最近看到了一篇文章,细讲了各种分布式调度原理,其中加权轮询算法(Weighted Round-Robin)应该是离我们最近的一种方式了,Nginx 的 Upstream 就是用的这个算法,这个算法可以根据权重使得每个服务器能够均匀的负载请求,本篇主要就是来总结下使用这个算法以及 Go 内置的方法来实现一个简单的加权轮询的 HTTP 负载分发代理,并对负载分发及路由做一些延伸思考。
本篇主要从以下两个方面进行展开:
- 使用 Go 实现一个反向代理
- 使用 WRR 算法实现此反向代理的加权轮询
什么是代理
代理一般情况下我们是分为正向代理和反向代理两种形式
正向代理一般是配置在客户端,客户端需要知道代理的地址并自行配置
反向代理一般情况下对客户端是透明的,主要是配置在服务器上,大部分我们访问的 Web 应用都是通过反向代理进行配置的,这块主要是 Nginx 和 Apache 提供的功能,比如 Nginx:
location / {
proxy_pass: http://127.0.0.1:3000
}
还有一个简单区分的方式,我们可以看这个代理的作用,如果已知转发的后端,那这个应该是反向代理,如果被转发到哪里去是一个不确定性因素,那这应该是一个正向代理,这是我的个人理解,欢迎读者批评指正 :)
Go ReverseProxy
Go 提供了一个 httputil.ReverseProxy 代理框架,能够让我们快速的实现一个反向代理而无需关注其他细节。
打开reverseproxy.go源码可以看到对 ReverseProxy 的简介
// ReverseProxy is an HTTP Handler that takes an incoming request and
// sends it to another server, proxying the response back to the
// client.
//
// ReverseProxy automatically sets the client IP as the value of the
// X-Forwarded-For header.
// If an X-Forwarded-For header already exists, the client IP is
// appended to the existing values.
// To prevent IP spoofing, be sure to delete any pre-existing
// X-Forwarded-For header coming from the client or
// an untrusted proxy.
ReverseProxy 是一个用来转发请求的服务,并把相关的响应原封不动的返回给客户端,这个过程中 ReverseProxy 会自动给X-Forwarded-For添加或者追加客户端 IP
继续往下看
type ReverseProxy struct {
// Director must be a function which modifies
// the request into a new request to be sent
// using Transport. Its response is then copied
// back to the original client unmodified.
// Director must not access the provided Request
// after returning.
Director func(*http.Request)
// The transport used to perform proxy requests.
// If nil, http.DefaultTransport is used.
Transport http.RoundTripper
...
ReverseProxy 是一个结构体,其中最重要的是 Director,我们需要实现一个 Director 函数,这个函数主要就是让我们可以定义对request的修改,比如修改协议、回源地址、路径等信息,然后传递给http.RoundTripper进行转发,RoundTripper 主要的功能就是返回响应给一个给定的请求,具体可以查看client.go源码,这里不再发散
一个简单的反向代理服务
下面是使用 ReverseProxy 实现的一个简单的反向代理服务:
package main
import (
"fmt"
"net/http"
"net/http/httputil"
"net/url"
)
func main() {
// generateBackend
node := url.URL{Host: "127.0.0.1:7791", Scheme: "http"}
// generate a reverse proxy
reverseProxy := httputil.NewSingleHostReverseProxy(&node)
fmt.Println("Server started on port 7788...")
if err := http.ListenAndServe("127.0.0.1:7788", reverseProxy); err != nil {
fmt.Printf("Server failed to start, error: %s \n", err.Error())
}
}
我们启动此服务,并且使用我自己写的一个testServer.go进行测试
// generate 3 server to handle request for test
package main
import (
"fmt"
"net/http"
)
type testServer struct {
addr string
requestCount int
}
func (server *testServer) handler(res http.ResponseWriter, req *http.Request) {
server.requestCount += 1
fmt.Printf("%s: %s %s on serverHandlerPort: %s, Total: %d\n",
req.Proto, req.Method, req.RequestURI, server.addr, server.requestCount)
res.Write([]byte(server.addr))
}
func main() {
nodeA := testServer{"127.0.0.1:7791", 0}
nodeB := testServer{"127.0.0.1:7792", 0}
nodeC := testServer{"127.0.0.1:7793", 0}
nodes := []testServer{nodeA, nodeB, nodeC}
serverA := http.NewServeMux()
serverA.HandleFunc("/", nodeA.handler)
go http.ListenAndServe(nodeA.addr, serverA)
serverB := http.NewServeMux()
serverB.HandleFunc("/", nodeB.handler)
go http.ListenAndServe(nodeB.addr, serverB)
serverC := http.NewServeMux()
serverC.HandleFunc("/", nodeC.handler)
go http.ListenAndServe(nodeC.addr, serverC)
var comm int
for _, node := range nodes {
fmt.Printf("Server %s started...\n", node.addr)
}
fmt.Println("All server are started, input any key and enter to quit...")
fmt.Scan(&comm)
fmt.Printf("Result: ServerA: %d ServerB: %d ServerC: %d\n",
nodeA.requestCount, nodeB.requestCount, nodeC.requestCount)
}
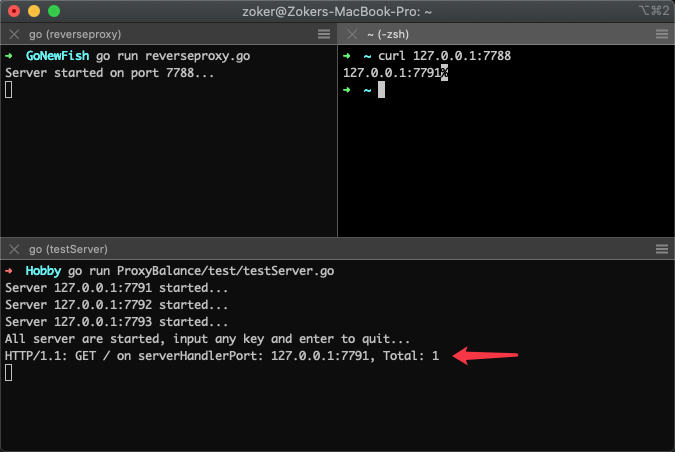
使用命令访问curl 127.0.0.1:7788,可以看到已经将请求转发到后端127.0.0.1:7791了
![]()
以上,我们就已经实现了一个反向代理,用来对请求进行代理,但这并不是我们想要的,我们想要的是分发,所以我们继续改造此脚本,使它能够配置多个后端进行轮询
支持多个后端轮询的反向代理服务
参照源码中NewSingleHostReverseProxy函数自定义即可
package main
import (
"fmt"
"math/rand"
"net/http"
"net/http/httputil"
"net/url"
)
//func NewSingleHostReverseProxy(target *url.URL) *ReverseProxy {
// targetQuery := target.RawQuery
// director := func(req *http.Request) {
// req.URL.Scheme = target.Scheme
// req.URL.Host = target.Host
// req.URL.Path = singleJoiningSlash(target.Path, req.URL.Path)
// if targetQuery == "" || req.URL.RawQuery == "" {
// req.URL.RawQuery = targetQuery + req.URL.RawQuery
// } else {
// req.URL.RawQuery = targetQuery + "&" + req.URL.RawQuery
// }
// if _, ok := req.Header["User-Agent"]; !ok {
// // explicitly disable User-Agent so it's not set to default value
// req.Header.Set("User-Agent", "")
// }
// }
// return &ReverseProxy{Director: director}
//}
// config for backends
var nodes = [] *url.URL{
{Host: "127.0.0.1:7791", Scheme: "http"},
{Host: "127.0.0.1:7792", Scheme: "http"},
{Host: "127.0.0.1:7793", Scheme: "http"},
}
func generateReverseProxy() *httputil.ReverseProxy{
// generate director
director := func(req *http.Request) {
backend := nodes[rand.Int()%len(nodes)]
req.URL.Scheme = backend.Scheme
req.URL.Host = backend.Host
fmt.Printf("Scheme: %s Host: %s Path: %s\n", req.Proto, req.Host, req.RequestURI)
}
return &httputil.ReverseProxy{Director: director}
}
func main() {
// generate a reverse proxy
reverseProxy := generateReverseProxy()
fmt.Println("Server started on port 7788...")
if err := http.ListenAndServe("127.0.0.1:7788", reverseProxy); err != nil {
fmt.Printf("Server failed to start, error: %s \n", err.Error())
}
}
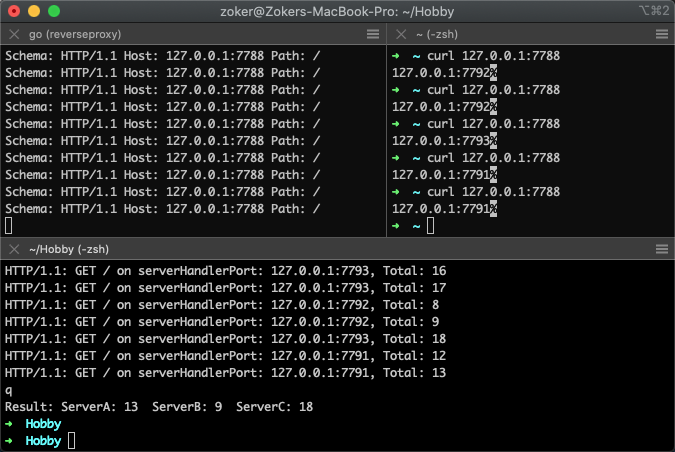
结果如下图
![]()
一共访问40次,分布均匀性一般般,所以接下来就是改造为加权轮询算法进行后端服务器的选择
加权轮询算法(Weighted Round-Robin)
加权轮询算法的实现可以参见 Nginx 的一次代码提交 Upstream: smooth weighted round-robin balancing.
简单来说,Nginx 的这个加权轮询算法不仅仅可以实现按照权重进行分发负载,也实现了平滑性,什么叫平滑呢,就是说你设置了这么一组带权重的后端
{HostA: "127.0.0.1:7791", Weight: 3},
{HostB: "127.0.0.1:7792", Weight: 1},
{HostC: "127.0.0.1:7793", Weight: 1}
比如这时来了5次访问,那么它的分发如果是AAABC,我们就不能说这个是「平滑」的,因为可能会给第一台机器造成压力过大,虽然我们认为它的性能比较好,但是还是会造成同一时间压力过大的问题。而 WRR 算法就可以实现平滑的分发,使分发变成ABACA,避免同一时间造成压力过大的问题,来看看这个算法如何实现的:
For edge case weights like { 5, 1, 1 } we now produce { a, a, b, a, c, a, a }
sequence instead of { c, b, a, a, a, a, a } produced previously.
Algorithm is as follows: on each peer selection we increase current_weight
of each eligible peer by its weight, select peer with greatest current_weight
and reduce its current_weight by total number of weight points distributed
among peers.
In case of { 5, 1, 1 } weights this gives the following sequence of
current_weight's:
a b c
0 0 0 (initial state)
5 1 1 (a selected)
-2 1 1
3 2 2 (a selected)
-4 2 2
1 3 3 (b selected)
1 -4 3
6 -3 4 (a selected)
-1 -3 4
4 -2 5 (c selected)
4 -2 -2
9 -1 -1 (a selected)
2 -1 -1
7 0 0 (a selected)
0 0 0
To preserve weight reduction in case of failures the effective_weight
variable was introduced, which usually matches peer's weight, but is
reduced temporarily on peer failures.
简单来说就是:
- 每一轮选择都用自身的权重加到当前权重
- 当前选中的节点的当前权重需要减去总权重
先来看看算法用 Go 的实现
package main
import "fmt"
type wrrServer struct {
address string
weight int
currentWeight int
}
// nginx weighted round-robin balancing
// view: https://github.com/phusion/nginx/commit/27e94984486058d73157038f7950a0a36ecc6e35
func getBestServer(servers []*wrrServer) (b *wrrServer) {
allWeight := 0
for _, server := range servers {
if server == nil {
return nil
}
allWeight += server.weight // 计算总权重
server.currentWeight += server.weight // 当前权重加上权重
if b == nil || server.currentWeight > b.currentWeight { // 如果最优节点不存在或者当前节点由于最优节点,则赋值或者替换
b = server
}
}
if b == nil {
return nil
}
b.currentWeight -= allWeight
return b
}
func main() {
servers := []*wrrServer{
{"zoker.server.wtm:5555", 5, 0},
{"zoker.server.wtm:2222", 2, 0},
{"zoker.server.wtm:1111", 1, 0},
}
for i := 0; i < 20; i++ {
bestServer := getBestServer(servers)
if bestServer == nil {
continue
}
fmt.Printf("Selected server: %s Weight: %d\n", bestServer.address, bestServer.weight)
}
}
执行结果:
Selected server: zoker.server.wtm:5555 Weight: 5
Selected server: zoker.server.wtm:2222 Weight: 2
Selected server: zoker.server.wtm:5555 Weight: 5
Selected server: zoker.server.wtm:5555 Weight: 5
Selected server: zoker.server.wtm:1111 Weight: 1
Selected server: zoker.server.wtm:5555 Weight: 5
Selected server: zoker.server.wtm:2222 Weight: 2
Selected server: zoker.server.wtm:5555 Weight: 5
Selected server: zoker.server.wtm:5555 Weight: 5
Selected server: zoker.server.wtm:2222 Weight: 2
Selected server: zoker.server.wtm:5555 Weight: 5
Selected server: zoker.server.wtm:5555 Weight: 5
Selected server: zoker.server.wtm:1111 Weight: 1
Selected server: zoker.server.wtm:5555 Weight: 5
Selected server: zoker.server.wtm:2222 Weight: 2
Selected server: zoker.server.wtm:5555 Weight: 5
Selected server: zoker.server.wtm:5555 Weight: 5
Selected server: zoker.server.wtm:2222 Weight: 2
Selected server: zoker.server.wtm:5555 Weight: 5
Selected server: zoker.server.wtm:5555 Weight: 5
可以看到,是比较分散的,也就是我们称之为的「平滑」
实现基于 WRR 的反向代理
了解了加权轮询算法之后,我们来改造上面的分发代理,上面是直接取随机数然后取余来达到随机的效果的,我们来改造 generateReverseProxy()使它能够具备加权分发的能力
package main
import (
"fmt"
"net/http"
"net/http/httputil"
"net/url"
)
type Nodes struct {
node url.URL
weight int
currentWeight int
}
// config backends and weight
var nodes = []*Nodes{
{url.URL{Host: "127.0.0.1:7791", Scheme: "http"}, 5, 0},
{url.URL{Host: "127.0.0.1:7792", Scheme: "http"}, 1, 0},
{url.URL{Host: "127.0.0.1:7793", Scheme: "http"}, 1, 0},
}
// using wrr to select nodes
func getBestNode() (bestNode *Nodes) {
allWeight := 0
for _, node := range nodes {
allWeight += node.weight
node.currentWeight += node.weight
if bestNode == nil || node.currentWeight > bestNode.currentWeight {
bestNode = node
}
}
bestNode.currentWeight -= allWeight
fmt.Printf("Select %s %d %d \n", bestNode.node.Host, bestNode.weight, bestNode.currentWeight)
return bestNode
}
func generateReverseProxy() *httputil.ReverseProxy {
// generate director
director := func(req *http.Request) {
backend := getBestNode().node
req.URL.Scheme = backend.Scheme
req.URL.Host = backend.Host
//fmt.Printf("Scheme: %s Host: %s Path: %s\n", req.Scheme, req.Host, req.RequestURI)
}
return &httputil.ReverseProxy{Director: director}
}
func main() {
// generate a reverse proxy
reverseProxy := generateReverseProxy()
fmt.Println("Server started on port 7788...")
if err := http.ListenAndServe("127.0.0.1:7788", reverseProxy); err != nil {
fmt.Printf("Server failed to start, error: %s \n", err.Error())
}
}
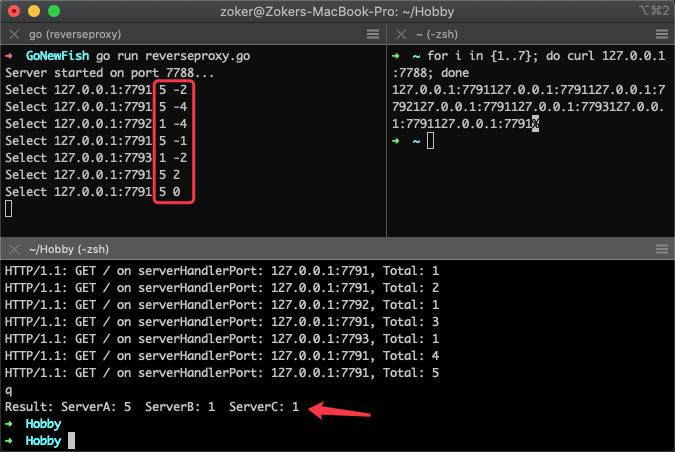
启动服务后,我们模拟7次请求
for i in {1..7}; do curl 127.0.0.1:7788; done
![]()
可以看到7次请求刚好按照权重分布,并且整个过程是按照 WRR 算法均匀分布的。
至此,一个基于加权轮询算法的反向代理就实现了,整个例子还缺少一些错误判定之类的工作,加上之后基本就可以使用了。
进阶思考
上面的例子我们通过修改请求的Scheme和Host来实现分发
req.URL.Scheme = backend.Scheme
req.URL.Host = backend.Host
我们打开url.go查看 URL 结构体的定义
// A URL represents a parsed URL (technically, a URI reference).
//
// The general form represented is:
//
// [scheme:][//[userinfo@]host][/]path[?query][#fragment]
//
// URLs that do not start with a slash after the scheme are interpreted as:
//
// scheme:opaque[?query][#fragment]
//
// Note that the Path field is stored in decoded form: /%47%6f%2f becomes /Go/.
// A consequence is that it is impossible to tell which slashes in the Path were
// slashes in the raw URL and which were %2f. This distinction is rarely important,
// but when it is, the code should use RawPath, an optional field which only gets
// set if the default encoding is different from Path.
//
// URL's String method uses the EscapedPath method to obtain the path. See the
// EscapedPath method for more details.
type URL struct {
Scheme string
Opaque string // encoded opaque data
User *Userinfo // username and password information
Host string // host or host:port
Path string // path (relative paths may omit leading slash)
RawPath string // encoded path hint (see EscapedPath method)
ForceQuery bool // append a query ('?') even if RawQuery is empty
RawQuery string // encoded query values, without '?'
Fragment string // fragment for references, without '#'
}
有这么多属性可以使用,能够带给我们更多的思考:
- 通过请求的 Path 进行逻辑判定,可以指定后端服务器或者进行 URL rewrite (Gitee 就是使用 Path 进行路由的指定和分片的)
- 可以追加 URL RawQuery,比如添加一个
from=xxx,告诉后端,这个请求是从哪个反代发出的
- 根据 User 以及 Path 实现鉴权,可以实现类似网关的功能
- 通过请求的 Host 和 Path 来判定转发到什么目录,可以实现类似于 Gitee Pages 的多租户静态网站功能
- ...
(END)