K8S自己动手系列 - 1.1 - 集群搭建
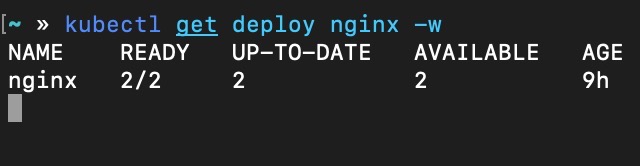
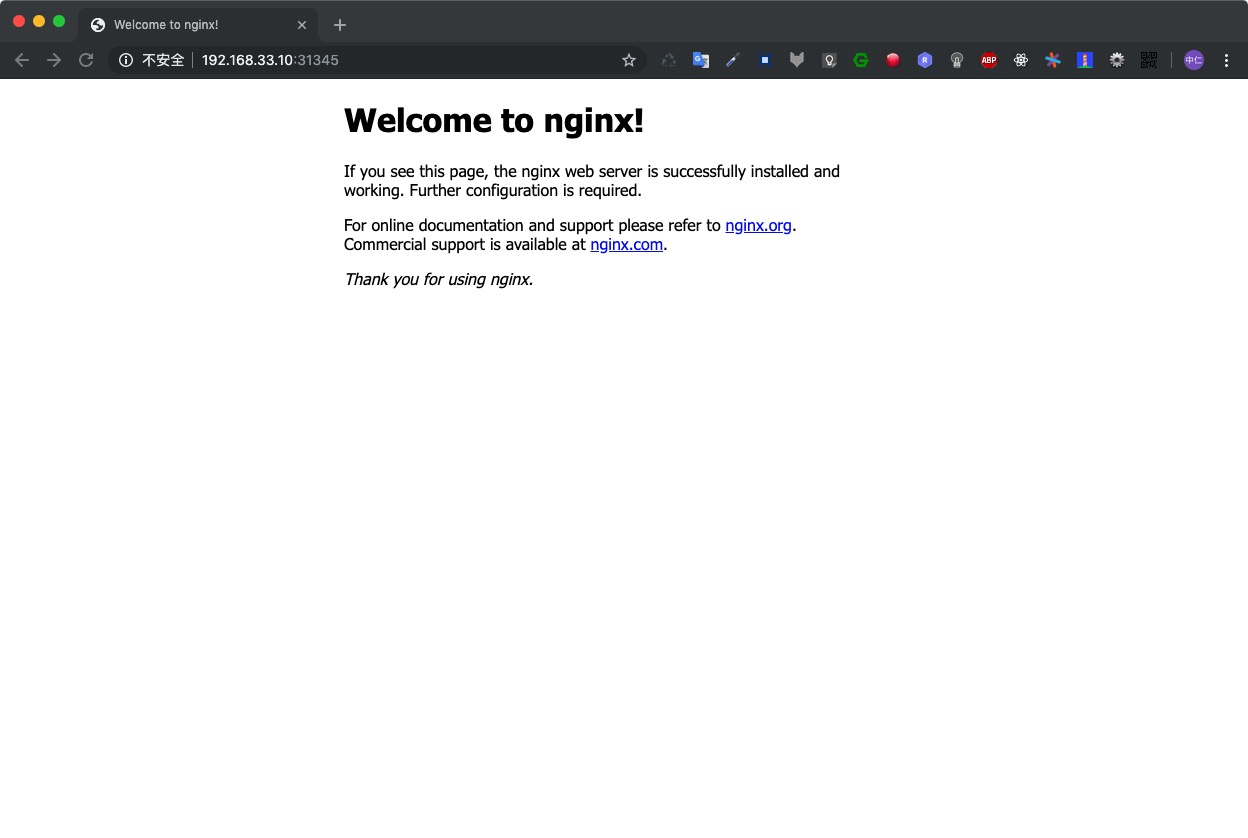
准备 作为学习与实战的记录,笔者计划编写一系列实战系列文章,主要根据实际使用场景选取Kubernetes最常用的功能进行实验,并使用当前最流行的kubeadm安装集群。本文用到的所有实验环境均基于笔者个人工作站虚拟化多个VM而来,如果读者有一台性能尚可的工作站台式机,推荐读者参考本文操作过程实战演练一遍,有助于对Kubernetes各项概念及功能的理解。 前期准备: 两台VM,笔者安装的OS为ubuntu 16.04 保证两台VM网络互通,为了使网络拓扑尽可能简单,我使用的虚拟化软件为VirtualBox,宿主机为ubuntu 19.04,网络模式为Bridge 先解决网络问题 Ubuntu APT https://opsx.alibaba.com/mirror 搜索 ubuntu Kubernetes APT Repo https://opsx.alibaba.com/mirror 搜索 Kubernetes Docker Image Repo # 此过程需要主机先安装好docker-daemon,参考集群安装部分有说明 1. 安装/升级Docker客户端 推荐安装1.10.0以上版本的Docker客户端,参考文档 docker-ce 2. 配置镜像加速器 针对Docker客户端版本大于 1.10.0 的用户 您可以通过修改daemon配置文件/etc/docker/daemon.json来使用加速器 sudo mkdir -p /etc/docker sudo tee /etc/docker/daemon.json <<-'EOF' { "registry-mirrors": ["https://ft3ykfyc.mirror.aliyuncs.com"] } EOF sudo systemctl daemon-reload sudo systemctl restart docker 集群安装 kubelet kubeadm kubectl apt-get update apt-get install -y kubelet kubeadm kubectl docker # 参考 https://kubernetes.io/docs/setup/cri/ # Install Docker CE ## Set up the repository: ### Install packages to allow apt to use a repository over HTTPS apt-get update && apt-get install apt-transport-https ca-certificates curl software-properties-common ### Add Docker’s official GPG key curl -fsSL https://download.docker.com/linux/ubuntu/gpg | apt-key add - ### Add Docker apt repository. add-apt-repository \ "deb [arch=amd64] https://download.docker.com/linux/ubuntu \ $(lsb_release -cs) \ stable" ## Install Docker CE. apt-get update && apt-get install docker-ce=18.06.2~ce~3-0~ubuntu # Setup daemon. cat > /etc/docker/daemon.json <<EOF { "exec-opts": ["native.cgroupdriver=systemd"], "log-driver": "json-file", "log-opts": { "max-size": "100m" }, "storage-driver": "overlay2" } EOF mkdir -p /etc/systemd/system/docker.service.d # Restart docker. systemctl daemon-reload systemctl restart docker 初始化集群 确保swap关闭 swapoff -a vim /etc/fstab ... # comment this #UUID=2746cf1b-d1ab-41e2-8a31-8c1ed2cca910 none swap sw 0 0 kubeadm init ~ kubeadm init --pod-network-cidr=10.244.0.0/16 --kubernetes-version=stable I0608 11:05:15.863459 9577 version.go:96] could not fetch a Kubernetes version from the internet: unable to get URL "https://dl.k8s.io/release/stable.txt": Get https://dl.k8s.io/release/stable.txt: net/http: request canceled while waiting for connection (Client.Timeout exceeded while awaiting headers) I0608 11:05:15.863537 9577 version.go:97] falling back to the local client version: v1.14.3 [init] Using Kubernetes version: v1.14.3 [preflight] Running pre-flight checks [WARNING IsDockerSystemdCheck]: detected "cgroupfs" as the Docker cgroup driver. The recommended driver is "systemd". Please follow the guide at https://kubernetes.io/docs/setup/cri/ [preflight] Pulling images required for setting up a Kubernetes cluster [preflight] This might take a minute or two, depending on the speed of your internet connection [preflight] You can also perform this action in beforehand using 'kubeadm config images pull' 解决镜像拉取问题 上面的拉取特别慢,所以需要从镜像仓库手工拉取镜像,并打tag替代从官方库拉取 # 查看使用到的镜像 ~ kubeadm config images list k8s.gcr.io/kube-apiserver:v1.14.3 k8s.gcr.io/kube-controller-manager:v1.14.3 k8s.gcr.io/kube-scheduler:v1.14.3 k8s.gcr.io/kube-proxy:v1.14.3 k8s.gcr.io/pause:3.1 k8s.gcr.io/etcd:3.3.10 k8s.gcr.io/coredns:1.3.1 # 手工拉取镜像 docker pull docker.io/mirrorgooglecontainers/kube-apiserver:v1.14.3 docker pull docker.io/mirrorgooglecontainers/kube-controller-manager:v1.14.3 docker pull docker.io/mirrorgooglecontainers/kube-scheduler:v1.14.3 docker pull docker.io/mirrorgooglecontainers/kube-proxy:v1.14.3 docker pull docker.io/mirrorgooglecontainers/pause:3.1 docker pull docker.io/mirrorgooglecontainers/etcd:3.3.10 docker pull docker.io/coredns/coredns:1.3.1 # 手工打tag docker tag docker.io/mirrorgooglecontainers/kube-apiserver:v1.14.3 k8s.gcr.io/kube-apiserver:v1.14.3 docker tag docker.io/mirrorgooglecontainers/kube-controller-manager:v1.14.3 k8s.gcr.io/kube-controller-manager:v1.14.3 docker tag docker.io/mirrorgooglecontainers/kube-scheduler:v1.14.3 k8s.gcr.io/kube-scheduler:v1.14.3 docker tag docker.io/mirrorgooglecontainers/kube-proxy:v1.14.3 k8s.gcr.io/kube-proxy:v1.14.3 docker tag docker.io/mirrorgooglecontainers/pause:3.1 k8s.gcr.io/pause:3.1 docker tag docker.io/mirrorgooglecontainers/etcd:3.3.10 k8s.gcr.io/etcd:3.3.10 docker tag docker.io/coredns/coredns:1.3.1 k8s.gcr.io/coredns:1.3.1 再次执行,终于创建成功,输出如下: ~ kubeadm init --pod-network-cidr=10.244.0.0/16 --kubernetes-version=stable [init] Using Kubernetes version: v1.14.3 [preflight] Running pre-flight checks [WARNING IsDockerSystemdCheck]: detected "cgroupfs" as the Docker cgroup driver. The recommended driver is "systemd". Please follow the guide at https://kubernetes.io/docs/setup/cri/ [preflight] Pulling images required for setting up a Kubernetes cluster [preflight] This might take a minute or two, depending on the speed of your internet connection [preflight] You can also perform this action in beforehand using 'kubeadm config images pull' [kubelet-start] Writing kubelet environment file with flags to file "/var/lib/kubelet/kubeadm-flags.env" [kubelet-start] Writing kubelet configuration to file "/var/lib/kubelet/config.yaml" [kubelet-start] Activating the kubelet service [certs] Using certificateDir folder "/etc/kubernetes/pki" [certs] Generating "etcd/ca" certificate and key [certs] Generating "etcd/server" certificate and key [certs] etcd/server serving cert is signed for DNS names [worker01 localhost] and IPs [192.168.101.113 127.0.0.1 ::1] [certs] Generating "etcd/peer" certificate and key [certs] etcd/peer serving cert is signed for DNS names [worker01 localhost] and IPs [192.168.101.113 127.0.0.1 ::1] [certs] Generating "apiserver-etcd-client" certificate and key [certs] Generating "etcd/healthcheck-client" certificate and key [certs] Generating "ca" certificate and key [certs] Generating "apiserver" certificate and key [certs] apiserver serving cert is signed for DNS names [worker01 kubernetes kubernetes.default kubernetes.default.svc kubernetes.default.svc.cluster.local] and IPs [10.96.0.1 192.168.101.113] [certs] Generating "apiserver-kubelet-client" certificate and key [certs] Generating "front-proxy-ca" certificate and key [certs] Generating "front-proxy-client" certificate and key [certs] Generating "sa" key and public key [kubeconfig] Using kubeconfig folder "/etc/kubernetes" [kubeconfig] Writing "admin.conf" kubeconfig file [kubeconfig] Writing "kubelet.conf" kubeconfig file [kubeconfig] Writing "controller-manager.conf" kubeconfig file [kubeconfig] Writing "scheduler.conf" kubeconfig file [control-plane] Using manifest folder "/etc/kubernetes/manifests" [control-plane] Creating static Pod manifest for "kube-apiserver" [control-plane] Creating static Pod manifest for "kube-controller-manager" [control-plane] Creating static Pod manifest for "kube-scheduler" [etcd] Creating static Pod manifest for local etcd in "/etc/kubernetes/manifests" [wait-control-plane] Waiting for the kubelet to boot up the control plane as static Pods from directory "/etc/kubernetes/manifests". This can take up to 4m0s [apiclient] All control plane components are healthy after 18.005322 seconds [upload-config] storing the configuration used in ConfigMap "kubeadm-config" in the "kube-system" Namespace [kubelet] Creating a ConfigMap "kubelet-config-1.14" in namespace kube-system with the configuration for the kubelets in the cluster [upload-certs] Skipping phase. Please see --experimental-upload-certs [mark-control-plane] Marking the node worker01 as control-plane by adding the label "node-role.kubernetes.io/master=''" [mark-control-plane] Marking the node worker01 as control-plane by adding the taints [node-role.kubernetes.io/master:NoSchedule] [bootstrap-token] Using token: ss6flg.csw4u0ok134n2fy1 [bootstrap-token] Configuring bootstrap tokens, cluster-info ConfigMap, RBAC Roles [bootstrap-token] configured RBAC rules to allow Node Bootstrap tokens to post CSRs in order for nodes to get long term certificate credentials [bootstrap-token] configured RBAC rules to allow the csrapprover controller automatically approve CSRs from a Node Bootstrap Token [bootstrap-token] configured RBAC rules to allow certificate rotation for all node client certificates in the cluster [bootstrap-token] creating the "cluster-info" ConfigMap in the "kube-public" namespace [addons] Applied essential addon: CoreDNS [addons] Applied essential addon: kube-proxy Your Kubernetes control-plane has initialized successfully! To start using your cluster, you need to run the following as a regular user: mkdir -p $HOME/.kube sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config sudo chown $(id -u):$(id -g) $HOME/.kube/config You should now deploy a pod network to the cluster. Run "kubectl apply -f [podnetwork].yaml" with one of the options listed at: https://kubernetes.io/docs/concepts/cluster-administration/addons/ Then you can join any number of worker nodes by running the following on each as root: kubeadm join 192.168.101.113:6443 --token ss6flg.csw4u0ok134n2fy1 \ --discovery-token-ca-cert-hash sha256:bac9a150228342b7cdedf39124ef2108653db1f083e9f547d251e08f03c41945 安装网络插件 For flannel to work correctly, you must pass --pod-network-cidr=10.244.0.0/16 to kubeadm init. Set /proc/sys/net/bridge/bridge-nf-call-iptables to 1 by running sysctl net.bridge.bridge-nf-call-iptables=1 to pass bridged IPv4 traffic to iptables’ chains. This is a requirement for some CNI plugins to work, for more information please see here. Make sure that your firewall rules allow UDP ports 8285 and 8472 traffic for all hosts participating in the overlay network. see here . Note that flannel works on amd64, arm, arm64, ppc64le and s390x under Linux. Windows (amd64) is claimed as supported in v0.11.0 but the usage is undocumented. kubectl apply -f https://raw.githubusercontent.com/coreos/flannel/62e44c867a2846fefb68bd5f178daf4da3095ccb/Documentation/kube-flannel.yml For more information about flannel, see the CoreOS flannel repository on GitHub . 安装完成后,查看所有组件已经成功运行 ~ kubectl get all --all-namespaces NAMESPACE NAME READY STATUS RESTARTS AGE kube-system pod/coredns-fb8b8dccf-vmdsj 1/1 Running 0 24m kube-system pod/coredns-fb8b8dccf-xrhrs 1/1 Running 0 24m kube-system pod/etcd-worker01 1/1 Running 0 23m kube-system pod/kube-apiserver-worker01 1/1 Running 0 23m kube-system pod/kube-controller-manager-worker01 1/1 Running 0 23m kube-system pod/kube-flannel-ds-amd64-cgnnz 1/1 Running 0 4m18s kube-system pod/kube-proxy-vfvkp 1/1 Running 0 24m kube-system pod/kube-scheduler-worker01 1/1 Running 0 23m NAMESPACE NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE default service/kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 24m kube-system service/kube-dns ClusterIP 10.96.0.10 <none> 53/UDP,53/TCP,9153/TCP 24m NAMESPACE NAME DESIRED CURRENT READY UP-TO-DATE AVAILABLE NODE SELECTOR AGE kube-system daemonset.apps/kube-flannel-ds-amd64 1 1 1 1 1 beta.kubernetes.io/arch=amd64 4m18s kube-system daemonset.apps/kube-flannel-ds-arm 0 0 0 0 0 beta.kubernetes.io/arch=arm 4m18s kube-system daemonset.apps/kube-flannel-ds-arm64 0 0 0 0 0 beta.kubernetes.io/arch=arm64 4m18s kube-system daemonset.apps/kube-flannel-ds-ppc64le 0 0 0 0 0 beta.kubernetes.io/arch=ppc64le 4m18s kube-system daemonset.apps/kube-flannel-ds-s390x 0 0 0 0 0 beta.kubernetes.io/arch=s390x 4m18s kube-system daemonset.apps/kube-proxy 1 1 1 1 1 <none> 24m NAMESPACE NAME READY UP-TO-DATE AVAILABLE AGE kube-system deployment.apps/coredns 2/2 2 2 24m NAMESPACE NAME DESIRED CURRENT READY AGE kube-system replicaset.apps/coredns-fb8b8dccf 2 2 2 24m run a demo pod ~ kubectl create deployment nginx --image=nginx deployment.apps/nginx created ~ kubectl get deploy NAME READY UP-TO-DATE AVAILABLE AGE nginx 0/1 1 0 9s ~ kubectl get pod NAME READY STATUS RESTARTS AGE nginx-65f88748fd-95gkh 0/1 Pending 0 21s ~ kubectl describe pod/nginx-65f88748fd-95gkh Name: nginx-65f88748fd-95gkh Namespace: default Priority: 0 PriorityClassName: <none> Node: <none> Labels: app=nginx pod-template-hash=65f88748fd Annotations: <none> Status: Pending IP: Controlled By: ReplicaSet/nginx-65f88748fd Containers: nginx: Image: nginx Port: <none> Host Port: <none> Environment: <none> Mounts: /var/run/secrets/kubernetes.io/serviceaccount from default-token-5kf45 (ro) Conditions: Type Status PodScheduled False Volumes: default-token-5kf45: Type: Secret (a volume populated by a Secret) SecretName: default-token-5kf45 Optional: false QoS Class: BestEffort Node-Selectors: <none> Tolerations: node.kubernetes.io/not-ready:NoExecute for 300s node.kubernetes.io/unreachable:NoExecute for 300s Events: Type Reason Age From Message ---- ------ ---- ---- ------- Warning FailedScheduling 30s default-scheduler 0/1 nodes are available: 1 node(s) had taints that the pod didn't tolerate. 查看错误原因,写的很清楚,没有可用节点,是因为我们唯一的一个节点worker01是master节点,master节点默认含有taint(污点),默认不可以调度业务pod,我们来去除这个污点,让nginx可以调度上去 ~ kubectl describe node worker01 Name: worker01 Roles: master Labels: beta.kubernetes.io/arch=amd64 beta.kubernetes.io/os=linux kubernetes.io/arch=amd64 kubernetes.io/hostname=worker01 kubernetes.io/os=linux node-role.kubernetes.io/master= Annotations: flannel.alpha.coreos.com/backend-data: {"VtepMAC":"86:f6:8f:29:d7:c7"} flannel.alpha.coreos.com/backend-type: vxlan flannel.alpha.coreos.com/kube-subnet-manager: true flannel.alpha.coreos.com/public-ip: 192.168.101.113 kubeadm.alpha.kubernetes.io/cri-socket: /var/run/dockershim.sock node.alpha.kubernetes.io/ttl: 0 volumes.kubernetes.io/controller-managed-attach-detach: true CreationTimestamp: Sat, 08 Jun 2019 11:56:28 +0800 Taints: node-role.kubernetes.io/master:NoSchedule ... ~ kubectl taint nodes --all node-role.kubernetes.io/master- node/worker01 untainted ~ kubectl get pod -o wide NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES nginx-65f88748fd-95gkh 1/1 Running 0 4m11s 10.244.0.4 worker01 <none> <none> 可以看到pod已经是running状态了,测试一下 ~ curl 10.244.0.4 <!DOCTYPE html> <html> <head> <title>Welcome to nginx!</title> <style> body { width: 35em; margin: 0 auto; font-family: Tahoma, Verdana, Arial, sans-serif; } </style> </head> <body> <h1>Welcome to nginx!</h1> <p>If you see this page, the nginx web server is successfully installed and working. Further configuration is required.</p> <p>For online documentation and support please refer to <a href="http://nginx.org/">nginx.org</a>.<br/> Commercial support is available at <a href="http://nginx.com/">nginx.com</a>.</p> <p><em>Thank you for using nginx.</em></p> </body> </html> 成功!! 加入节点 在worker02上,执行: ~ kubeadm join 192.168.101.113:6443 --token ss6flg.csw4u0ok134n2fy1 \ --discovery-token-ca-cert-hash sha256:bac9a150228342b7cdedf39124ef2108653db1f083e9f547d251e08f03c41945 [preflight] Running pre-flight checks [WARNING IsDockerSystemdCheck]: detected "cgroupfs" as the Docker cgroup driver. The recommended driver is "systemd". Please follow the guide at https://kubernetes.io/docs/setup/cri/ [preflight] Reading configuration from the cluster... [preflight] FYI: You can look at this config file with 'kubectl -n kube-system get cm kubeadm-config -oyaml' [kubelet-start] Downloading configuration for the kubelet from the "kubelet-config-1.14" ConfigMap in the kube-system namespace [kubelet-start] Writing kubelet configuration to file "/var/lib/kubelet/config.yaml" [kubelet-start] Writing kubelet environment file with flags to file "/var/lib/kubelet/kubeadm-flags.env" [kubelet-start] Activating the kubelet service [kubelet-start] Waiting for the kubelet to perform the TLS Bootstrap... This node has joined the cluster: * Certificate signing request was sent to apiserver and a response was received. * The Kubelet was informed of the new secure connection details. Run 'kubectl get nodes' on the control-plane to see this node join the cluster. 查看 ~ kubectl get nodes NAME STATUS ROLES AGE VERSION worker01 Ready master 52m v1.14.3 worker02 Ready <none> 7m12s v1.14.3 将demo的replica设置为2 ~ kubectl scale deployment.v1.apps/nginx --replicas=2 deployment.apps/nginx scaled ~ kubectl get pod -o wide NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES nginx-7cffb9df96-8n884 1/1 Running 0 5m2s 10.244.0.6 worker01 <none> <none> nginx-7cffb9df96-rbvsr 1/1 Running 0 3s 10.244.1.10 worker02 <none> <none> ~ http 10.244.1.10 HTTP/1.1 200 OK Accept-Ranges: bytes Connection: keep-alive Content-Length: 612 Content-Type: text/html Date: Sat, 08 Jun 2019 05:03:57 GMT ETag: "5ce409fd-264" Last-Modified: Tue, 21 May 2019 14:23:57 GMT Server: nginx/1.17.0 <!DOCTYPE html> <html> <head> <title>Welcome to nginx!</title> <style> body { width: 35em; margin: 0 auto; font-family: Tahoma, Verdana, Arial, sans-serif; } </style> </head> <body> <h1>Welcome to nginx!</h1> <p>If you see this page, the nginx web server is successfully installed and working. Further configuration is required.</p> <p>For online documentation and support please refer to <a href="http://nginx.org/">nginx.org</a>.<br/> Commercial support is available at <a href="http://nginx.com/">nginx.com</a>.</p> <p><em>Thank you for using nginx.</em></p> </body> </html> 成功!至此我们安装好了两个节点的集群,并基于Flannel网络插件的方式,网络模式为VXLAN