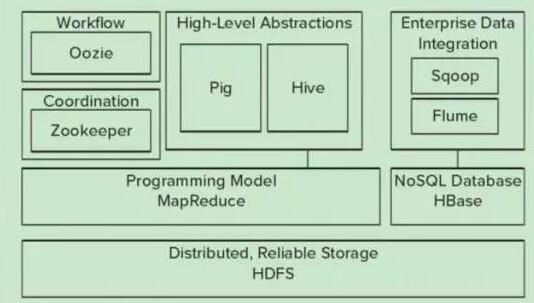
[雪峰磁针石博客]计算机视觉opcencv工具深度学习快速实战2 opencv快速入门
opencv基本操作 # -*- coding: utf-8 -*- # Author: xurongzhong#126.com wechat:pythontesting qq:37391319 # 技术支持 钉钉群:21745728(可以加钉钉pythontesting邀请加入) # qq群:144081101 591302926 567351477 # CreateDate: 2018-11-17 import imutils import cv2 # 读取图片信息 image = cv2.imread("jp.png") (h, w, d) = image.shape print("width={}, height={}, depth={}".format(w, h, d)) # 显示图片 cv2.imshow("Image", image) cv2.waitKey(0) # 访问像素 (B, G, R) = image[100, 50] print("R={}, G={}, B={}".format(R, G, B)) # 选取图片区间 ROI (Region of Interest) roi = image[60:160, 320:420] cv2.imshow("ROI", roi) cv2.waitKey(0) # 缩放 resized = cv2.resize(image, (200, 200)) cv2.imshow("Fixed Resizing", resized) cv2.waitKey(0) # 按比例缩放 r = 300.0 / w dim = (300, int(h * r)) resized = cv2.resize(image, dim) cv2.imshow("Aspect Ratio Resize", resized) cv2.waitKey(0) # 使用imutils缩放 resized = imutils.resize(image, width=300) cv2.imshow("Imutils Resize", resized) cv2.waitKey(0) # 顺时针旋转45度 center = (w // 2, h // 2) M = cv2.getRotationMatrix2D(center, -45, 1.0) rotated = cv2.warpAffine(image, M, (w, h)) cv2.imshow("OpenCV Rotation", rotated) cv2.waitKey(0) # 使用imutils旋转 rotated = imutils.rotate(image, -45) cv2.imshow("Imutils Rotation", rotated) cv2.waitKey(0) # 使用imutils无损旋转 rotated = imutils.rotate_bound(image, 45) cv2.imshow("Imutils Bound Rotation", rotated) cv2.waitKey(0) # apply a Gaussian blur with a 11x11 kernel to the image to smooth it, # useful when reducing high frequency noise 高斯模糊 # https://www.pyimagesearch.com/2016/07/25/convolutions-with-opencv-and-python/ blurred = cv2.GaussianBlur(image, (11, 11), 0) cv2.imshow("Blurred", blurred) cv2.waitKey(0) # 画框 output = image.copy() cv2.rectangle(output, (320, 60), (420, 160), (0, 0, 255), 2) cv2.imshow("Rectangle", output) cv2.waitKey(0) # 画圆 output = image.copy() cv2.circle(output, (300, 150), 20, (255, 0, 0), -1) cv2.imshow("Circle", output) cv2.waitKey(0) # 划线 output = image.copy() cv2.line(output, (60, 20), (400, 200), (0, 0, 255), 5) cv2.imshow("Line", output) cv2.waitKey(0) # 输出文字 output = image.copy() cv2.putText(output, "https://china-testing.github.io", (10, 25), cv2.FONT_HERSHEY_SIMPLEX, 0.7, (0, 255, 0), 2) cv2.imshow("Text", output) cv2.waitKey(0) 原图: 选取图片区间 ROI (Region of Interest) 缩放 按比例缩放 旋转 使用imutils无损旋转 高斯模糊 画框 画圆 划线 输出文字 执行时的输出 $ python opencv_tutorial_01.py width=600, height=322, depth=3 R=41, G=49, B=37 本节英文原版代码下载 关于旋转这块,实际上pillow做的更好。比如同样逆时针旋转90度。 opencv的实现: import imutils import cv2 image = cv2.imread("jp.png") rotated = imutils.rotate(image, 90) cv2.imshow("Imutils Rotation", rotated) cv2.waitKey(0) pillow的实现: from PIL import Image im = Image.open("jp.png") im2 = im.rotate(90, expand=True) im2.show() 更多参考: python库介绍-图像处理工具pillow中文文档-手册(2018 5.*) 参考资料 技术支持qq群144081101(代码和模型存放) 本文最新版本地址 本文涉及的python测试开发库 谢谢点赞! 本文相关海量书籍下载 2018最佳人工智能机器学习工具书及下载(持续更新) 代码下载:https://itbooks.pipipan.com/fs/18113597-320636142 代码github地址:https://github.com/china-testing/python-api-tesing/tree/master/opencv_crash_deep_learning 识别俄罗斯方块 # -*- coding: utf-8 -*- # Author: xurongzhong#126.com wechat:pythontesting qq:37391319 # 技术支持 钉钉群:21745728(可以加钉钉pythontesting邀请加入) # qq群:144081101 591302926 567351477 # CreateDate: 2018-11-19 # python opencv_tutorial_02.py --image tetris_blocks.png import argparse import imutils import cv2 ap = argparse.ArgumentParser() ap.add_argument("-i", "--image", required=True, help="path to input image") args = vars(ap.parse_args()) image = cv2.imread(args["image"]) cv2.imshow("Image", image) cv2.waitKey(0) # 转为灰度图 gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY) cv2.imshow("Gray", gray) cv2.waitKey(0) # 边缘检测 edged = cv2.Canny(gray, 30, 150) cv2.imshow("Edged", edged) cv2.waitKey(0) # 门限 thresh = cv2.threshold(gray, 225, 255, cv2.THRESH_BINARY_INV)[1] cv2.imshow("Thresh", thresh) cv2.waitKey(0) # 发现边缘 cnts = cv2.findContours(thresh.copy(), cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE) cnts = cnts[0] if imutils.is_cv2() else cnts[1] output = image.copy() # loop over the contours for c in cnts: # draw each contour on the output image with a 3px thick purple # outline, then display the output contours one at a time cv2.drawContours(output, [c], -1, (240, 0, 159), 3) cv2.imshow("Contours", output) cv2.waitKey(0) # draw the total number of contours found in purple text = "I found {} objects!".format(len(cnts)) cv2.putText(output, text, (10, 25), cv2.FONT_HERSHEY_SIMPLEX, 0.7, (240, 0, 159), 2) cv2.imshow("Contours", output) cv2.waitKey(0) # we apply erosions to reduce the size of foreground objects mask = thresh.copy() mask = cv2.erode(mask, None, iterations=5) cv2.imshow("Eroded", mask) cv2.waitKey(0) # 扩大 mask = thresh.copy() mask = cv2.dilate(mask, None, iterations=5) cv2.imshow("Dilated", mask) cv2.waitKey(0) # a typical operation we may want to apply is to take our mask and # apply a bitwise AND to our input image, keeping only the masked # regions mask = thresh.copy() output = cv2.bitwise_and(image, image, mask=mask) cv2.imshow("Output", output) cv2.waitKey(0) 原图和灰度图: 边缘检测 门限 轮廓 查找结果 腐蚀和扩张 屏蔽和位操作 串在一起执行 $ python opencv_tutorial_02.py --image tetris_blocks.png