MongoDB学习:备份恢复(一)
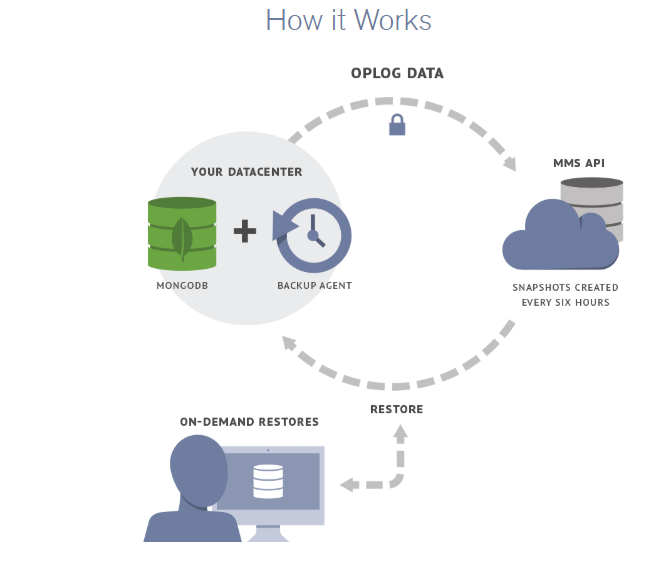
本文主要介绍MongoDB副本集备份恢复的方法、常用命令,以及一些具体的操作过程,最后介绍一种备份方案。 一、备份方法 0、oplog 0.1oplog是什么oplog是一个 capped collection(有上限的集合),位于local库里 0.2local库local库是MongoDB的系统库,记录着时间戳和索引和复制集等信息0.2.1没有建立副本集的时候 > show collections startup_log 0.2.2建立的副本集之后(3.4、3.6和4.0都是这些集合) replSet27017:PRIMARY> use local switched to db local replSet27017:PRIMARY> show collections me #me集合保存了服务器名称 oplog.rs #oplog.rs集合记录对节点的所有操作 replset.election replset.minvalid #replset.minvalid集合保存了数据库最新操作的时间戳 replset.oplogTruncateAfterPoint startup_log #startup_log集合记录这mongod每一次的启动信息 system.replset #system.replset记录着复制集的成员配置信息,rs.conf()读取这个集合 system.rollback.id 0.3查看oplog0.3.1oplog字段说明 replSet27017:PRIMARY> db.oplog.rs.find().pretty().limit(1) { "ts" : Timestamp(1558940829, 599), "t" : NumberLong(12), "h" : NumberLong("6800425020320237930"), "v" : 2, "op" : "i", "ns" : "config.system.sessions", "ui" : UUID("10b4d6ac-37df-4586-8a2d-83a3389d7406"), "wall" : ISODate("2019-05-16T08:44:39.629Z"), "o" : { "_id" : { "id" : UUID("fa4f2ff2-8251-4dec-b517-ebcab6db2eca"), "uid" : BinData(0,"LkqZkoMQbGtpaIwmLLkI3wtgnsDvRhwXsdiic1EAMLE=") }, "lastUse" : ISODate("2019-05-16T08:44:39.629Z"), "user" : { "name" : "test@test01" } } ts: 操作时间,8字节的时间戳,由4字节unix timestamp + 4字节自增计数表示(表示某一秒内的第几次操作) h:操作的全局唯一标识 v:oplog版本信息 op:1字节的操作类型 i:插入操作 u:更新操作 d:删除操作 c:执行命令(如createDatabase,dropDatabase) n:空操作,会定期执行以确保时效性 ns:操作针对的集合 o:操作内容 o2:在执行更新操作时的where条件,仅限于update时才有该属性 #查看oplog的信息 replSet27017:PRIMARY> db.printReplicationInfo() configured oplog size:1024MB log length start to end: 1866871secs (518.58hrs) oplog first event time:Tue May 14 2019 23:15:10 GMT+0800 (CST) oplog last event time:Wed Jun 05 2019 13:49:41 GMT+0800 (CST) now:Mon May 20 2019 03:20:48 GMT+0800 (CST) #查看slave的同步状态 replSet27017:PRIMARY> db.printSlaveReplicationInfo() source: 192.168.1.12:27017 syncedTo: Wed Jun 05 2019 13:49:41 GMT+0800 (CST) 0 secs (0 hrs) behind the primary source: 192.168.1.13:27017 syncedTo: Wed Jun 05 2019 13:49:41 GMT+0800 (CST) 0 secs (0 hrs) behind the primary 0.3.2根据操作类型查操作 查询oplog里的insert记录,对应op为i的记录: replSet27017:PRIMARY> db.oplog.rs.find({"op" : "i"}).pretty().limit(3) 查update操作命令: replSet27017:PRIMARY> db.oplog.rs.find({"op" : "u"}).pretty().limit(3) test:PRIMARY> 查delete操作命令: replSet27017:PRIMARY> db.oplog.rs.find({"op" : "d"}).pretty().limit(3) 0.3.3根据时间查询操作 mongodb里的时间 #操作系统时间 #date Mon May 20 02:33:45 CST 2019 #mongo里显示当地时间 replSet27017:PRIMARY> Date() Mon May 20 2019 02:34:21 GMT+0800 (CST) #构建一个格林尼治时间,我们是东八区,所以需要减去8个小时 replSet27017:PRIMARY> new Date ISODate("2019-05-19T18:34:24.157Z") #也是格林尼治时间 replSet27017:PRIMARY> ISODate() ISODate("2019-05-19T18:34:28.820Z") #时间戳 ISODate().valueOf() 1558291032161 1、复制文件 1.1 文件系统快照要创建一致的备份,必须锁定数据库,并且必须在备份过程中暂停对数据库的所有写入;快照反映了所有的数据和journal log开始的时刻,没有增量备份。1.1.1 使用LVM创建快照 lvcreate --size 100M --snapshot --name mdb-snap01 /dev/vg0/mdb-snap01 --snapshot 创建一个LVM快照--size 快照的上限大小,如果耗尽空间,快照将无法使用 1.1.2 归档快照如将上述快照挂载后压缩 umount /dev/vg0/mdb-snap01 dd if=/dev/vg0/mdb-snap01 | gzip > mdb-snap01.gz 1.1.3 恢复快照 lvcreate --size 1G --name mdb-new vg0 gzip -d -c mdb-snap01.gz | dd of=/dev/vg0/mdb-new mount /dev/vg0/mdb-new /srv/mongodb 将mdb-snap01.gz 解压并放到mdb-new里将mdb-new挂载到 /srv/mongodb目录, 根据需要修改挂载点以对应MongoDB数据文件位置 注意: 还原的快照将具有mongod.lock文件。如果不从快照中删除此文件,MongoDB可能会认为是正常关闭。 如果在启用storage.journal.enabled的情况下运行,并且不使用db.fsyncLock(),则无需删除mongod.lock文件;如果使用db.fsyncLock(),则需要删除mongod.lock文件。 1.1.4 将备份放到远程存储过程与上述相同,只是使用SSH在远程系统上归档和压缩备份。 umount /dev/vg0/mdb-snap01 dd if=/dev/vg0/mdb-snap01 | ssh username@example.com gzip > /opt/backup/mdb-snap01.gz lvcreate --size 1G --name mdb-new vg0 ssh username@example.com gzip -d -c /opt/backup/mdb-snap01.gz | dd of=/dev/vg0/mdb-new mount /dev/vg0/mdb-new /srv/mongodb 1.1.5 大体过程 锁定数据库,使用db.fsyncLock() 执行上述快照备份命令 快照完成,解锁数据库,使用db.fsyncUnlock() 1.2 直接复制文件相比于文件系统快照,直接复制文件更为简单1.2.1 复制数据文件直接cp数据文件无法复制所有的文件,所以需要在备份的时候防止数据文件发生改变,做法也使用fsynclock命令。 replSet27017:PRIMARY> db.fsyncLock() 该命令会锁定(lock)数据库,禁止任何写入,并进行同步(fsync),即将所有的脏页刷到磁盘。Mongod会将之后的所有写操作加入等待队列 cp -R/data1/mongodb27017/* /backup/mongodb27017_20190704 数据复制完成后,解锁数据库: replSet27017:PRIMARY> db.fsyncUnlock(); 注意:如果启用了身份验证,则在调用fsyncLock()和fsynUnlock()期间不要关闭shell。如果断开了连接,则可能无法进行重新连接,并不得不重启mongod。FsyncLok()的设定是在重启后不会保持生效,mongod总是以非锁定模式启动的。 当然,除了使用fsyncLock()外,关闭mongod,复制文件,再启动mongod,也是一种方法。 2、mongodump 与 mongorestore 2.1 mongodump2.1.1 常用参数 -d:数据库名 -c:集合名 -o:要导出的文件名 -q:导出数据的过滤条件 --authenticationDatabase:保存用户凭证的数据库 --gzip:备份时压缩 --oplog:导出的同时生成一个oplog.bson文件,存放在你开始进行dump到dump结束之间所有的oplog 2.1.2常用备份操作 #备份所有库 ./mongodump -h192.168.1.11:27017 -uroot -prootroot --authenticationDatabase admin -o /data/mongodb/backup/full_20190525 #备份test01库 ./mongodump -h192.168.1.11:27017 -uroot -prootroot --authenticationDatabase admin -d test01 -o /data/mongodb/backup/20190525 #备份test01库下 testCollection集合 ./mongodump -h192.168.1.11:27017 -uroot -prootroot --authenticationDatabase admin -d test01 -c testCollection -o /data/mongodb/backup/20190525 2.2 mongorestore2.2.1 常用参数 --drop: 恢复每个集合之前先删除 --oplogReplay: 重放oplog.bson中的操作内容 --oplogLimit: 与--oplogReplay一起使用时,可以限制重放到的时间点 2.3 模拟不断插入操作过程中备份和恢复(恢复到单节点)模拟不断插入集合test.table use test1 for(var i = 0; i < 10000; i++) { db.test.table.insert({a: i}); } 在插入过程中mongodump备份并指定--oplog: ./mongodump -vv -h127.0.0.1:27017 -uroot -prootroot --authenticationDatabase admin --oplog -o /data/mongodb/backup 恢复test1库(在一个单节点恢复) ./mongorestore -h127.0.0.1:27018 -d test1 /data/backup1/test1 查看插入了多少条 > db.test.table.count() 4029 应用插入期间记录的oplogmongorestore -vv -h127.0.0.1:27018 --oplogReplay /data/backup1查看应用了oplog后插入了多少条(说明这些是在备份期间插入的) > db.test.table.count() 4044 注意:--oplog选项只对全库导出有效,所以不能指定-d选项 查看oplog.bson内容 ./bsondump /data/mongodb/backup1/oplog.bson 3、mongoexport 与 mongoimport 3.1 mongoexport参数: -csv:指明要导出为csv格式 -f:指明需要导的字段 备份集合collection1 ./mongoexport -h 192.168.1.12:27017 -uroot -prootroot --authenticationDatabase admin -d db01 -c collection1 -o /data/mongodb/backup1/collection1.json 导出的数据 {"_id":{"$oid":"5cf8c674bd10185cb185067f"},"name":"hushi","num":0.0} ... 导出为csv格式 ./mongoexport -h 192.168.1.12:27017 -uroot -prootroot --authenticationDatabase admin -d db01 -c collection1 --type=csv -f _id,name,num -o /data/mongodb/backup1/collection1.csv 导出的数据 _id,name,num ObjectId(5cf8c674bd10185cb185067f),hushi,0 ObjectId(5cf8c674bd10185cb185068b),hushi,12 ... 3.2 mongoimport参数: --headerline: 指明第一行是列名,不需要导入 -csv:指明要导入的是csv格式 -f:指明需要导入的字段 恢复之前备份的集合 mongoimport -h192.168.1.14:27018 -d test -c collection1 /data/collection1.json 恢复之前备份的集合 mongoimport -h 127.0.0.1:27018 -d test1 -c collection1 --type=csv --headerline --file /data/collection1.csv 4、Percona Server for MongoDB 4.1 热备原理可以想象成xtrabackup工具 备份: 首先会启动一个后台检测的进程,实时检测MongoDB Oplog的变化,一旦发现oplog有新的日志写入,立刻将日志写入到日志文件WiredTiger.backup中(你可以strings WiredTiger.backup查看oplog操作日志的变化); 复制MongoDB dbpath的数据文件和索引文件到指定的备份目录里; 恢复: 将WiredTiger.backup日志进行回放,将操作日志变更应用到WiredTiger引擎里,最终得到一致性快照恢复;把备份目录里的数据文件直接拷贝到你的dbpath下,然后启动MongoDB即可,会自动接入副本集集群。 4.2 下载安装4.2.1 下载热备由percon的mongodb版本实现,所以可以直接用percona版的mongodb,也可以将percona mongo当做一个副本集的二级节点。https://www.percona.com/downloads/percona-server-mongodb-3.6/LATEST/4.2.2 安装启动因为是要加入副本集,所以修改配置文件并启动: cp mongodb27017/mg27017.conf mongodb27018/mg27018.conf cp ../mongodb27017/mongo.keyfile . ./mongod -f /data1/mongodb27018/mg27018.conf 4.2.3 加入副本集percona 从节点: 在主节点上执行: replSet27017:PRIMARY> rs.add({host: "192.168.1.12:27018", priority: 1, hidden: false}) percona 从变为: > replSet27017:OTHER> 执行slaveOk(),为进行过验证 replSet27017:OTHER> rs.slaveOk() replSet27017:SECONDARY> 4.3 备份从节点进行备份: replSet27017:SECONDARY> use admin switched to db admin replSet27017:SECONDARY> db.runCommand({createBackup: 1, backupDir: "/backup/mongodb_20180704"}) { "ok" : 1, ... 开始备份后,立即开始往一个新集合里写数据: replSet27017:PRIMARY> for (i = 0; i < 10000; i++){ db.test6.save({'name':'hushi','num':i,date:new Date()}); } 备份完成后的数据目录:[root@vm4 /backup/mongodb_20180722]#ll -httotal 240K drwx------ 2 root root 221 Jul 22 14:43 test1 drwx------ 2 root root 4.0K Jul 22 14:43 test01 drwx------ 2 root root 4.0K Jul 22 14:43 test drwx------ 2 root root 4.0K Jul 22 14:43 mms_test drwx------ 2 root root 4.0K Jul 22 14:43 local drwx------ 2 root root 38 Jul 22 14:43 journal drwx------ 2 root root 301 Jul 22 14:43 db01 drwx------ 2 root root 216 Jul 22 14:43 config drwx------ 2 root root 4.0K Jul 22 14:43 admin -rw------- 1 root root 44K Jul 22 14:43 sizeStorer.wt -rw------- 1 root root 114 Jul 22 14:43 storage.bson -rw------- 1 root root 44K Jul 22 14:43 _mdb_catalog.wt -rw------- 1 root root 123K Jul 22 14:43 WiredTiger.backup -rw------- 1 root root 45 Jul 22 14:43 WiredTiger 4.4 恢复恢复都单节点,所以去掉配置文件里面的副本集信息传输rsync -r /backup/mongodb_20180704 192.168.1.13:/backup/ 将文件复制到配置文件目录下cp -R /backup/mongodb_20180704/* /data1/mongodb27018 将keyFile和配置文件也复制过来(也可以直接去掉验证,将security相关的参数都注释)修改配置文件后,启动./mongod -f /data1/mongodb27018/mg27018.conf 发现最后一条数据的日期晚于开始备份日期,所以验证了恢复后会直接进行日志重放 5、MongoDB Cloud Manager 5.1 介绍MongoDB Cloud Manager是官方推出的运维自动化管理系统,是企业版才支持的功能,社区用户也可以下载试用。Cloud Manager 主要功能包括 MongoDB 集群(复制集、分片)的自动化部署 集群监控、及报警定制 自动数据备份与还原 5.2 部署MongoDB Cloud Manager5.2.1 下载agent和安装 curl -OL https://cloud.mongodb.com/download/agent/automation/mongodb-mms-automation-agent-10.2.0.5851-1.rhel7_x86_64.tar.gz tar -xvf mongodb-mms-automation-agent-10.2.0.5851-1.rhel7_x86_64.tar.gz cd mongodb-mms-automation-agent-10.2.0.5851-1.rhel7_x86_64 5.2.2 配置 vi local.config mmsGroupId=5d2f52fc9ccf64f3c73b2188 mmsApiKey= #生成ApiKey mkdir /var/lib/mongodb-mms-automation #创建目录,按照配置文件里的路径 mkdir /var/log/mongodb-mms-automation chown `whoami` /var/lib/mongodb-mms-automation #修改归属 chown `whoami` /var/log/mongodb-mms-automation 5.2.3 启动agent nohup ./mongodb-mms-automation-agent --config=local.config >> /var/log/mongodb-mms-automation/automation-agent-fatal.log 2>&1 & 5.3 进行备份5.3.1 备份原理部署了agent后,会将整个副本集的数据同步到MongoDB的数据中心。初始同步完成后,agent会将加密和压缩的oplog数据流式传输到Cloud Manager,以提供数据的连续备份。 5.3.2 开始备份点击start即可开始备份 可以看到oplog一直是延迟极小的 mongodb的备份,默认6小时一次。然后oplog一直备份,秒级延迟。 备份完成后的数据目录:[root@vm4 /backup/replSet27017]#ll -httotal 288K drwxr-xr-x 2 root root 176 Jul 18 16:04 test1 drwxr-xr-x 2 root root 4.0K Jul 18 16:04 test01 drwxr-xr-x 2 root root 4.0K Jul 18 16:04 test drwxr-xr-x 2 root root 172 Jul 18 16:04 mms_test drwxr-xr-x 2 root root 299 Jul 18 16:04 db01 drwxr-xr-x 2 root root 4.0K Jul 18 16:04 admin -rw-r--r-- 1 root root 114 Jul 18 16:04 storage.bson -rw-r--r-- 1 root root 36K Jul 18 16:04 sizeStorer.wt -rw-r--r-- 1 root root 40K Jul 18 16:04 _mdb_catalog.wt -rw-r--r-- 1 root root 373 Jul 18 16:04 restoreInfo.txt -rw-r--r-- 1 root root 755 Jul 18 16:04 seedSecondary.bat -r-x---r-x 1 root root 768 Jul 18 16:04 seedSecondary.sh -rw-r--r-- 1 root root 4.0K Jul 18 16:04 WiredTigerLAS.wt -rw-r--r-- 1 root root 168K Jul 18 16:04 WiredTiger.wt -rw-r--r-- 1 root root 45 Jul 18 16:04 WiredTiger -rw-r--r-- 1 root root 21 Jul 18 16:04 WiredTiger.lock -rw-r--r-- 1 root root 1.2K Jul 18 16:04 WiredTiger.turtle 下载到本地恢复,可以发现oplog应用点和快照点时间基本是一致的: [root@vm4 /backup/replSet27017]#cat restoreInfo.txt Restore Information Group Name: testProject1 Replica Set: replSet27017 Snapshot timestamp: Thu Jul 18 04:12:24 GMT 2019 Last Oplog Applied: Thu Jul 18 04:12:23 GMT 2019 (1563423143, 1) 可以发现没有local库和journal库,所以不能直接恢复加入到副本集里,更适合数据误删恢复。 5.4 进行恢复5.4.1 恢复原理备份后的文件,是物理文件,下载后的数据是备份结束时刻的数据(应用了备份期间oplog)因为mongodb的备份,默认6小时一次。然后oplog一直备份,秒级延迟。所以恢复的时候有了任何时刻的oplog了。恢复有三种选项: 恢复快照(也就是恢复到备份结束时刻) 恢复到oplog timestamp 恢复到point in time(也是转换成oplog timestamp)5.4.2 开始恢复 在线恢复只能恢复到一个新的副本集 只下载备份,就是备份结束时刻;选择oplog点,就是继续应用oplog 按照上图所示选择时间点,会生成一条对应的命令: ./mongodb-backup-restore-util --host --port --rsId replSet27017 --groupId 5d2d88adf2a30bbee892ef0d --opStart 1563423143:1 --opEnd 1563430620:502 --oplogSourceAddr https://api-backup.us-east-1.mongodb.com --apiKey 是直接调用了mongodb官方的API,应用oplog。mongodb-backup-restore-util 是官方提供的恢复工具。 选择point time: ./mongodb-backup-restore-util --host --port --rsId replSet27017 --groupId 5d2d88adf2a30bbee892ef0d --opStart 1563423143:1 --opEnd 1563429600:0 --oplogSourceAddr https://api-backup.us-east-1.mongodb.com --apiKey 发现生成的命令和选择oplog timestamp是一样的,只是把point time转换成oplog timestamp。 seedSecondary.sh文件:因为mongodb cloud manager提供的全备恢复后没有local库,所以会自动生成一个创建oplog的文件。用于创建oplog,插入一条数据,指定副本集复制的点。 [root@vm4 /backup/replSet27017]#cat seedSecondary.sh #!/bin/sh if [ "$#" -ne 4 ]; then echo "Usage: $0 MONGODB_PORT OPLOG_SIZE_GB RS_NAME PRIMARY_HOST:PRIMARY_PORT" exit 1 fi mongo --port ${1} --eval "var res=db.getSiblingDB('local').runCommand({ create: 'oplog.rs', capped: true, size: (${2} * 1024 * 1024 * 1024)}); if(!res.ok){throw res.errmsg;} else{db.getSiblingDB('local').oplog.rs.insert({ts : Timestamp((db.version().match(/^2\.[012]/) ? 1000 : 1) * 1563423143, 1), h : NumberLong('8796150802864664169'), t : NumberLong('113'), op : 'n', ns : '', o : { msg : 'seed from backup service' }});if (db.getSiblingDB('local').system.replset.count({'_id': '${3}'}) == 0) { db.getSiblingDB('local').system.replset.insert({'_id' : '${3}','version' : 1,'members' : [{'_id' : 0,'host' :'${4}'}],'settings' : {}});}}" 二、备份恢复演练 1、还原到副本集 MongoDB运行了一段时间之后,为了新加一个节点,就需要先将备份数据恢复到一个单节点,再将单节点加入到副本集里,下面将演示使用percona server备份的数据进行还原。1.1 得到全部物理备份 replSet27017:SECONDARY> db.runCommand({createBackup: 1, backupDir: "/backup/mongodb_20180722"}) 开始备份后立即开始往新集合里写数据: replSet27017:PRIMARY> for (i = 0; i < 10000; i++){ db.test5.save({'name':'hushi','num':i,date:new Date()}); } WriteResult({ "nInserted" : 1 }) 将备份传输到新的物理机:rsync -r /backup/mongodb_20180722 192.168.1.14:/backup/ 1.2 进行恢复为了加入到副本集,所以启动的时候直接用配置文件启动,将mg27017.conf和mongo.keyfile复制到本地,再将数据文件复制到配置文件设置的目录下。配置文件进行相应的修改,先将副本集相关的参数去掉启动./mongod -f /data1/mongodb27017/mg27017.conf查看恢复之后最后一条非空的oplog > db.oplog.rs.find({op:{$ne:'n'}}).sort({$natural:-1}).limit(1).pretty() { "ts" : Timestamp(1563777601, 5), "t" : NumberLong(123), "h" : NumberLong("-6583634829168454121"), "v" : 2, "op" : "i", "ns" : "config.system.sessions", "ui" : UUID("10b4d6ac-37df-4586-8a2d-83a3389d7406"), "wall" : ISODate("2019-07-22T06:40:01.172Z"), "o" : { "_id" : { "id" : UUID("9805a821-9a88-43bf-a85d-9a0b63b98632"), "uid" : BinData(0,"Y5mrDaxi8gv8RmdTsQ+1j7fmkr7JUsabhNmXAheU0fg=") }, "lastUse" : ISODate("2019-07-22T06:40:01.175Z"), "user" : { "name" : "root@admin" } } } 发现是系统库的,所以直接查找对test5集合的操作: > db.getSiblingDB('local').oplog.rs.find({op:{$ne:'n'},ns:'mms_test.test5'}).sort({$natural:-1}).limit(1).pretty() { "ts" : Timestamp(1563777479, 674), "t" : NumberLong(123), "h" : NumberLong("6274301431493104273"), "v" : 2, "op" : "i", "ns" : "mms_test.test5", "ui" : UUID("3fd00235-24ea-447a-96c5-2d79071ad9df"), "wall" : ISODate("2019-07-22T06:37:59.619Z"), "o" : { "_id" : ObjectId("5d3559c7dde424d0301c3d21"), "name" : "hushi", "num" : 41015, "date" : ISODate("2019-07-22T06:37:59.623Z") } } 1.3 增备备份因为oplog的特性,多跑一些没有关系,所以上述是直接找到了对test5集合操作的oplog点,现在去找到最新的点。主要要保证上述点和最新的点之间的oplog必须存在。先副本集里找到离现在较近的点:replSet27017:SECONDARY> db.oplog.rs.find({op:{$ne:'n'}}).sort({$natural:-1}).limit(1).pretty() { "ts" : Timestamp(1563780036, 337), "t" : NumberLong(123), "h" : NumberLong("-2687468098839248386"), "v" : 2, "op" : "i", "ns" : "admin.test10", "ui" : UUID("083637d7-6209-4d28-9b4d-529ba26e836c"), "wall" : ISODate("2019-07-22T07:20:36.370Z"), "o" : { "_id" : ObjectId("5d3563c4fc6d8027c7545934"), "name" : "hushi", "num" : 41881, "date" : ISODate("2019-07-22T07:20:36.373Z") } 按照上述的oplog点进行dump: ./mongodump -vv -h192.168.1.11:27017 -uroot -prootroot --authenticationDatabase admin -d local -c oplog.rs -o /backup --query='{ts:{$gte:Timestamp(1563777479, 674),$lt:Timestamp(1563780036, 337)}}' 2019-07-22T15:42:40.338+0800 done dumping local.oplog.rs (52140 documents) 2019-07-22T15:42:40.342+0800 dump phase III: the oplog 2019-07-22T15:42:40.342+0800 finishing dump 1.4 将增量进行恢复mv /backup/local/oplog.rs.bson rsync /backup/local/oplog.bson 192.168.1.14:/backup/local/恢复的时候报错: Failed: restore error: error applying oplog: applyOps: not authorized on admin to execute command { applyOps: [ { ts: Timestamp(1563777601, 1), h: 2702590434054582905, v: 2, op: "d", ns: "config.system.sessions", o: { _id: { id: UUID("9f7a5b0b-a1e1-407a-b9dd-7506a3220d9e"), uid: BinData(0, 6399AB0DAC62F20BFC466753B10FB58FB7E692BEC952C69B84D997021794D1F8) } }, o2: {} } ], $db: "admin" } 解决方法(在admin数据库中执行): db.createRole({role:'sysadmin',roles:[], privileges:[ {resource:{anyResource:true},actions:['anyAction']}]}) db.grantRolesToUser( "root" , [ { role: "sysadmin", db: "admin" } ]) 进行恢复 #./mongorestore -vv -h127.0.0.1:27017 -uroot -prootroot --authenticationDatabase admin --oplogReplay /backup/local/ 2019-07-22T16:11:03.901+0800 oplog 7.71MB 2019-07-22T16:11:06.401+0800 applied 51899 ops 2019-07-22T16:11:06.401+0800 oplog 9.13MB 2019-07-22T16:11:06.401+0800 done 数据已经进行了恢复: switched to db admin > db.test10.find().sort({$natural:-1}).limit(1).pretty() { "_id" : ObjectId("5d3563c4fc6d8027c7545933"), "name" : "hushi", "num" : 41880, "date" : ISODate("2019-07-22T07:20:36.373Z") } 如果将单节点以一个新的单节点副本集去启动,那就需要删除掉所有的oplog,再重新启动。那就是跟直接将节点加入副本集是一样的。 > db.getSiblingDB('local').oplog.rs.find({op:{$ne:'n'}}).sort({$natural:-1}).limit(1).pretty() { "ts" : Timestamp(1563777601, 5), "t" : NumberLong(123), "h" : NumberLong("-6583634829168454121"), "v" : 2, "op" : "i", "ns" : "config.system.sessions", "ui" : UUID("10b4d6ac-37df-4586-8a2d-83a3389d7406"), "wall" : ISODate("2019-07-22T06:40:01.172Z"), "o" : { "_id" : { "id" : UUID("9805a821-9a88-43bf-a85d-9a0b63b98632"), "uid" : BinData(0,"Y5mrDaxi8gv8RmdTsQ+1j7fmkr7JUsabhNmXAheU0fg=") }, "lastUse" : ISODate("2019-07-22T06:40:01.175Z"), "user" : { "name" : "root@admin" } } } 如果将单节点以一个新的单节点副本集去启动,那就需要删除掉所有的oplog,再重新启动。那就是跟直接将节点加入副本集是一样的。 1.5 加入到副本集 replSet27017:PRIMARY> rs.add({host: "192.168.1.14:27017", priority: 1, hidden: false}) { "ok" : 1, 加入之后,oplog记录也一样了: replSet27017:SECONDARY> db.getSiblingDB('local').oplog.rs.find({op:{$ne:'n'},ts:{$lte:Timestamp(1563780036, 337)}}).sort({$natural:-1}).limit(1).pretty() { "ts" : Timestamp(1563780036, 337), "t" : NumberLong(123), "h" : NumberLong("-2687468098839248386"), "v" : 2, "op" : "i", "ns" : "admin.test10", "ui" : UUID("083637d7-6209-4d28-9b4d-529ba26e836c"), "wall" : ISODate("2019-07-22T07:20:36.370Z"), "o" : { "_id" : ObjectId("5d3563c4fc6d8027c7545934"), "name" : "hushi", "num" : 41881, "date" : ISODate("2019-07-22T07:20:36.373Z") } } 2、恢复误删的单个集合 插入数据for (i = 0; i < 10000; i++){ db.collection1.save({'name':'hushi','num':i}); }collection1集合备份./mongodump -vv -h192.168.1.11:27017 -uroot -prootroot --authenticationDatabase admin -d db01 -c collection1-o /data/mongodb/backup再次插入数据(进行一些操作)for (i = 0; i < 1000; i++){ db.collection1.save({'name':'hushi','num':i,date:new Date()}); }误删db.collection1.drop()查找删除 db.oplog.rs.find({op:{$ne:'n'},o:{'drop':'collection1'}}).sort({ts:-1}).pretty().limit(5) { "ts" : Timestamp(1559803854, 1), "t" : NumberLong(44), "h" : NumberLong("-514875429754097077"), "v" : 2, "op" : "c", "ns" : "db01.$cmd", "ui" : UUID("b8fe3553-8249-4f18-b652-5bba86760d43"), "wall" : ISODate("2019-06-06T06:50:54.406Z"), "o" : { "drop" : "collection1" } } 备份oplog ./mongodump -vv -h192.168.1.11:27017 -uroot -prootroot --authenticationDatabase admin -d local -c oplog.rs -o /tmp restore的时候需要是oplog.bsonmv /tmp/local/oplog.rs.bson /data/mongodb/backup/oplog.bson 恢复collection1./mongorestore -v -h127.0.0.1:27018-d db01 -c collection1 /data/backup1/db01/collection1.bson查看已经恢复前1w插入记录 db.collection1.count() 10000 应用oplogmongorestore -vv-h127.0.0.1:27018--oplogReplay--oplogLimit=1559803854:1/data/backup1/再次查看插入记录 db.collection1.count() 11000 3、恢复误删的文档 文档误删除 replSet27017:PRIMARY> for (i = 0; i < 1000; i++){ db.test4.save({'name':'hushi','num':i,date:new Date()}); } replSet27017:PRIMARY> db.test4.remove({$and:[{num:{$gte:100,$lte:300}}]}) WriteResult({ "nRemoved" : 201 }) replSet27017:PRIMARY> for (i = 1000; i < 1500; i++){ db.test4.save({'name':'hushi','num':i,date:new Date()}); } WriteResult({ "nInserted" : 1 }) 找到删除开始时间点 replSet27017:PRIMARY> db.getSiblingDB('local').oplog.rs.find({op:{$ne:'n'},ns:'mms_test.test4'},{ts:1,op:1}).sort({$natural:-1}).limit(10).skip(695) { "ts" : Timestamp(1563431039, 6), "op" : "d" } { "ts" : Timestamp(1563431039, 5), "op" : "d" } { "ts" : Timestamp(1563431039, 4), "op" : "d" } { "ts" : Timestamp(1563431039, 3), "op" : "d" } { "ts" : Timestamp(1563431039, 2), "op" : "d" } { "ts" : Timestamp(1563431039, 1), "op" : "d" } { "ts" : Timestamp(1563430620, 502), "op" : "i" } { "ts" : Timestamp(1563430620, 501), "op" : "i" } { "ts" : Timestamp(1563430620, 500), "op" : "i" } { "ts" : Timestamp(1563430620, 499), "op" : "i" } 大于等于这个时间点,删除了201条数据 replSet27017:PRIMARY> db.getSiblingDB('local').oplog.rs.find({op:{$ne:'n'},ns:'mms_test.test4',op:'d',ts:{$gte:Timestamp(1563431039, 1)}}).sort({$natural:-1}).limit(1).count() 201 replSet27017:PRIMARY> db.getSiblingDB('local').oplog.rs.find({op:{$ne:'n'},ns:'mms_test.test4',op:'d',ts:{$gte:Timestamp(1563431039, 1)}}).sort({$natural:-1}).limit(1).pretty() { "ts" : Timestamp(1563431039, 201), "t" : NumberLong(113), "h" : NumberLong("-1345379834581505732"), "v" : 2, "op" : "d", "ns" : "mms_test.test4", "ui" : UUID("9a3dbae7-4f7c-465d-b420-1b7818531fc8"), "wall" : ISODate("2019-07-18T06:23:59.997Z"), "o" : { "_id" : ObjectId("5d300edb42389abced5f7bae") } } replSet27017:PRIMARY> db.getSiblingDB('local').oplog.rs.find({op:{$ne:'n'},ns:'mms_test.test4',op:'d',ts:{$gte:Timestamp(1563431039, 1)}}).sort({$natural:1}).limit(1).pretty() { "ts" : Timestamp(1563431039, 1), "t" : NumberLong(113), "h" : NumberLong("-4777761962883174315"), "v" : 2, "op" : "d", "ns" : "mms_test.test4", "ui" : UUID("9a3dbae7-4f7c-465d-b420-1b7818531fc8"), "wall" : ISODate("2019-07-18T06:23:59.997Z"), "o" : { "_id" : ObjectId("5d300edb42389abced5f7ae6") } } 这里最后试用了一下ongodb-backup-restore-util,如果使用mongorestore是一样的,但是需要先将oplog按照时间点进行dump下来,再去进行恢复。 #./mongodb-backup-restore-util --host 127.0.0.1 --port 27017 --rsId replSet27017 --groupId 5d2d88adf2a30bbee892ef0d --opStart 1563423143:1 --opEnd 1563430620:502 --oplogSourceAddr https://api-backup.us-east-1.mongodb.com --apiKey 5d2f0fbbff7a252987d03c00086f7a1040706ba4c6c634b8f4c09b9e [2019/07/18 19:13:55.843] [pit-restore.debug] [pit-restore/standalone-pit-restore.go:main:116] Creating restore [2019/07/18 19:14:05.406] [pit-restore.debug] [pit-restore/standalone-pit-restore.go:main:137] Successfully completed restore. [2019/07/18 19:14:05.406] [pit-restore.debug] [pit-restore/standalone-pit-restore.go:main:138] Successfully completed restore. [2019/07/18 19:14:05.406] [pit-restore.info] [restore/restore.go:Stop:121] Stopping Restore 已经进行了恢复 db.test4.find({$and:[{num:{$gte:100,$lte:300}}]}).count() 201 三、备份恢复方案 1、备份策略 1.1 MongoDB Cloud Manager的备份策略:The rate is based on your having 28 snapshots at steady state: The six-hour snapshots are kept for two days; The daily snapshots for one week, The weekly snapshots for one month, The monthly for one year. 这是官方提供的全备和全备保留的时间点。oplog是一直备份,秒级延迟。 1.2 全备 + oplog顺着这个思路,全备可以和增备分开,全备照需要,每6个小时或者每一天备份一次。然后oplog每秒或者每5秒或者每1分钟进行一次备份。全备可以使用percona server进行物理热备,oplog可以按照设定的时间间隔一直备份。再可以按将一些重要的文档使用mysqldump进行备份,这样万一有误操作可以快速恢复。 2、增备oplog 2.1 进行增备 #./mongodump -vv -h192.168.1.11:27017 -uroot -prootroot --authenticationDatabase admin -d local -c oplog.rs -o /backup --query='{ts:{$gte:Timestamp(1563703200, 1),$lt:Timestamp(1563703500, 1)}}' 这里是增备了5分钟的oplog内容将增备oplog改名:mv oplog.rs.bson oplog.bson.backup ./mongodump -vv -h192.168.1.11:27017 -uroot -prootroot --authenticationDatabase admin -d local -c oplog.rs -o /backup --query='{ts:{$gte:Timestamp(1563771600, 1),$lt:Timestamp(1563775200, 1)}}' 再次增备,将增备的oplog合到一个bson文件里cat oplog.rs.bson >>oplog.bson.backup 接下来继续增备,继续将增备都追加到一个文件里。可以将每一天的增备放到一个文件里。 3、验证备份 进行了备份之后肯定要进行相关的验证,验证分为两块,一个是备份文件恢复后完整性验证,一个是oplog增备是否成功验证。一个思路是每天将全备的文件和增备的文件恢复到一个单节点。3.1 验证全备全备建议使用物理热备,如果使用的是percona server,那么可以WiredTiger.backup文件的最后一条插入记录在恢复的节点上是否存在;如果没有插入记录,或者WiredTiger.backup文件没有内容,可以简单比较一下副本集的集合数据和恢复后的节点是否相同。同样如果使用的是mongodb cloud manager这样的不记录oplog的工具,也是比较一下集合数量。3.2 验证增备验证增备可以查看bson文件里最后一条插入的数据是什么,查看恢复后的文件是否有这条数据。