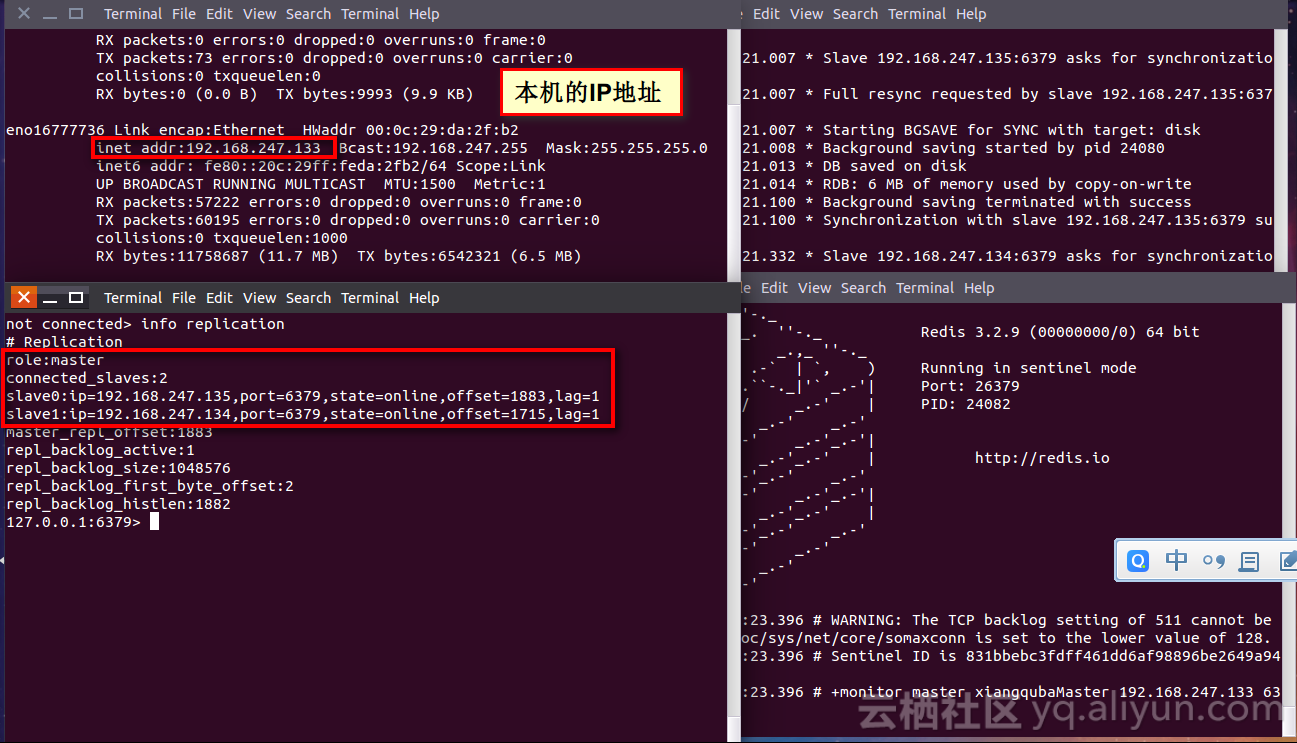
Hadoop,HBase集群环境搭建的问题集锦(四)
21.Schema.xml和solrconfig.xml配置文件里參数说明: 參考资料:http://www.hipony.com/post-610.html 22.执行时报错: 23., /commons-cloud/src/main/resources/testClientUtil.properties 中配置的什么? 在ws-cloud中也有个 答: 好像是mysql的server, 如今预计没用了 24.在ws-cloud项目中 192.168.101.153 这又是干嘛的机器? 答: 这台机器是给定了mavens获取所须要的jar包的仓库信息 25.搭好hbase solr后台环境, 配置好相关文件, 开发机器上tomcatserver执行web-cloud和ws-cloud项目, 用maoqiang/hanwang账号登陆后, 到摘抄页面, 点击”添加”button, 想添加一个摘抄文件. Eclipse下报出例如以下信息: ====================ENTER==================input:{“uid”:”95841248414524”,”sid”:”11111111111”,”ver”:”1.0.0”,”userid”:”maoqiang”,”devid”:”hwa30_12345678”,”ftype”:”0”,”sort”:{“accessTime”:”desc”},”start”:”“,”count”:”10”,”fuid”:”“,”title”:”\u6211\u662f\u8c01”,”summary”:”\u6211\u662f\u8c01”,”content”:”\u6211\u662f\u8c01”,”serVer”:”“,”qstr”:{“start”:”“,”end”:”“,”month”:”“,”title”:”“,”cnt”:”“}} 2015-05-20 16:03:19,353 WARN [http-8080-1] (HConnectionManager.java:1098) - Encountered problems when prefetch hbase:meta table: org.apache.hadoop.hbase.TableNotFoundException: Cannot find row in hbase:meta for table: fileInfo, row=fileInfo,,99999999999999 at org.apache.hadoop.hbase.client.MetaScanner.metaScan(MetaScanner.java:146) at org.apache.hadoop.hbase.client.HConnectionManagerHConnectionImplementation.prefetchRegionCache(HConnectionManager.java:1095)atorg.apache.hadoop.hbase.client.HConnectionManagerHConnectionImplementation.locateRegionInMeta(HConnectionManager.java:1155) … at java.lang.Thread.run(Thread.java:744) 2015-05-20 16:03:19,360 INFO [http-8080-1] (AuthorizeFilter.java:215) - KEY:null—URL:http://localhost:8080/ws-epen/rt/ap/v1/user/listaxis—TIME:21 我想到了hbase内也许应该建好对应的rowkey和列族等信息. 是的, 确实是这么回事, 创建好了hbase的表就好了. 26.关于Mybatis的一条信息, 怎么破? 解决的方法:( 暂未解决,下面是參考解决的方法, ) 在集成Spring + mybaits时出现下面警告org.mybatis.spring.mapper.MapperScannerConfigurer$Scanner.main No MyBatis mapper was found in ‘com.***.dao.impl’ package. Please check your configuration. 出现以上情况是由于你的配置文件写多了这一段, [java] view plaincopyprint?<bean class="org.mybatis.spring.mapper.MapperScannerConfigurer"> <property name="basePackage" value="com.lanyuan.dao.impl" /> </bean> 亲爱吊丝们。把它删除吧。 原因:是org.mybatis.spring.mapper.MapperScannerConfigurer是扫描仓储类的接口,我不是用接口方式实现管理的.所把那段删除便可。 本文转自mfrbuaa博客园博客,原文链接:http://www.cnblogs.com/mfrbuaa/p/5258384.html,如需转载请自行联系原作者