C++程序设计基础(2)变量
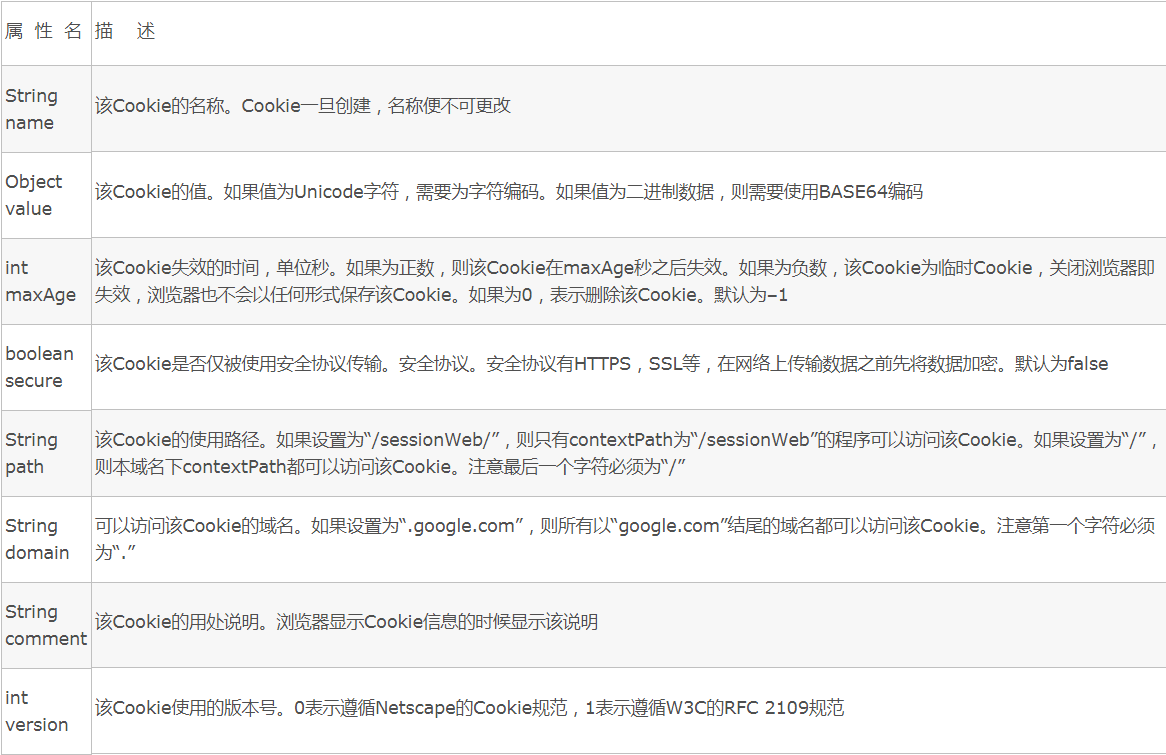
注:读《程序员面试笔记》笔记总结 1.知识点 (1)C++变量命名只能包含字母、数字、下划线,其中开头不能是数字;大小写敏感;习惯上变量用小写字母,常量、宏定义用大写字母。 (2)变量的作用域分为局部变量(函数内部定义),全局变量(函数外部定义)。 (3)关键字extern:在头文件总声明变量,并在前面加上extern,在源文件中定义变量,其他文件使用#include导入头文件,即可使用该变量。附详细链接https://blog.csdn.net/chenqiai0/article/details/8490665 1 //test.h 2 extern int age; 3 //test.cpp 4 #include"test.h" 5 int age = 10; //直接使用age=10是不行的 6 //test1.cpp 7 #include"test.h" 8 int main(int argc, char *argv[]) { 9 cout << age << endl; 10 getchar(); 11 return 0; 12 } 13 14 /*output 15 10 16 */ (4)关键字static:静态变量,首次执行时初始化,其后再执行将不再进行初始化,虽然可能是局部变量,但其生命周期是整个程序运行过程。 (5)关键字const:常量型变量,在头文件中直接定义和声明(不同于一般全局变量),其他文件通过#include使用(多个文件引用不会造成重复定义),如果在源文件中定义,则其作用域值是本源文件。 2.面试题 2.1简述i++和++i的区别 写出下面代码执行后i,j,m,n的值 1 int i=10,j=10; 2 int m=(i++)+(i++)+(i++); 3 int n=(++j)+(++j)+(++j); 知识点:++i是先自身加一,然后再参与赋值运算,i++是先参与赋值运算,然后再自身加一。 本题的特殊之处是不同的编译器会产生不同的结果,在VC编译器中,全部会先完成三个++j,然后再做加法运算,而在gcc编译器中当有两个操作数时就会进行加法运算。故结果如下: 1 #VC编译器 2 i=13,j=13,m=30,n=39;//13+13+13=39 3 #gcc编译器 4 i=13,j=13,m30,n=37; //12+12+13=37 2.2简述C++的类型转换操作符 在C语言中类型转换只需要通过变量前面加上变量类型,并且转换是双向的,这种方式对于简单类型可以,复杂数据类型就力不从心了。 C++提供了四种类型转换操作符:static_cast,dynamic_cast,const_cast,reinterpret_cast。 (1)static_cast可以完全替代C风格类型转换实现基本类型转换; 1 int i = 1; 2 double d = 1.5; 3 int d2i = static_cast<int>(d); 4 double i2d = static_cast<double>(i); 同时相关类(如父子关系)可以完成转换,但是如果父类指针本身指向父类对象,不存在安全问题,如果父类指针本身指向子类对象,则不存在安全问题; 1 class Base {}; 2 class Derived:public Base{}; 3 Base *b1 = new Base; //父类指针指向父类对象 4 Base *b2 = new Derived; //父类指针指向子类对象 5 Derived *b2d1 = static_cast<Derived *>(b1); //转换成功(不安全) 6 Derived *b2d2 = static_cast<Derived *>(b2); //转换成功(安全) (2)dynamic_cast:只能进行对象指针之间的转;转换结果可以使指针也可以是引用;转换时会进行类型检查(static_cast不会进行检查);只有当父类指针指向一个子类对象,并且父类中包含了虚函数,转换才会成功,否则返回空指针,引用的话抛出异常。 1 class Base { virtual void dummy() {}; }; 2 class Drived : public Base{}; 3 Base *b1 = new Base; 4 Base *b2 = new Drived;//父类指针指向子类对象,且父类中包含虚函数 5 //转换结果为指针 6 Drived *b2d1 = dynamic_cast<Drived*>(b1);//转换失败(返回NULL) 7 Drived *b2d2 = dynamic_cast<Drived*>(b2);//转换成功 8 //转换结果为引用 9 Drived &b2d3 = dynamic_cast<Drived &>(*b1);//转换失败(抛出异常) 10 Drived &b2d4 = dynamic_cast<Drived &>(*b2);//转换成功 (3)const_cast:可以在转换过程中增加或删除const属性。一般情况下,无法将常量指针直接赋值给普通指针,但通过const_cast可以移除常量指针的const属性,从而实现const指针到非const指针的转换。 1 class Test{}; 2 const Test *t1 = new Test; 3 Test *t2 = const_cast<Test *>(t1); (4)reinterpret_cast:可以将一种类型的指针直接转换成另一种类型的指针,无论两个类型之间是否有继承关系。此外还可以吧一个指针转换为一个整数,也可以把一个整数转换成一个指针。另外还经常用在不同函数指针之间的转换。 1 class A{}; 2 class B{}; 3 A *a = new A; 4 B *b = reinterpret_cast<B *>(a); //转换成功 2.3简述静态全局变量的概念 (1)在全局变量前面加上static关键字就成为的静态全局变量。 (2)静态全局变量通常在源文件中声明定义,作用域为本文件,(而全局变量一般头文件声明,源文件定义,通过extern关键字,其作用域为整个工程。) (3)如果在头文件中声明了静态全局变量,那么即使在没有初始化的情况下,也会被初始化为默认值,即相当于也被定义了,这时其他文件#include该头文件,相当于拷贝了一份,其初始值相同,后面各个文件中将互相不影响。 下面是静态全局变量的一个例子: 1 static int sgn;//声明定义静态全局变量 2 void increaseSG() { sgn++; } 3 int main(){ 4 sgn = 10; 5 cout << sgn << endl; 6 increaseSG(); 7 cout << sgn << endl; 8 getchar(); 9 return 0; 10 }