java8学习:入门
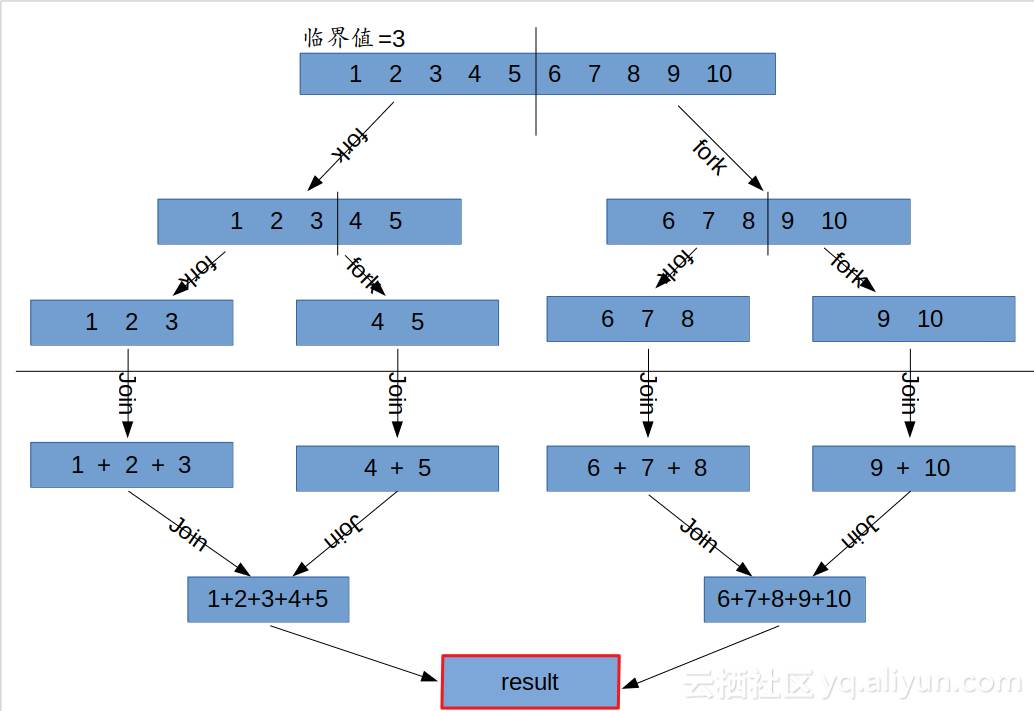
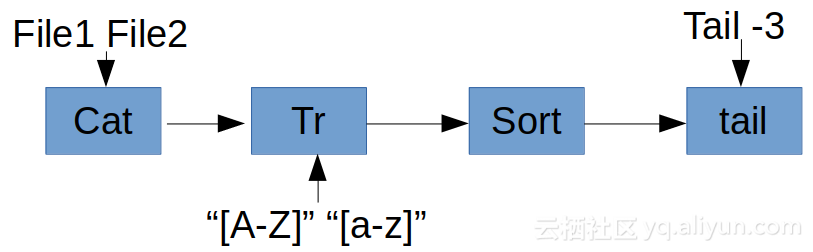
内容来自《 java8实战 》,本篇文章内容均为非盈利,旨为方便自己查询、总结备份、开源分享。如有侵权请告知,马上删除。书籍购买地址:java8实战 sync的使用成本:多核CPU的每个处理器内核都有独立的告诉缓存,加锁需要这些告诉缓存同步运行,然而这有需要在内核间进行较慢的缓存一致性协议通信 流处理 流是一系列数据项,一次只生成一项。程序可以从输入流中一个个读取数据项,然后以 相同的方式将数据项写入输出流 拿Linux的管道命令来演示流过程 如上熟悉linux都清楚cat file1 file2会创建两个文件的输出流,如果加上>那么就会生成一个合并了File1和file2的新文件,cat产生的数据流会通过管道传送给tr进行内容过滤,符合条件的又会传入下一个sort方法进行排序,最后sort排序完成的结果集交给tail -3取三行,至此流算是结束了。这些的流处理行为是高效的,因为cat的数据读一条就会传给tr过滤,tr后传入sort,sort就能在cat或tr完成前先处理几行 基于上面的思想,java8引入了Stream,这样的好处是并行能力得到了极大的提升,并且站在了更高的抽象角度去编程,因为原来的编程习惯的java只能利用一个cpu,除非自己去写thread,并且thread是容易出错的 用行为参数化把代码传递给方法 java8可以通过api传递代码。 对上面的解释就是:看到上面的图的sort函数,可能它默认的只能升序或者降序排序,但是如果我们需要定制排序的话,也就只能对sort进行重新定义,那么就比如下面(java代码演示) @Test public void test() throws Exception { List<Integer> ints = Arrays.asList(1,3,4,5,1,5,7,7,8); ints.sort(new Comparator<Integer>() { @Override public int compare(Integer o1, Integer o2) { return o1.compareTo(o2); //升序 } }); System.out.println(ints); ints.sort(new Comparator<Integer>() { @Override public int compare(Integer o1, Integer o2) { return - o1.compareTo(o2); //降序 } }); System.out.println(ints); } 如上的代码,其实是只有renturn...是有用的,这句代码关乎到排序规则,但是其他的代码都是无用的。那么这时候就会想,只需要写一遍匿名内部类,排序逻辑根据自己需要传入不就行了。这个思想就是:通过api传递代码 并行与共享的可变数据 并发和并行的概念 并发是两个任务可以在重叠的时间段内启动,运行和完成。并行是任务在同一时间运行,例如,在多核处理器上。 并发是独立执行过程的组合,而并行是同时执行(可能相关的)计算。 并发是一次处理很多事情,并行是同时做很多事情。 应用程序可以是并发的,但不是并行的,这意味着它可以同时处理多个任务,但是没有两个任务在同一时刻执行。 应用程序可以是并行的,但不是并发的,这意味着它同时处理多核CPU中的任务的多个子任务。 一个应用程序可以即不是并行的,也不是并发的,这意味着它一次一个地处理所有任务。 应用程序可以即是并行的也是并发的,这意味着它同时在多核CPU中同时处理多个任务。 那么在以往的线程编程中,实现并行的前提就是各个副本可以独立工作,如果在多个副本出现了共享的变量或对象,这就行不通了,因为如果出现同时修改共享变量怎么办 java8的流实现比线程更容易,尽量保持流处理过程中,不访问共享的可变变量,这种函数就被称为纯函数,无副作用函数或无状态函数。但是依旧可以使用sync来实现一个可变数据,但是这样就与并行的概念相悖 函数 方法引用 编写一个目录下查询出所有隐藏文件 @Test public void test() throws Exception { File[] files = new File(".").listFiles(new FileFilter() { @Override public boolean accept(File pathname) { return pathname.isHidden(); } }); for (File file : files) { System.out.println(file); } } 如上啰里啰嗦的只是判断 pathname.isHidden(),java8引入之前只能这么写,但是现在可以这样 @Test public void test() throws Exception { File[] files = new File(".").listFiles((File::isHidden)); for (File file : files) { System.out.println("file = " + file); } } 上面是将isHidden方法做为值传入listFIles方法,与用对象引用传递对象相似,在java8里写下File::isHidden的时候,就创建了一个方法引用,然后可以传递这个引用了 lambda匿名函数 比如代码(int x ) -> x+1,代码的意思就是你传入一个2,那么他会返回3,也可以像上面定义一个方法add1,然后class::add1,但是对于简短逻辑明确的代码来说这样更简洁,如果匿名函数有很多行代码,不能一眼看出这个匿名函数是干嘛的,那么就应该把匿名函数抽出来一个方法使用 实例 bean代码 @AllArgsConstructor @NoArgsConstructor @Data public class Apple { private String color; private Integer weight; } java8之前:苹果根据条件过滤:找出绿色苹果 @Test public void test() throws Exception { List<Apple> apples = new ArrayList<>(); for (Apple apple : apples) { if ("green".equals(apple.getColor())){ System.out.println(apple); } } } java8之前:苹果根据条件过滤:找出1000克以上的大苹果 @Test public void test() throws Exception { List<Apple> apples = new ArrayList<>(); for (Apple apple : apples) { if (1000 < apple.getWeight()){ //其他代码与上面都是一直的,无奈的是只能复制黏贴改条件,复制黏贴是为限的,因为如果有一天需要改一个地方,如果忘记了另一处复制的代码,那么就会出错 System.out.println(apple); } } } java8之后 改变Apple类 @AllArgsConstructor @NoArgsConstructor @Data public class Apple { private String color; private Integer weight; public static boolean filterWeight(Apple apple){ return 1000 < apple.getWeight(); } public static boolean filterColor(Apple apple){ return "green".equals(apple.getColor()); } } 增加接口 public interface FindApple<T> { boolean find(T t); } 编写方法测试 @Test public void test() throws Exception { List<Apple> apples = new ArrayList<>(); filterApple(apples,Apple::filterColor); //java8之后:苹果根据条件过滤:找出绿色苹果 filterApple(apples,Apple::filterWeight); //java8之后:苹果根据条件过滤:找出1000克以上的大苹果 } static void filterApple(List<Apple> apples,FindApple<Apple> f){ for (Apple apple : apples) { if (f.find(apple)){ System.out.println(apple); } } } 自己实现方法引用确实有点复杂,首先要为需要过滤的类增加自实现的static方法,然后编写带有测试方法的结果,之后就是编写方法,此方法是可以接收需要测试类内static方法的。 如上方法filterApple中的f.find(apple),都是可以看出来这是在使用接口中的测试方法,但是这个方法没有实现自己的逻辑,所以到这它是不能按照要求过滤apple的,然后在上面junit测试方法中,传入的Apple::filterColor其实就是为接口中的测试方法添加逻辑,使其能按照我们的要求过滤apple 从传递方法到lambda 如上自己实现方法引用那真是脸上心里全都是mmp,为了实现方法引用,我们增加类Apple的方法,增加了接口等,如果java8要真是这样,那么宁可不用,不过java8是解决了这个问题的,他引入了lambda表达式,这时候上面的写法就可以写为 将增加的接口删掉~ 将在Apple内增加的方法删掉~ 编写代码 @Test public void test() throws Exception { List<Apple> apples = new ArrayList<>(); filterApple(apples,(apple -> "green".equals(apple.getColor()))); filterApple(apples,(apple -> (apple.getWeight() > 1000))); } static void filterApple(List<Apple> apples, Predicate<Apple> f){ for (Apple apple : apples) { if (f.test(apple)){ System.out.println(apple); } } } 这时候看到的变化是从原来的FindApple接口改变为了Predicate接口,其实这个接口的定义跟刚才的FIndApple接口内定义是一样一样的,如下 @FunctionalInterface public interface Predicate<T> { boolean test(T t); .... .... } 最大的变化就是我们并没有使用方法引用,而是直接以更直观的方法来过滤apple 流 日常写代码的时候,在java8之前如果要遍历Map中找出map对应key的特定value值,如果更加复杂的类型就需要嵌套循环并且编写出来的代码是一大坨的 void test() throws Exception {Map maps = new HashMap<>();for (Map.Entry integerStringEntry : maps.entrySet()) { if (integerStringEntry.getKey() > 1000) { if (integerStringEntry.getValue().equals("value")){ System.out.println("integerStringEntry = " + integerStringEntry); } } } } Stream api就类似SQL一样的过滤操作,如上的代码可以写为下面这样的 void test() throws Exception {Map maps = new HashMap<>();maps.entrySet().stream() .filter(entry -> entry.getKey() > 1000) .filter(entry -> entry.getValue().equals("value")) .forEach(System.out::println); } Stream 解决了经典的java程序只能利用一个cpu的问题,可以使程序并行执行,如图 - 在两个cpu上筛选数据,分割数据到两个cpu上,如1 - 按条件过滤数据,如2 - 一个cpu会将结果汇总起来,如3 Stream顺序处理 maps.entrySet().stream().... Stream的并行处理 maps.entrySet().parallelStream().... 默认方法 如上已经看到了,在java8中使用集合类都会有stream方法,那么在java8之前是没有这个方法,如果把java7升级到java8,那么多的这个stream方法不就的需要实现吗,那么不就不能向后兼容了吗? 如上的问题全是由接口内的默认方法实现的 默认方法的定义是由default开始的,比如 public interface MyFunction { default boolean test(String str) { return str.equals(".."); } } public class UU implements MyFunction{ public static void main(String[] args) { UU uu = new UU(); System.out.println(uu.test("..")); } } 如上UU类中根本不要实现接口中的test方法就可以使用,当然也可以覆盖实现 public class UU implements MyFunction{ @Override public boolean test(String str) { return "ll".equals(str); } public static void main(String[] args) { UU uu = new UU(); System.out.println(uu.test("..")); } } 这时候实现的逻辑就是子类重写之后的了 我们都知道接口是可以多重实现的,那么如果IA和IB中方法名重复了咋办 public interface MyFunction1 { default boolean test(String str) { return str.equals(".."); } } public interface MyFunction2 { default boolean test(String str) { return str.equals("ll"); } } public class UU implements MyFunction1,MyFunction2{ //exception public static void main(String[] args) { UU uu = new UU(); System.out.println(uu.test("..")); } } 如上当两个接口中的方法名重复了,那么就会出错,解决办法就是重写重复的方法即可,当然方法重载是没有问题的 这就是为什么在更新为java8之后,之前的代码还是可以使用的原因,java8 在Collection接口中加入了stream默认实现了 default Stream<E> stream() { return StreamSupport.stream(spliterator(), false); }