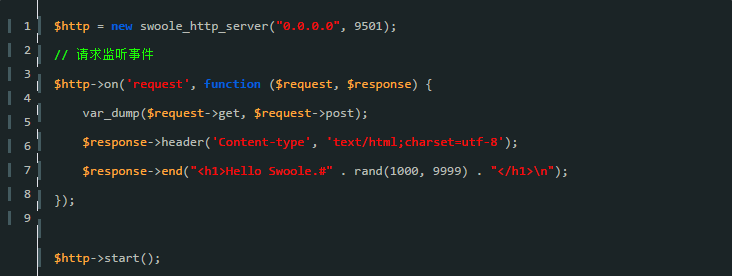
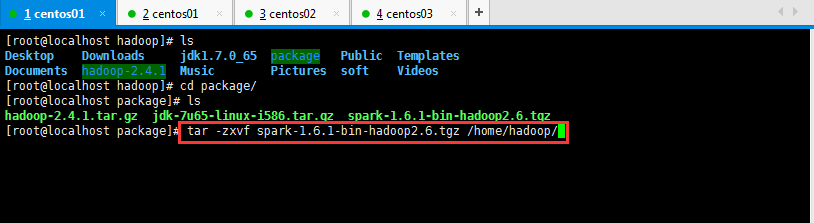
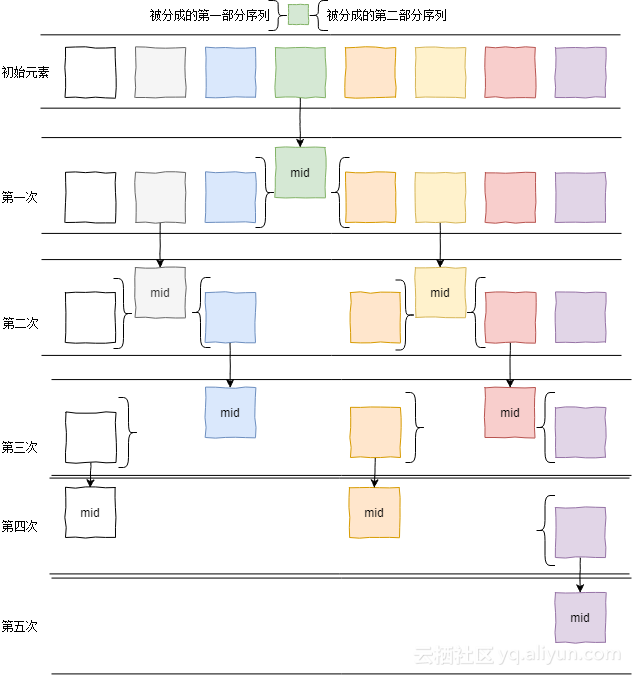
es 入门
**注意事项-------使用ealsticsearch要配置java的开发环境JDK(1.8以上) ealsticsearch: 索引(Index) 类型(type) 文档(Document) 字段(Fields) 关系型数据库: 数据库 表 行 列 from elasticsearch import Elasticsearch 默认host为localhost,port为9200.但也可以指定host与port es = Elasticsearch("http://127.0.0.1:9200") 插入数据,index,doc_type名称可以自定义,id可以根据需求赋值,body为内容 es.index(index="my_index",doc_type="test_type",id=0,body={"name":"python","addr":"深圳"})es.index(index="my_index",doc_type="test_type",id=1,body={"name":"java","addr":"北京"}) 同样是插入数据,create() 方法需要我们指定 id 字段来唯一标识该条数据,而 index() 方法则不需要,如果不指定 id,会自动生成一个 id es.create(index="my_index",doc_type="test_type",id=1,body={"name":"python","addr":"深圳"}) 删除指定的index、type、id的文档 es.delete(index='indexName', doc_type='typeName', id=1) 删除index es.indices.delete(index='news', ignore=[400, 404])query = {'query': {'match_all': {}}}# 查找所有文档query1 = {'query': {'match': {'sex': 'famale'}}}# 删除性别为女性的所有文档query2 = {'query': {'range': {'age': {'lt': 11}}}}# 删除年龄小于11的所有文档query3 = {'query': {'term': {'name': 'jack'}}}# 查找名字叫做jack的所有文档 删除所有文档 es.delete_by_query(index="my_index",doc_type="test_type",body=query) get:获取指定index、type、id所对应的文档 es.get(index="my_index",doc_type="test_type",id=1) search:查询满足条件的所有文档,没有id属性,且index,type和body均可为None result = es.search(index="my_index",doc_type="test_type",body=query)print(result'hits'[0])# 返回第一个文档的内容 update:更新指定index、type、id所对应的文档 更新的主要点: 1. 需要指定 id 2. body={"doc": } , 这个doc是必须的 es.update(index="my_index",doc_type="test_type",id=1,body={"doc":{"name":"python1","addr":"深圳1"}}) ---查询所有数据# 搜索所有数据es.search(index="my_index",doc_type="test_type") 或者 body = { "query":{ "match_all":{} }}es.search(index="my_index",doc_type="test_type",body=body) ---term与terms term body = { "query":{ "term":{ "name":"python" } }} 查询name="python"的所有数据 es.search(index="my_index",doc_type="test_type",body=body) terms body = { "query":{ "terms":{ "name":[ "python","android" ] } }} 搜索出name="python"或name="android"的所有数据 es.search(index="my_index",doc_type="test_type",body=body) ---match与multi_match match:匹配name包含python关键字的数据 body = { "query":{ "match":{ "name":"python" } }} 查询name包含python关键字的数据 es.search(index="my_index",doc_type="test_type",body=body) multi_match:在name和addr里匹配包含深圳关键字的数据 body = { "query":{ "multi_match":{ "query":"深圳", "fields":["name","addr"] } }} 查询name和addr包含"深圳"关键字的数据 es.search(index="my_index",doc_type="test_type",body=body) ---idsbody = { "query":{ "ids":{ "type":"test_type", "values":[ "1","2" ] } }} 搜索出id为1或2d的所有数据 es.search(index="my_index",doc_type="test_type",body=body) ---复合查询boolbody = { "query":{ "bool":{ "must":[ { "term":{ "name":"python" } }, { "term":{ "age":18 } } ] } }} 获取name="python"并且age=18的所有数据 es.search(index="my_index",doc_type="test_type",body=body) ---切片式查询body = { "query":{ "match_all":{} } "from":2 # 从第二条数据开始 "size":4 # 获取4条数据} 从第2条数据开始,获取4条数据 es.search(index="my_index",doc_type="test_type",body=body) ---范围查询 body = { "query":{ "range":{ "age":{ "gte":18, # >=18 "lte":30 # <=30 } } }} 查询18<=age<=30的所有数据 es.search(index="my_index",doc_type="test_type",body=body) ---前缀查询body = { "query":{ "prefix":{ "name":"p" } }} 查询前缀为"赵"的所有数据 es.search(index="my_index",doc_type="test_type",body=body) ---通配符查询 body = { "query":{ "wildcard":{ "name":"*id" } }} 查询name以id为后缀的所有数据 es.search(index="my_index",doc_type="test_type",body=body) ---排序body = { "query":{ "match_all":{} } "sort":{ "age":{ # 根据age字段升序排序 "order":"asc" # asc升序,desc降序 } }} ---filter_path响应过滤 只需要获取_id数据,多个条件用逗号隔开 es.search(index="my_index",doc_type="test_type",filter_path=["hits.hits._id"]) 获取所有数据 es.search(index="my_index",doc_type="test_type",filter_path=["hits.hits._*"]) ---count执行查询并获取该查询的匹配数 获取数据量 es.count(index="my_index",doc_type="test_type") ---度量类聚合获取最小值body = { "query":{ "match_all":{} }, "aggs":{ # 聚合查询 "min_age":{ # 最小值的key "min":{ # 最小 "field":"age" # 查询"age"的最小值 } } }} 搜索所有数据,并获取age最小的值 es.search(index="my_index",doc_type="test_type",body=body) ---获取最大值body = { "query":{ "match_all":{} }, "aggs":{ # 聚合查询 "max_age":{ # 最大值的key "max":{ # 最大 "field":"age" # 查询"age"的最大值 } } }} 搜索所有数据,并获取age最大的值 es.search(index="my_index",doc_type="test_type",body=body) ---获取和body = { "query":{ "match_all":{} }, "aggs":{ # 聚合查询 "sum_age":{ # 和的key "sum":{ # 和 "field":"age" # 获取所有age的和 } } }} 搜索所有数据,并获取所有age的和 es.search(index="my_index",doc_type="test_type",body=body) ---获取平均值body = { "query":{ "match_all":{} }, "aggs":{ # 聚合查询 "avg_age":{ # 平均值的key "sum":{ # 平均值 "field":"age" # 获取所有age的平均值 } } }} 搜索所有数据,获取所有age的平均值 es.search(index="my_index",doc_type="test_type",body=body)