在java.math包中提供了对大数字的操作类,用于进行高精确计算,如BigInteger,BigDecimal类。而平常我们开发中使用最多的float和double只能适用于一般的科学和工程计算,如果要在比较精确的计算方面如货币,那么使用float和double会相应的丢失精度,因此用于精密计算大数字的类BigDecimal就必不可少了。所以BigDecimal适合商业计算场景,用来对超过16位有效位的数进行精确的运算。但是BigDecimal的使用并不像float和double那样,使用不当造成的后果更严重,下面就来看下我们项目中踩过BigDecimal的坑: ![]()
一. BigDecimal的初始化精度丢失问题
先来看下面代码的运行结果:
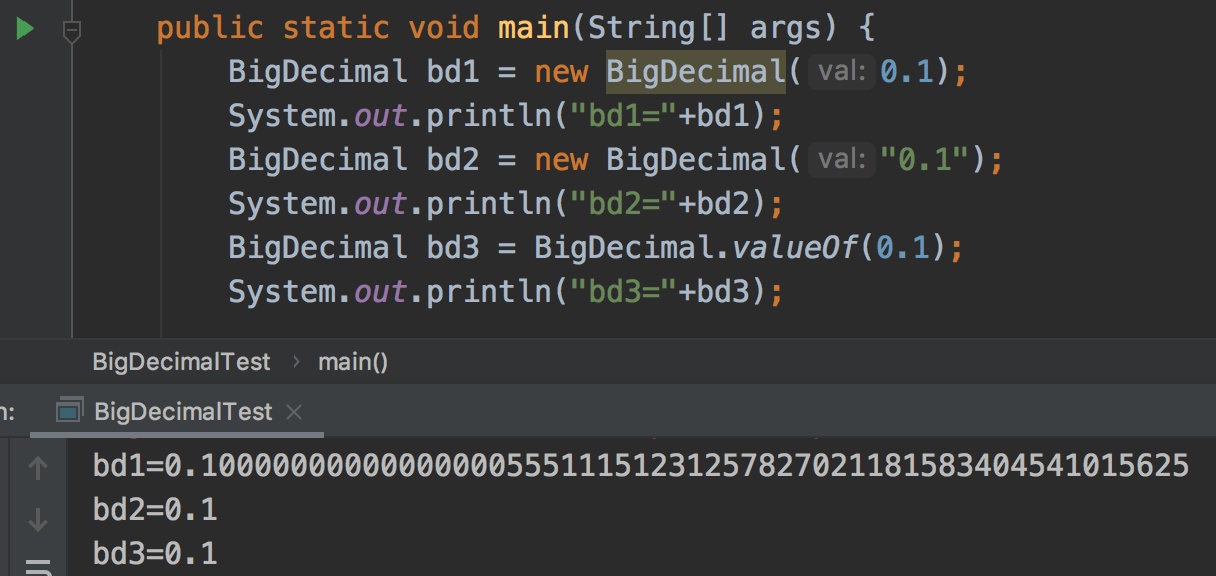
BigDecimal bd1 = new BigDecimal(0.1);
System.out.println("bd1="+bd1);
BigDecimal bd2 = new BigDecimal("0.1");
System.out.println("bd2="+bd2);
BigDecimal bd3 = BigDecimal.valueOf(0.1);
System.out.println("bd3="+bd3);
输出结果:
bd1=0.1000000000000000055511151231257827021181583404541015625
bd2=0.1
bd3=0.1
如果是float或double类型转Bigdecimal,不要使用new BigDecimal()转, 使用valueOf()方法 或new BigDecimal("")转成string,否则有可能出现精度问题。
《Effective Java》这本书里说过:
如果需要精确的答案,请避免使用float和double
因为float和double执行的是二进制浮点运算,二进制有些情况下不能准确的表示一个小数,就像十进制不能准确的表示1/3(1/3=0.3333...)也就是说二进制表示小数的时候只能够表示能够用1/(2^n)的和的任意组合,例如:
但是0.1不能够精确表示,因为它不能够表示成为1/(2^n)的和的形式
System.out.println(0.5*3);
System.out.println(0.1*3);
大家可以本地执行下这两行代码,看下输出结果就知道为什么二进制不能表示0.1却可以表示0.5了。所以其实不是BigDecimal的问题,BigDecimal就是为了满足精确运算存在的,问题出在0.1它本身就一个不准确的值,这其实跟BigDecimal无关,但在使用的时候需要注意用法。
二. BigDecimal在进行除法运算时需设置精度,否则对于除不尽的情况会抛出异常
继续看下面的代码执行结果:
BigDecimal bd4 = new BigDecimal("10");
BigDecimal bd5 = new BigDecimal("3");
System.out.println(bd4.divide(bd5));
输出结果:
Exception in thread "main" java.lang.ArithmeticException: Non-terminating decimal expansion; no exact representable decimal result.
at java.math.BigDecimal.divide(BigDecimal.java:1690)
at BigDecimalTest.main(BigDecimalTest.java:38)
应该向下面这样设置小数点后的位数,以及超出后是四舍五入和向上/向下取整或者直接舍弃:
System.out.println(bd4.divide(bd5,2,BigDecimal.ROUND_DOWN));
第二个参数表示小数位数,第三个参数表示超出的位数直接舍弃(当然也可以设置四舍五入,向上取整等)
三. 不要使用BigDecimal的equals方法比较大小, 否则可能会因为精度问题导致比较结果和预期的不一致
BigDecimal bd1 = new BigDecimal("0");
BigDecimal bd2 = new BigDecimal("0.0");
System.out.println(bd1.equals(bd2));
System.out.println(bd1.[compareTo](http://javakk.com/tag/compareto "查看更多关于 compareTo 的文章")(bd2) == 0)
输出结果:
equals:false
compareTo:true
如果你无法确定你的BigDecimal值有小数情况,最好用compareTo!
文章来源:http://javakk.com/21.html