鸿蒙内核源码注释中文版 【 Gitee仓 | CSDN仓 | Github仓 | Coding仓 】项目中文注解鸿蒙官方内核源码,详细阐述鸿蒙架构和代码设计细节,精读内核源码最大的好处是:将孤立知识点织成一张高浓度,高密度底层网,对计算机体系化理解形成永久记忆,从此高屋建瓴分析/解决问题.
鸿蒙源码分析系列篇 【 CSDN | OSCHINA | WIKI 】从 HarmonyOS 架构层视角整理成文, 并首创用生活场景讲故事的方式试图去解构内核,一窥究竟。
鸿蒙虚拟内存全景图
![]()
再看鸿蒙用户空间全景图
![]()
以上两图是笔者阅读完鸿蒙内核源码内存模块所绘制,给鸿蒙内核源码逐行加上中文注释 【 Gitee仓 | CSDN仓 | Github仓 | Coding仓 】已正式上线,四大码仓每日同步更新。更多图在仓库中用 @note_pic 搜索查看。
内存在内核的比重极大
内存模块占了鸿蒙内核约15%代码量, 近50个文件,非常复杂。想想也是,内存何等重要,内核本身和应用程序一样,也是程序,也要在内存中运行, 大家都在一个窝里吃饭, 你凭什么就管我了, 凭什么的问题会在系列篇的最后结尾 鸿蒙内核源码分析(主奴机制篇) 中详细介绍, 内核就是皇上,应用进程就是奴才。 奴才们被皇上捏的死死的. 按不住这帮奴才那这主子就不合格, 没有稳定的运作系统还谈什么万里江山。 而本篇要说的内存就是紫禁城!请大家试着想想,我们的实际内存就这么点大, 如何满足众多应用程序的需求? 要看抖音,玩微信,逛京东,吃鸡,作为用户巴不得全打开,还要快速响应不能有时延,这些都要在内存中完成,是怎么做到的呢?内核空间和用户空间如何隔离? 如何防止访问乱串? 如何分配如何释放防止碎片化? 空间不够了又如何置换到硬盘? 想想头都大了。内核这当家的主子真是不容易, 这些都是他要解决的问题, 但欲戴其冠,必承其重,没有两把刷子还当什么皇上.
先说如果没有内存管理会怎样?
那就是个奴强主弱的时代!紫禁城乱成一锅粥了。奴才们个个能把主子给活活踩死, 想想主奴不分,吃喝拉撒睡都在一起。称兄道弟,平起平坐能干成个啥? 没规矩不成方圆嘛,这事业肯定搞不大,单片机时代就是这种情况. 裸机编程,指针可以随便乱飞,数据可以随意覆盖,没有划定边界,没有明确职责,没有特权指令,没有地址保护,你还想像java开发一样,只管new内存,不去释放,应用可以随便崩但系统跑的妥妥的?想的美! 直接系统死机,甚至开机都开不了,主板直接报废了. 所以不能运行很复杂的程序,尽量可控,队伍一旦大了就不好带了,方法得换, 游击队的做法不适合规模作战,内存就需要管理了,而且是需要5A级的严格管理。
内存管理在管什么?
简单说就是给主子赋能,拥有超级权利,为什么就他有? 因为他先来,掌握了先机!它定好了游戏规则,你们来玩.那有哪些游戏规则呢?
第一: 主奴有别,主子即是裁判又是运动员,主子有主子地方,奴才们有奴才们待的地方,主子可以在你的空间走来走去,但你只能在主人划定的区域活动.奴才把自己玩崩了也只是奴才狗屁了, 但主人和其他人还会是好好的. 主子有所有特权,比如某个奴才太嚣张了,就直接拖到午门问斩。
第二: 奴奴有分,奴才们基本都是平等的,虽有高级和低级奴才区分,但本质都是奴才。奴才之间是不能随意勾连,登门拜访的,防止一块搞政变. 他们都有属于自己的活动空间,而且活动空间还巨大巨大,大到奴才们觉得整个紫荆城都是他们家的,给你这么大空间你干活才有动力,奴才们是铆足了劲一个个尽情的表演各种剧本,有玩电子商务的,有玩游戏的,有搞直播的等等。。。不愧是紫荆城的主人很有一套,明明只有一个紫禁城,硬被他整出了N个紫荆城的感觉。而且这套管理紫禁城的本领还取了个很好听的名字叫:虚拟内存。
鸿蒙虚拟内存全景图 里面的内核虚拟空间是主人专用的,里面放的是主人的资料,数据,奴才永远进不去,kernel heap 也是给主人专用的动态内存空间,管理奴才和日常运作开销很多时候需要动态申请内存,这个是专门用来提供给主人使用的。而所有奴才的空间都在图中叫用户空间的那一块。您没看错,那就是所有奴才们活动的区域。鸿蒙用户空间全景图 是 鸿蒙虚拟内存全景图 的局部用户空间放大图,里面放的是奴才的私人用品,数据,task运行栈区,动态分配内存的堆区,堆区自下而上,栈区自上而下,中间由 虚拟地址<--->物理地址的映射区隔开,所谓映射区其实就是页表(L1,L2)存放的地方。那么问题来了,这么多奴才都在用户空间区里面不挤吗?答案是:真不挤 。咱皇上是谁啊,那手眼通天了去,因为用了一个好帮手解决了这个问题,这个帮手名叫 MMU(李大总管)
MMU是干什么事的?
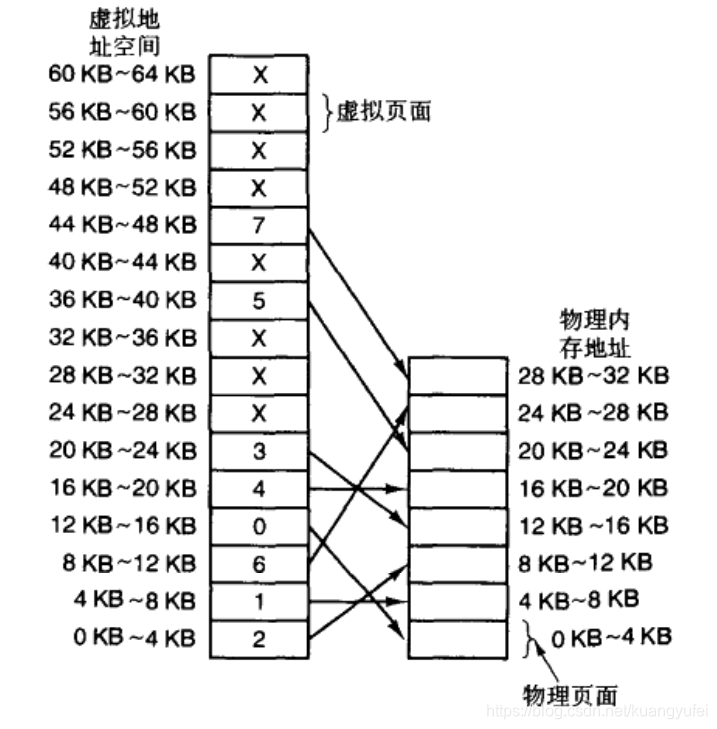
看下某度对MMU定义:它是一种负责处理中央处理器(CPU)的内存访问请求的计算机硬件。它的功能包括虚拟地址到物理地址的转换(即虚拟内存管理)、内存保护、中央处理器高速缓存的控制。通过它的一番操作,把物理空间成倍成倍的放大,他们之间的映射关系存放在页面中。
好像看懂又好像没看懂是吧,到底是干啥的?其实就是个地址映射登记中心。记住这两个字:映射 看下图
![]()
物理内存可以理解为真实世界的紫禁城,虚拟内存就是被MMU虚拟出来的比物理页面大的多的空间。举例说明大概说明下过程:
有A,B,C 三个奴才来到紫禁城,每个人都很有抱负,主子规定要先跑去登记处登记活动范围,领回来一张表 叫 L1页表,上面说了大半个紫禁城你可以跑动,都是你的,L1页表记录你详细了每个房间的编号。其实奴才们的表拿回来的时候内容都一样,能跑的范围也都一样,一开始表上并没什么内容,内容是你在使用过程中慢慢添加上去的。具体怎么添的呢?举例说明:
先说个前提 在CPU单核的情况下同时只能有一个奴才在做事,CPU双核就是两个人奴才做事,其他人都看着他们做事,等待主人叫到自己的号去再去做事。每个人做事之前先把领的表交给地址映射中心的负责人李大总管。
现轮到A奴才了,它负责美食业务的,需要仓库存放肉,菜。仓库向李大总管申请,李大总管同意了,告诉他编号999号仓库给你用,你的东西可以放里面,并在A奴才的表中添加了一条 A | 999 |88 的记录,李大总管自己也有张表,也记录了一条 A|999|88
但实际情况是A不可能一直运行下去,他的工作很可能被打断了,比如皇上想先看直播再吃饭那A就要先停止,让直播的B来工作了。B当然也有张表要交给李大总管并且B要申请个仓库放直播设备,李大总管一看没地方了,怎么办?很简单把自己的表改成了B|777|88,告诉B 777号仓库可以放设备。并在B的表上登记上了 B|777|88
到这里肯定有人问,里面的 88 是什么意思,88就是紫禁城里真实的88号仓库地址,也叫物理地址,999 和 777 都是虚拟出来的,也叫虚拟地址,根本就不存在。李大总管到底是怎么玩出花来的呢?
答案是这样的,当A重新需要把自己编号999号房的菜拿出来切炒时,李大总管拿A的表一看 999号对应的是 88号真实仓库,再看自己的私有表上88对应的是B|777|88, 说明88号已经有B奴才的东西了,怎么办?简单啊,把B奴才的东西移到城外的仓库,再把A数据从城外移到88号房。这样A就拿到了他认为的是在999号房的菜,A全程都不用知道 88号房的存在,它只认999号是我的仓库,里面会有我的菜就行了,记住这是映射的核心机制!!! 这个过程涉及到两个内存概念:缺页中断和页面置换。缺页中断就是88号房被B占了发出一个中断信号,页面置换就是把88号房的东西先搬到城外B的仓库,又从A仓库的菜搬到88号房。李大总管最后又更新下内部表 A|999|88,代表88号仓又给了A奴才用 。明白了吗?李大总管的私人表叫 TLB(translation lookaside buffer)可翻译为“地址转换后缓冲器”,也可简称为“快表”。简单地说,TLB就是页表的Cache ,具体代码可以去 给鸿蒙内核源码逐行加上中文注释 【 Gitee仓 | CSDN仓 | Github仓 | Coding仓 】看代码,里面每一行都加上了中文注释。那奴才们的表存放在哪里呢?还记得上面说的 “所谓映射区其实就是页表(L1,L2)存放的地方”那句话吗?
置换就要有算法,常用的是 LRU(Least recently used,最近最少使用)算法根据数据的历史访问记录来进行淘汰数据,其核心思想是“如果数据最近被访问过,那么将来被访问的几率也更高”。
虚拟内存和物理内存的管理分配方式是不一样的,但都是以页(page)为单位来管理,一页4K字节。
物理内存:段页管理,伙伴算法分配(buddy算法)。LOS_PhysPagesAllocContiguous 这里只到函数级,物理内存的管理和分配不复杂,知道伙伴算法的原理就搞清楚了物理内存的管理。啥是伙伴算法?简单说就是把蛋糕按 2^0,2^1...2^order先切成一块块的, 2^0的统一放一起,2^order的统一放一起,有几个order就用几个链表管理,颗粒粗,分配至少一页起,这句话很重要。
虚拟内存:线性区管理,内存池分配(slab算法)。LOS_MemAlloc 内存池分配,细颗粒分配,从物理内存拿了一页空间,根据需要再割给申请方。
举例说下流程:A用户向虚拟内存申请 1K内存,虚拟内存一看内存池里只有半K(512)了,不够就向物理内存管理方要了一页(4K),再割1K给A。
虚拟内存管理在鸿蒙主要由 VmMapRegion 这个结构体来串联,很复杂,什么红黑树,映射(file,swap),共享内存,访问权限等等都由它来完成。这些在其他篇幅中有详细介绍。
![]()
系列篇文章 进入 >> 鸿蒙系统源码分析(总目录) 【 CSDN | OSCHINA | WIKI 】查看
注释中文版 进入 >> 鸿蒙内核源码注释中文版 【 Gitee仓 | CSDN仓 | Github仓 | Coding仓 】阅读
内容仅代表个人观点,会反复修正,出精品注解,写精品文章,一律原创,转载需注明出处,不修改内容,不乱插广告,错漏之处欢迎指正笔者第一时间加以完善