目录
创建RegExp对象
1.使用RegExp的显式构造函数
2.使用RegExp的隐式构造函数,采用纯文本格式
RegExp对象的属性
静态属性:
index属性:
input属性:
lastIndex属性:
lastMath属性:
lastParen属性:
leftContext属性:
rightContext属性:
$1...$9属性:
实例属性:
global属性:
ignoreCase属性:
multiline属性:
source属性:
RegExp对象的方法
1.exec()方法
语法:rgExp.exec(str)
rgExp:
str:
例子:
2.test()方法
语法:rgexp.test(str)
例子:
创建RegExp对象
每一条正则表达式模式对应一个RegExp实例,有两种方式可以创建RegExp对象的实例。
1.使用RegExp的显式构造函数
语法:new RegExp("pattern"[,"flags"]) //即new RegExp(" 模式 "[," 标记 "])
2.使用RegExp的隐式构造函数,采用纯文本格式
语法:/pattern/[flags]
pattern部分为要使用的正则表达式模式文本,是必选项。
flags部分设置正则表达式的标志信息,是可选项。如果设置flags部分,在第一种方式中,以字符串形式存在;在第二种方式中,以文本的形式紧接在最后一个‘/’字符之后。flags可以是一下标志字符的组合。
g是全局标志。如果设置了这个标志,对某个文本执行搜索和替换操作时,将对文本中所有匹配的部分起作用。如果不设置这个标志,则仅搜索和替换最早匹配的文本内容。
i是忽略大小写标志。如果设置了这个标志,进行匹配时将忽略大小写。
m是多行标志。如果不设置这个标志,那么元字符‘^’只与整个被搜索字符串的开始位置相匹配。而元字符‘$’只与整个被搜索字符串的结束位置相匹配。
RegExp对象的属性
RegExp对象的属性分为静态属性和实例属性。
静态属性:
RegExp对象的静态属性包括index、input、lastIndex、lastMath、lastParen、leftContext、rightContext以及$1...$9。
index属性:
是当前表达式模式首次匹配内容的开始位置,从0开始计数。其初始值为-1,每次匹配成功,index属性都会随之改变。
input属性:
返回当前所作用的字符串,可以简写为$_,初始值为空字符串。
lastIndex属性:
是当前表达式模式首次匹配内容中最后一个字符的下 一个位置,从0 开始计数,常被作为继续搜索时的起始位置,初始值为1,表示从起始位置开始搜索,每次成功匹配时,lastIndex属性值都会随之改变。
lastMath属性:
是当前表达式模式的最后一个匹配字符串,可以简写为$&。其初始值为空字符串("")。在每次成功匹配时,lastMatch 属性值都会随之改变。
lastParen属性:
如果表达式模式中有括起来的子匹配,是当前表达式模式中最后的子匹配所匹配到的子字符串,可以简写为$+。其初始值为空字符串("")。每次成功匹配时,lastParen 属性值都会随之改变。
leftContext属性:
是当前表达式模式最后一个匹配字符串左边的所有内容,可以简写为$’(其中'`'为键盘上Esc键下边的反单引号)。初始值为空字符串("")。每次成功匹配时,其属性值都会随之改变。
rightContext属性:
是当前表达式模式最后一个匹配字符串右边的所有内容,可以简写为$’(其中'`'为键盘上Esc键下边的反单引号)。初始值为空字符串("")。每次成功匹配时,其属性值都会随之改变。
$1...$9属性:
这些属性是只读的。如果表达式模式中有括起来的子匹配,$1..$9 属性值分别是第1~9个子匹配所捕获到的内容。如果有超过9个以上的子匹配,$1..$9属性分别对应级后的9个子匹配。在一个表达式模式中,可以指定任意多个带括号的子匹配,但RegExp对象只能存储最后的9个子匹配的结果。在RegExp实例对象的一些方法所返回的结果数组中, 可以获得所有圆括号内的子匹配结果。
实例属性:
RegExp的实例有几个只读的属性,其中global表示是否为全局匹配,ignoreCase 表示是否忽略大小写,mutiline表示是否为多行匹配,source 是正则式的源文本,如“/[ab]/g"”的源文本就是“[ab]"。另外还有“ 个可写的属性是lastIndex, 表示下次执行匹配时的起始位置。下面对这几种属性进行详细说明。
global属性:
返回创建RegExp对象实例时指定的global标志(g) 的状态。如果创建RegExp对象实例时设置了g标志,该属性返回true, 否则返回false,默认值为false.
ignoreCase属性:
返回创建RegExp对象实例时指定的ignoreCase标志(i)的状态。如果创建RegExp对象实例时设置了i标志,该属性返回true,否则返回false,默认值为false.
multiline属性:
返回创建RegExp对象实例时指定的multiline 标志( m)的状态。如果创建RegExp对象实例时设置了m标志,该属性返回tnue,否则返回false, 默认值为false.
source属性:
返回创建RegExp对象实例时指定的表达式文本字符串。
RegExp对象的方法
1.exec()方法
exec()方法用正则表达式模式在字符串中运行查找,并返回包含该查询结果的一个数组。
语法:rgExp.exec(str)
rgExp:
必选项。包含正则表达式模式和可用标志的正则表达式对象。
str:
必选项。要在其中执行查找的Sring对象或字符串文字。如果exec()方法没有找到匹配,则返回null;如果找到匹配,则exec()方法返回一个数组, 并且更新全局RegExp对象的属性,以反映匹配结果。数组的0元素包含了完整的匹配,而第1~n元素中包合的是匹配中出现的任意一个子匹配。这相当于没有设置全局标志(g) 的match()方法。
如果为正则表达式设置了全局标志,exec()方法从以lastIndex的值指示的位置开始查找:如果没有设置全局标志,exec()方法忽略lastIndex的值,从字符串的起始位置开始搜索。
exec()方法返回的数组有3个属性,分别是input、index和lastIndex。input属性包含了整个被查找的字符串。index属性中包含了整个被查找字符串中匹配的子字符串的位置。lastIndex属性包含了匹配中最后一个字符串的下一个位置。
例子:
<script language="JavaScript">
function RegExpTest(){
var src="I'm a good man";
//创建正则表达式模式
var re=/\w+/g;
var arr;
while((arr=re.exec(src))!=null)
{
document.write(arr.index+"-"+arr.lastIndex+arr+"\t");
}
}
document.write(RegExpTest());
</script>
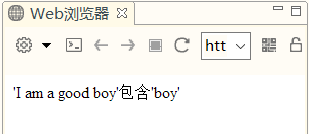
2.test()方法
test()方法返回一个Boolean值,指出在被查找的字符串中是否存在模式。
语法:rgexp.test(str)
例子:
<script language="JavaScript">
function TestDemo(re,s){
var s1; //声明变量
//检查字符串是否存在正则表达式
if(re.test(s)){ //测试是否存在
s1 = "包含"; //s包含模式
}else{
s1="不包含"; //s不包含模式
}
return("'"+s+"'"+s1+"'"+re.source+"'");
}
document.write(TestDemo(/boy/,"I am a good boy"));
</script>
![]()