。 2.3 CUDA 12.2安装 打开启动器/Launcher, 找到如意玲珑CUDA 12.2安装器。此阶段将会向⽤⼾⽬录安装资源,⽤⼾需要同意后⽅可进⾏后续操作,关闭窗⼝将视为终⽌安装。 资源部署完成后, 将会提⽰成功的结果。由于该运⾏库安装体积较⼤,在提⽰成功前请勿关闭计算机。 2.4 Blender LTS 4.x for Linyaps 安装 打开 deepin 应⽤商店,搜索如意玲珑版本的“Blender LTS”并安装,请确保包名为 org.blender.lts。 启动 Blender LTS,满⾜条件后即可启⽤ CUDA 能⼒。 三、卸载方法 必要运⾏库安装器⽬前⽀持同时管理安装/卸载功能。 通过启动器/开始菜单找到安装 Blender 玲珑管理器测试资源 并根据提⽰操作。 打开 deepin 应⽤商店,进⼊“ 应⽤管理”板块找到 Blender 玲珑管理器并卸载。 四、常见问题 4.1 必要运⾏库安装阶段 问题1:“NVML 驱动版本不在⽀持范围内” 检查当前系统是否已经正确加载受⽀持的NVIDIA显卡驱动模块 确认当前系统驱动是否通过apt软件仓库安装或系统预装 确认当前系统显卡驱动是否在受兼容范围内 问题2:“已经存在仓库请移除” 请根据提⽰的仓库名称,检查系统中是否已经配置同名仓库: ll-cli reposhow 注:为确保使⽤的是官⽅开发仓库,因此设置了强制检查阶段。 4.2 Blender 玲珑管理器运 提⽰/错误 问题1:“CUDA 计算能⼒缺失或 CUDA 安装异常” 通过终端执⾏命令 nvidia-smi ,重新启动Blender 玲珑管理器,当前测试版本可能存在加载延后问题导致检测错误; 检查当前系统是否已经正确加载受⽀持的 NVIDIA 显卡驱动模块; 确认当前系统驱动是否通过 apt 软件仓库安装或系统预装; 确认当前系统显卡驱动是否在受兼容范围内; 确认当前显卡是否受 NVIDIA CUDA ⽀持。 问题2:“Blender 玲珑管理器⽆法启动” NVIDIA 580 驱动仍未稳定,若之前使⽤ NVIDIA 570 驱动运⾏⾮玲珑版本Blender,可能存在 GPU缓存冲突问题,需要备份配置⽂件后清理缓存: ~/.cache/blender ~/.config/blender 一些其他使用建议 安装玲珑版 Blender 后,请在“偏好设置”➜“系统”中,将后端保持设置为OpenGL。如果切换至 Vulkan,可能因程序兼容性问题导致卡死或闪退(目前 Blender 对 Vulkan 的支持尚不稳定)。如已误设为 Vulkan,移除 Blender 的配置文件即可恢复默认设置。 以上便是Blender 玲珑管理器项目的完整介绍及使用指南,我们衷心感谢Blender中国社区在此过程中的大力支持与贡献。 从“望而却步”到“轻松启用”,Blender 玲珑管理器项目是两大社区以用户需求为核心的诚意之作。无论你是deepin资深玩家,还是 Blender 新人,都能借它省去技术折腾,专注创意。 如果你身边有 deepin+Blender 的使用者,不妨把这个“加速神器”分享给 TA!也欢迎在评论区聊聊你过往配置 CUDA 的经历,一起感受如意玲珑带来的创作生态升级~