Java并发编程笔记之ThreadLocal内存泄漏探究
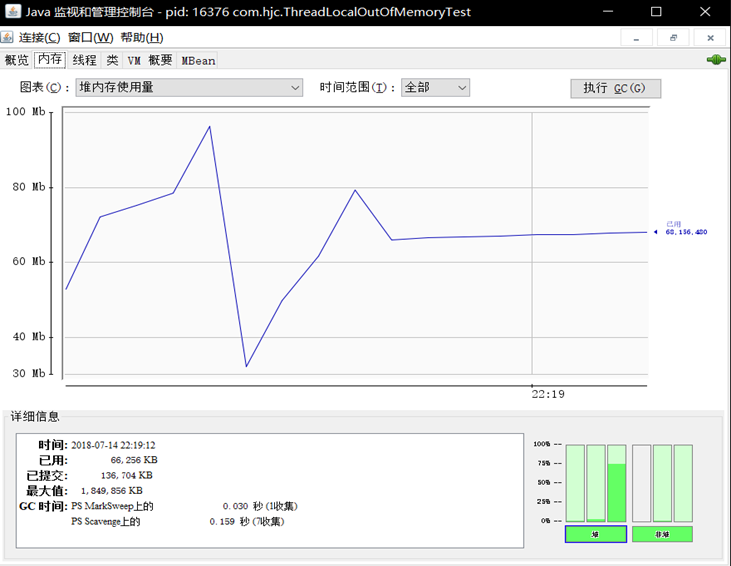
使用 ThreadLocal 不当可能会导致内存泄露,是什么原因导致的内存泄漏呢? 我们首先看一个例子,代码如下: /** * Created by cong on 2018/7/14. */ public class ThreadLocalOutOfMemoryTest { static class LocalVariable { private Long[] a = new Long[1024*1024]; } // (1) final static ThreadPoolExecutor poolExecutor = new ThreadPoolExecutor(6,6,1,TimeUnit.MINUTES, new LinkedBlockingQueue<>()); // (2) final static ThreadLocal<LocalVariable> localVariable = new ThreadLocal<LocalVariable>(); public static void main(String[] args) throws InterruptedException { // (3) for (int i = 0; i < 50; ++i) { poolExecutor.execute(new Runnable() { public void run() { // (4) localVariable.set(new LocalVariable()); // (5) System.out.println("use local varaible"); // localVariable.remove(); } }); Thread.sleep(1000); } // (6) System.out.println("pool execute over"); } } 代码(1)创建了一个核心线程数和最大线程数为 6 的线程池,这个保证了线程池里面随时都有 6 个线程在运行。 代码(2)创建了一个 ThreadLocal 的变量,泛型参数为 LocalVariable,LocalVariable 内部是一个 Long 数组。 代码(3)向线程池里面放入 50 个任务。 代码(4)设置当前线程的 localVariable 变量,也就是把 new 的 LocalVariable 变量放入当前线程的 threadLocals 变量。 由于没有调用线程池的 shutdown 或者 shutdownNow 方法所以线程池里面的用户线程不会退出,进而 JVM 进程也不会退出。 运行后,我们立即打开jconsole监控堆内存变化,如下图: 接着,让我们打开 localVariable.remove() 注释,然后在运行,观察堆内存变化如下: 从第一次运行结果可知,当主线程处于休眠时候进程占用了大概 75M 内存,打开 localVariable.remove() 注释后第二次运行则占用了大概 25M 内存,可知没有写 localVariable.remove()时候内存发生了泄露,下面分析下泄露的原因,如下: 第一次运行的代码,在设置线程的 localVariable 变量后没有调用localVariable.remove()方法,导致线程池里面的 5 个线程的 threadLocals 变量里面的new LocalVariable()实例没有被释放,虽然线程池里面的任务执行完毕了,但是线程池里面的 5 个线程会一直存在直到 JVM 退出。这里需要注意的是由于 localVariable 被声明了 static,虽然线程的 ThreadLocalMap 里面是对 localVariable 的弱引用,localVariable 也不会被回收。运行结果二的代码由于线程在设置 localVariable 变量后即使调用了localVariable.remove()方法进行了清理,所以不会存在内存泄露。 接下来我们要想清楚的知道内存泄漏的根本原因,那么我们就要进入源码去看了。 我们知道ThreadLocal 只是一个工具类,具体存放变量的是在线程的 threadLocals 变量里面,threadLocals 是一个 ThreadLocalMap 类型的,我们首先一览ThreadLocalMap的类图结构,类图结构如下图: 如上图 ThreadLocalMap 内部是一个 Entry 数组, Entry 继承自 WeakReference,Entry 内部的 value 用来存放通过 ThreadLocal 的 set 方法传递的值,那么 ThreadLocal 对象本身存放到哪里了吗? 下面看看 Entry 的构造函数,如下所示: Entry(ThreadLocal<?> k, Object v) { super(k); value = v; } 接着我们再接着看Entry的父类WeakReference的构造函数super(k),如下所示: public WeakReference(T referent) { super(referent); } 接着我们再看WeakReference的父类Reference的构造函数super(referent),如下所示: Reference(T referent) { this(referent, null); } 接着我们再看WeakReference的父类Reference的另外一个构造函数this(referent , null),如下所示: Reference(T referent, ReferenceQueue<? super T> queue) { this.referent = referent; this.queue = (queue == null) ? ReferenceQueue.NULL : queue; } 可知 k 被传递到了 WeakReference 的构造函数里面,也就是说 ThreadLocalMap 里面的 key 为 ThreadLocal 对象的弱引用,具体是 referent 变量引用了 ThreadLocal 对象,value 为具体调用 ThreadLocal 的 set 方法传递的值。 当一个线程调用 ThreadLocal 的 set 方法设置变量时候,当前线程的 ThreadLocalMap 里面就会存放一个记录,这个记录的 key 为 ThreadLocal 的引用,value 则为设置的值。 但是考虑如果这个 ThreadLocal 变量没有了其他强依赖,而当前线程还存在的情况下,由于线程的 ThreadLocalMap 里面的 key 是弱依赖,则当前线程的 ThreadLocalMap 里面的 ThreadLocal 变量的弱引用会被在 gc 的时候回收,但是对应 value 还是会造成内存泄露,这时候 ThreadLocalMap 里面就会存在 key 为 null 但是 value 不为 null 的 entry 项。 其实在 ThreadLocal 的 set 和 get 和 remove 方法里面有一些时机是会对这些 key 为 null 的 entry 进行清理的,但是这些清理不是必须发生的,下面简单讲解ThreadLocalMap 的 remove 方法的清理过程,remove 的源码,如下所示: private void remove(ThreadLocal<?> key) { //(1)计算当前ThreadLocal变量所在table数组位置,尝试使用快速定位方法 Entry[] tab = table; int len = tab.length; int i = key.threadLocalHashCode & (len-1); //(2)这里使用循环是防止快速定位失效后,变量table数组 for (Entry e = tab[i]; e != null; e = tab[i = nextIndex(i, len)]) { //(3)找到 if (e.get() == key) { //(4)找到则调用WeakReference的clear方法清除对ThreadLocal的弱引用 e.clear(); //(5)清理key为null的元素 expungeStaleEntry(i); return; } } } private int expungeStaleEntry(int staleSlot) { Entry[] tab = table; int len = tab.length; //(6)去掉去value的引用 tab[staleSlot].value = null; tab[staleSlot] = null; size--; Entry e; int i; for (i = nextIndex(staleSlot, len); (e = tab[i]) != null; i = nextIndex(i, len)) { ThreadLocal<?> k = e.get(); //(7)如果key为null,则去掉对value的引用。 if (k == null) { e.value = null; tab[i] = null; size--; } else { int h = k.threadLocalHashCode & (len - 1); if (h != i) { tab[i] = null; while (tab[h] != null) h = nextIndex(h, len); tab[h] = e; } } } return i; } 代码(4)调用了 Entry 的 clear 方法,实际调用的是父类 WeakReference 的 clear 方法,作用是去掉对 ThreadLocal 的弱引用。 代码(6)是去掉对 value 的引用,到这里当前线程里面的当前 ThreadLocal 对象的信息被清理完毕了。 代码(7)从当前元素的下标开始看 table 数组里面的其他元素是否有 key 为 null 的,有则清理。循环退出的条件是遇到 table 里面有 null 的元素。所以这里知道 null 元素后面的 Entry 里面 key 为 null 的元素不会被清理。 总结: 1.ThreadLocalMap 内部 Entry 中 key 使用的是对 ThreadLocal 对象的弱引用,这为避免内存泄露是一个进步,因为如果是强引用,那么即使其他地方没有对 ThreadLocal 对象的引用,ThreadLocalMap 中的 ThreadLocal 对象还是不会被回收,而如果是弱引用则这时候 ThreadLocal 引用是会被回收掉的。 2.但是对于的 value 还是不能被回收,这时候 ThreadLocalMap 里面就会存在 key 为 null 但是 value 不为 null 的 entry 项,虽然 ThreadLocalMap 提供了 set,get,remove 方法在一些时机下会对这些 Entry 项进行清理,但是这是不及时的,也不是每次都会执行的,所以一些情况下还是会发生内存泄露,所以在使用完毕后即使调用 remove 方法才是解决内存泄露的最好办法。 3.线程池里面设置了 ThreadLocal 变量一定要记得及时清理,因为线程池里面的核心线程是一直存在的,如果不清理,那么线程池的核心线程的 threadLocals 变量一直会持有 ThreadLocal 变量。